Embedding层:从离散符号到语义空间的第一步
计算机无法直接理解文字。当一个语言模型接收到输入"苹果"时,它看到的不是水果的形象,而是一个冰冷的数字——Token ID。Embedding层的工作,就是把这个离散的整数转换成连续的高维向量,让模型能够开始"理解"语言的语义。 ...
计算机无法直接理解文字。当一个语言模型接收到输入"苹果"时,它看到的不是水果的形象,而是一个冰冷的数字——Token ID。Embedding层的工作,就是把这个离散的整数转换成连续的高维向量,让模型能够开始"理解"语言的语义。 ...
从一个问题说起 如果你问一位NLP研究者:“为什么GPT选择了Decoder-only架构,而BERT选择了Encoder-only?“答案可能涉及双向注意力、因果掩码、预训练目标……但如果你追问:“那为什么现在的千亿参数大模型几乎清一色是Decoder-only?“很多人可能就说不清楚了。 ...
2012年,多伦多大学的Hinton团队在论文《Improving neural networks by preventing co-adaptation of feature detectors》中提出了一个反直觉的想法:在训练神经网络时,随机丢弃一部分神经元,反而能让模型表现更好。这个被称为Dropout的技术,随后成为深度学习领域最广泛使用的正则化方法之一,几乎所有的现代神经网络都在使用它。 ...
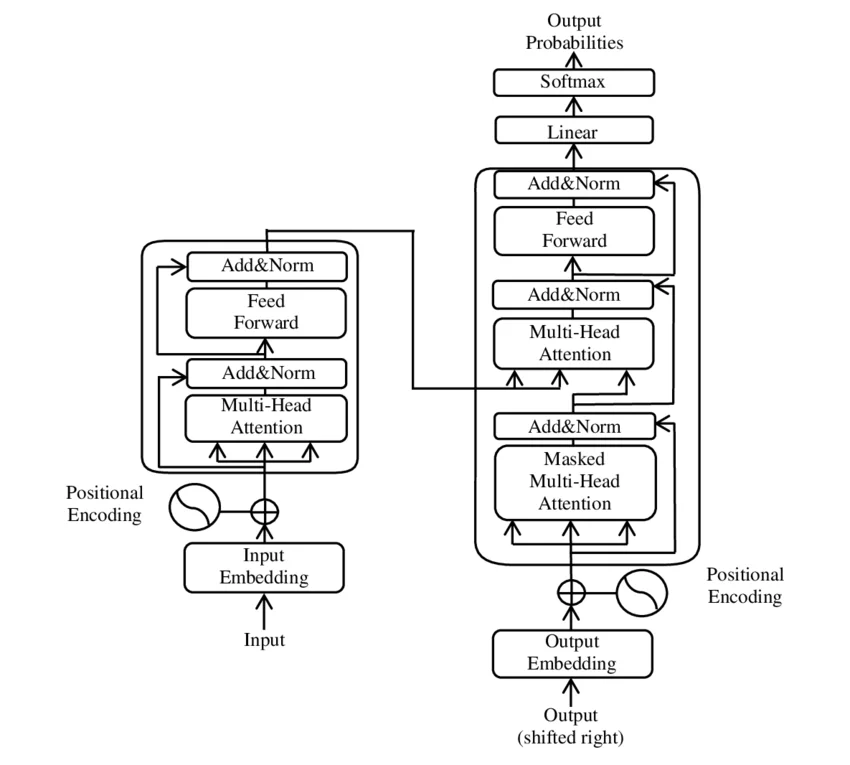
2017年,《Attention Is All You Need》论文提出了Transformer架构,彻底改变了自然语言处理的范式。然而,这个架构很快分化为两条截然不同的发展路径:一条以BERT为代表的编码器路线,通过掩码语言模型(Masked Language Modeling, MLM)学习双向上下文表示;另一条以GPT为代表的解码器路线,通过因果语言模型(Causal Language Modeling, CLM)实现自回归文本生成。 ...
在神经网络的输出层,我们经常看到这样一个公式: $$\text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}}$$它看起来如此简单——指数、求和、归一化。但为什么是这个特定的形式?为什么不直接除以总和?为什么要有指数?为什么这个函数能统治从图像分类到大语言模型的几乎所有概率输出? ...

1997年,IBM的研究人员在开发统计机器翻译系统时遇到了一个棘手的问题:如何在庞大的搜索空间中找到最优的翻译序列?穷举搜索计算量太大,贪婪搜索又太短视。他们最终选择了一个折中方案——Beam Search。二十多年过去了,这个算法不仅没有被淘汰,反而成为了Transformer、GPT等现代大模型的标准配置。一个「妥协」的产物为何能统治序列生成领域如此之久? ...
你正在训练一个Transformer模型,Loss曲线稳定下降,一切看起来都很顺利。然后你决定启用混合精度训练来加速——只需一行代码.half()。100步之后:Loss: NaN。训练彻底崩溃。 ...