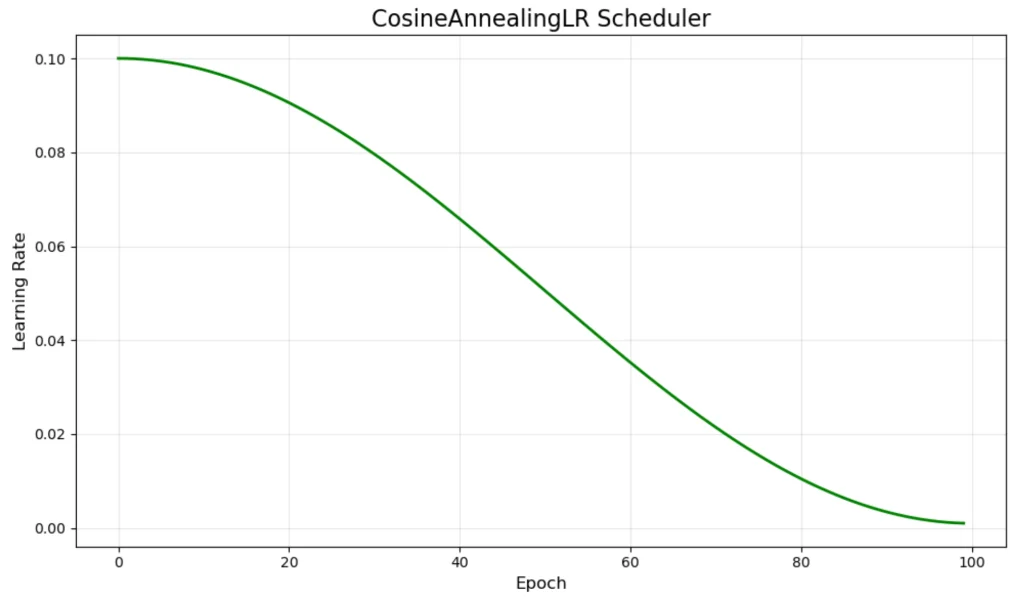
大模型训练中的学习率调度:从线性预热到WSD策略的技术演进
训练过大模型的人都知道,学习率是最关键的超参数之一。设置得太小,训练几个月也收敛不了;设置得太大,模型直接发散。但即使找到了一个看似合适的初始值,直接从头到尾使用恒定学习率,效果往往也不尽如人意。 ...
训练过大模型的人都知道,学习率是最关键的超参数之一。设置得太小,训练几个月也收敛不了;设置得太大,模型直接发散。但即使找到了一个看似合适的初始值,直接从头到尾使用恒定学习率,效果往往也不尽如人意。 ...
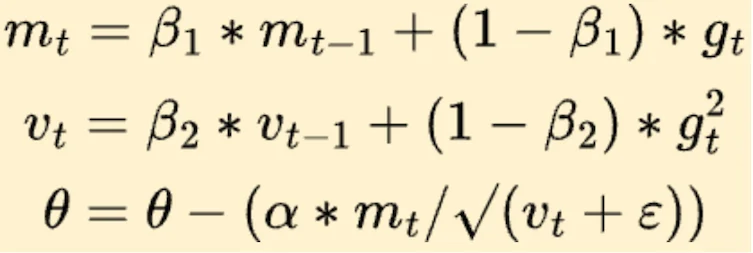
打开任何一个大语言模型的训练代码——GPT-3、LLaMA、BERT、Mistral——你会发现一个惊人的共性:它们清一色使用AdamW优化器。不是经典的随机梯度下降(SGD),不是带动量的SGD,而是AdamW。 ...
2017年,Transformer论文发表时,作者选择了一个看似平淡无奇的组件作为前馈神经网络(FFN)的激活函数:ReLU。这个在2011年被重新发现的函数,因其计算简单、梯度稳定而成为深度学习的标配。然而,到了2023年,几乎所有新发布的大语言模型——LLaMA、PaLM、Mistral——都在FFN层抛弃了ReLU,转而采用一个名字拗口的组合:SwiGLU。 ...

当我们与一个训练完成的大语言模型对话时,它似乎能理解我们的问题、组织连贯的回答、甚至在某些领域展现出接近专家的知识水平。但这个"智能体"并非凭空诞生——在它能说出第一句话之前,背后是一个历时数月、耗资千万美元、涉及万亿级token的复杂训练过程。 ...
2015年,何凯明团队在ImageNet竞赛中提交了一个152层的神经网络模型。这个深度是当时主流模型的8倍,但训练误差却更低——这在当时简直是不可思议的事情。因为在那之前,人们普遍认为网络越深,训练越困难。实际上,研究者们观察到一个反直觉的现象:增加层数反而会让模型性能下降。 ...
2017年,Google Research 团队发表论文《Attention Is All You Need》,提出了一种名为 Transformer 的神经网络架构。论文标题是一个明确的判断——在此之前的神经机器翻译模型依赖于循环神经网络(RNN)和卷积神经网络(CNN)的组合,而 Transformer 仅使用注意力机制就达到了当时的最优性能。 ...
当GPT-3在2020年问世时,其1750亿参数的规模震惊了整个AI界。三年后,LLaMA-70B用更少的参数达到了更好的效果。到了2024年,DeepSeek-V3以6710亿总参数但仅激活370亿参数的MoE架构重新定义了效率边界。这些数字背后隐藏着一套精确的数学逻辑——参数量如何决定计算量,计算量如何影响训练成本,以及如何在有限的算力预算下设计最优模型。 ...