Embedding层:从离散符号到语义空间的第一步
计算机无法直接理解文字。当一个语言模型接收到输入"苹果"时,它看到的不是水果的形象,而是一个冰冷的数字——Token ID。Embedding层的工作,就是把这个离散的整数转换成连续的高维向量,让模型能够开始"理解"语言的语义。 ...
计算机无法直接理解文字。当一个语言模型接收到输入"苹果"时,它看到的不是水果的形象,而是一个冰冷的数字——Token ID。Embedding层的工作,就是把这个离散的整数转换成连续的高维向量,让模型能够开始"理解"语言的语义。 ...
从一个问题说起 如果你问一位NLP研究者:“为什么GPT选择了Decoder-only架构,而BERT选择了Encoder-only?“答案可能涉及双向注意力、因果掩码、预训练目标……但如果你追问:“那为什么现在的千亿参数大模型几乎清一色是Decoder-only?“很多人可能就说不清楚了。 ...
2012年,多伦多大学的Hinton团队在论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出了一个反直觉的想法:在训练神经网络时,随机丢弃一部分神经元,反而能让模型表现更好。这个被称为Dropout的技术,随后成为深度学习领域最广泛使用的正则化方法之一,几乎所有的现代神经网络都在使用它。 ...
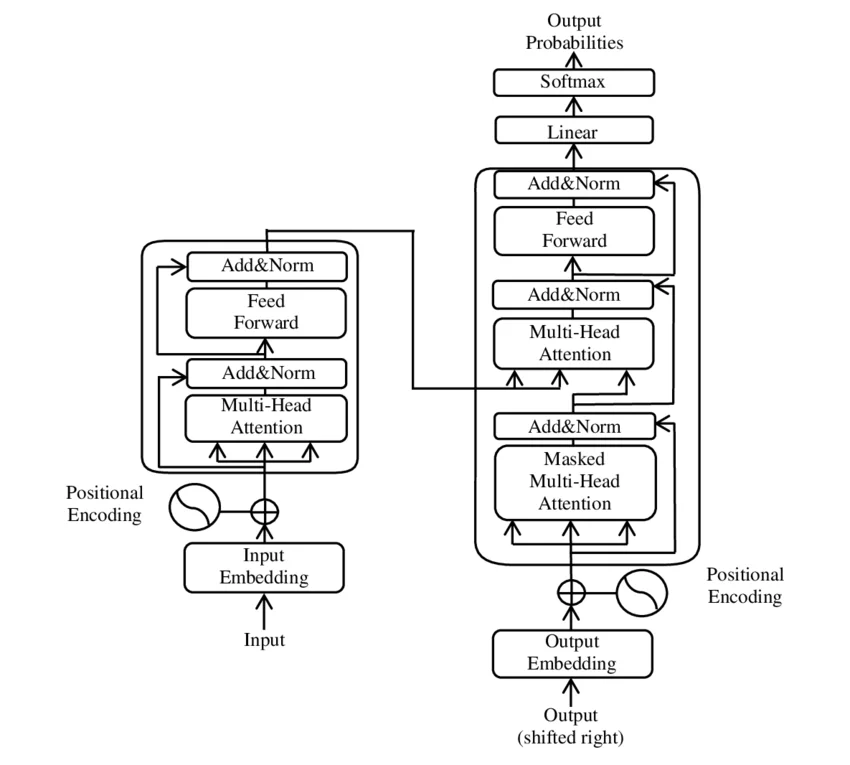
2017年,《Attention Is All You Need》论文提出了Transformer架构,彻底改变了自然语言处理的范式。然而,这个架构很快分化为两条截然不同的发展路径:一条以BERT为代表的编码器路线,通过掩码语言模型(Masked Language Modeling, MLM)学习双向上下文表示;另一条以GPT为代表的解码器路线,通过因果语言模型(Causal Language Modeling, CLM)实现自回归文本生成。 ...

2017年,Vaswani等人在《Attention Is All You Need》论文中提出了Transformer架构。在缩放点积注意力的公式中,有一个看似不起眼的细节:点积结果要除以$\sqrt{d_k}$。这个操作在代码中只是一行,但它背后隐藏着深度学习中最核心的问题之一——梯度消失。 ...
你正在训练一个Transformer模型,Loss曲线稳定下降,一切看起来都很顺利。然后你决定启用混合精度训练来加速——只需一行代码.half()。100步之后:Loss: NaN。训练彻底崩溃。 ...
2017年,Transformer论文发表时,作者选择了一个看似平淡无奇的组件作为前馈神经网络(FFN)的激活函数:ReLU。这个在2011年被重新发现的函数,因其计算简单、梯度稳定而成为深度学习的标配。然而,到了2023年,几乎所有新发布的大语言模型——LLaMA、PaLM、Mistral——都在FFN层抛弃了ReLU,转而采用一个名字拗口的组合:SwiGLU。 ...