对比学习如何用"比较"重构神经网络的表示能力
2018年,OpenAI的研究员Alec Radford正在思考一个问题:如何让神经网络理解图像和文本之间的关系,而不需要人工标注的百万级训练数据?传统的监督学习范式需要告诉模型"这是一只猫"、“那是一辆车”,但人类学习概念的方式似乎并非如此。我们通过比较和对比来理解世界——知道什么相似,什么不同,什么属于同一类别,什么截然相反。 ...
2018年,OpenAI的研究员Alec Radford正在思考一个问题:如何让神经网络理解图像和文本之间的关系,而不需要人工标注的百万级训练数据?传统的监督学习范式需要告诉模型"这是一只猫"、“那是一辆车”,但人类学习概念的方式似乎并非如此。我们通过比较和对比来理解世界——知道什么相似,什么不同,什么属于同一类别,什么截然相反。 ...
在深度学习的实践中,有一个现象困扰着无数从业者:当训练数据有限时,模型往往能轻松记住训练集,却在新数据上表现糟糕。这种过拟合问题催生了各种解决方案——正则化、Dropout、早停,但最简单有效的方法之一常常被忽视:直接制造更多数据。数据增强(Data Augmentation)正是这样一种看似朴素却蕴含深刻原理的技术。它通过对现有样本施加变换来生成新的训练样本,在不采集额外数据的情况下扩充训练集。但为什么简单的旋转、翻转或同义词替换就能显著提升模型泛化能力?这个问题的答案涉及统计学、优化理论和几何学习的深层原理。 ...
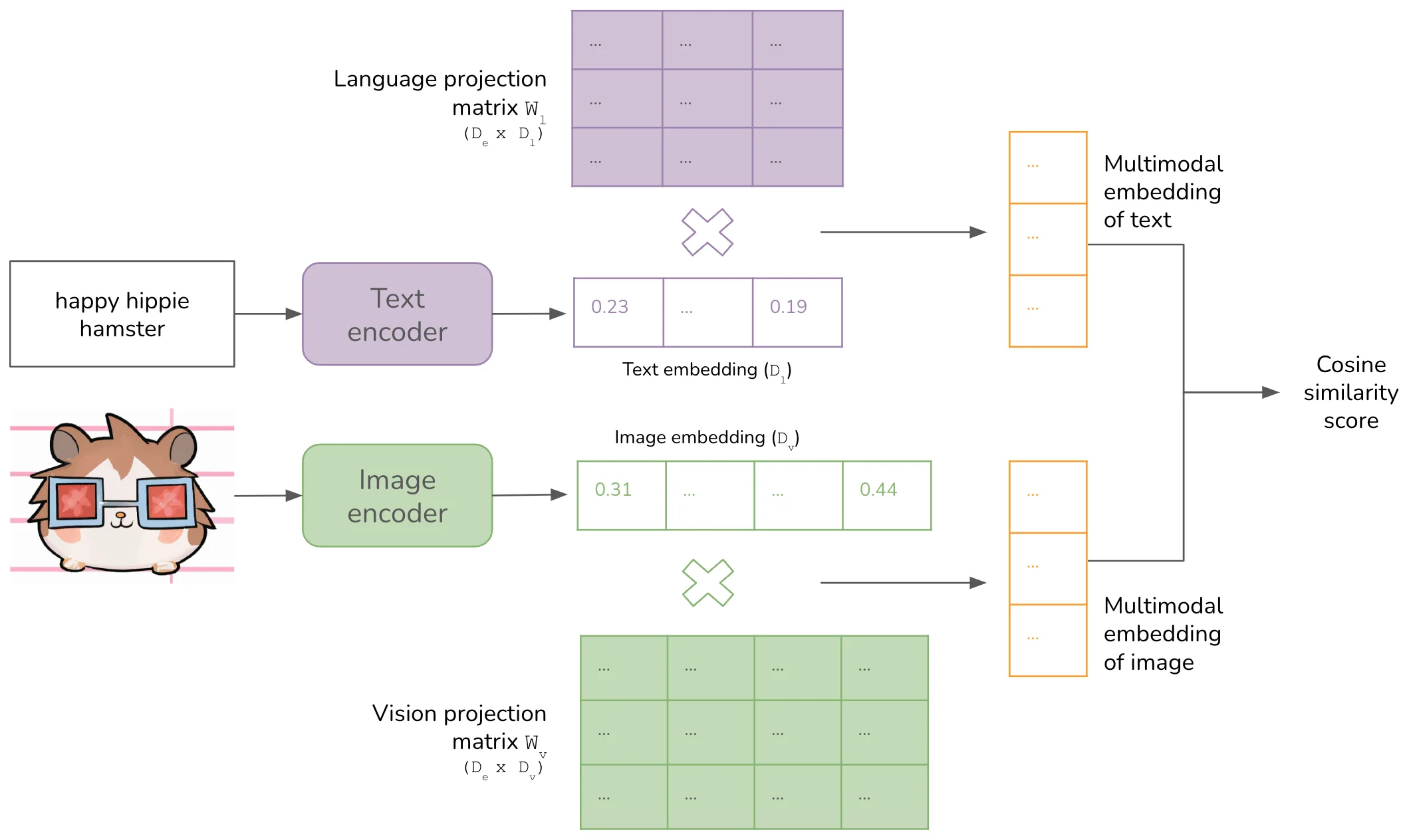
2024年5月,OpenAI发布GPT-4o,这个模型能实时"看"你手机屏幕上的内容并回答问题。对着一张复杂的电路图问"这个电阻的阻值是多少",它能准确定位并读出数值;给它一张手绘的流程图,它能理解逻辑关系并生成代码实现。 ...