假设你正在开发一个实时数据分析平台,需要频繁执行两类操作:查询某个时间段内的数据总和,以及更新某个时间点的数值。如果用普通数组,查询需要 $O(n)$ 时间遍历整个区间;如果用前缀和数组,查询确实降到了 $O(1)$,但每次更新又需要 $O(n)$ 时间重新计算前缀。当数据量达到百万级别、操作频率达到每秒数千次时,这两种方案都无法满足性能要求。
线段树(Segment Tree)正是为这类"区间查询 + 点更新/区间更新"问题而生的数据结构。它在 $O(\log n)$ 时间内完成查询和更新两种操作,完美平衡了读写效率。这个由 Jon Bentley 在 1977 年发明的数据结构,最初是为了解决计算几何中的 Klee 矩形面积问题,如今已成为算法竞赛和工程实践中的必备工具。
线段树的核心思想:分治与预处理
线段树的核心思想非常朴素:将大区间分解为小区间,预先计算每个小区间的聚合值。
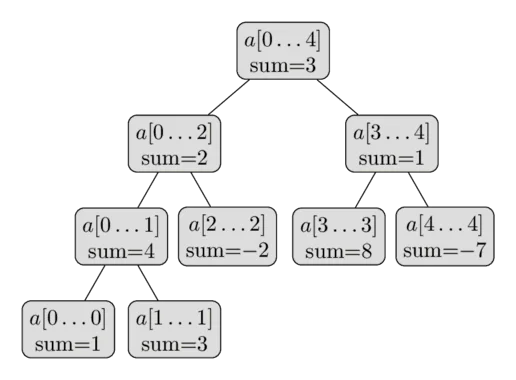
给定一个长度为 $n$ 的数组,线段树将其视为一个完整区间 $[0, n-1]$,然后递归地将其分裂为两个子区间,直到每个区间只包含一个元素。这形成了一棵完全二叉树:
- 根节点表示整个区间 $[0, n-1]$
- 每个非叶节点表示一个区间 $[l, r]$,其左右子节点分别表示 $[l, mid]$ 和 $[mid+1, r]$
- 叶节点表示单个元素 $[i, i]$
每个节点存储其所表示区间的聚合信息——可以是区间和、最大值、最小值、GCD 等,具体取决于问题需求。
为什么查询和更新都是 $O(\log n)$?
查询:对于任意区间查询 $[l, r]$,线段树将其分解为 $O(\log n)$ 个不相交的节点区间。这些节点恰好覆盖整个查询区间,且数量不超过 $4 \log n$。直观理解:树的每一层最多访问 4 个节点(两个边界各贡献 2 个),而树高为 $O(\log n)$。
更新:修改单个元素时,只需更新从根到该元素对应叶节点的路径上的所有节点,路径长度为 $O(\log n)$。
线段树的数组实现
虽然线段树本质上是二叉树,但通常使用数组存储——类似于堆的表示方式。节点 $i$ 的左右子节点分别为 $2i$ 和 $2i+1$(使用 1-indexing)。
空间复杂度分析:对于 $n$ 个元素的数组,线段树需要 $4n$ 个位置。这是因为:
- 完全二叉树的节点数最多为 $2^{\lceil \log_2 n \rceil + 1} - 1$
- 当 $n$ 不是 2 的幂时,实际节点数可能超过 $2n$
因此,标准的实现总是分配 $4n$ 大小的数组。
public class SegmentTree {
private int[] tree;
private int[] data;
private int n;
public SegmentTree(int[] nums) {
n = nums.length;
data = nums.clone();
tree = new int[4 * n];
build(1, 0, n - 1);
}
// 构建线段树:node 表示当前节点,[l, r] 表示当前区间
private void build(int node, int l, int r) {
if (l == r) {
tree[node] = data[l];
return;
}
int mid = l + (r - l) / 2;
int leftChild = 2 * node;
int rightChild = 2 * node + 1;
build(leftChild, l, mid);
build(rightChild, mid + 1, r);
tree[node] = tree[leftChild] + tree[rightChild];
}
// 区间查询:查询 [ql, qr] 的和
public int query(int ql, int qr) {
return query(1, 0, n - 1, ql, qr);
}
private int query(int node, int l, int r, int ql, int qr) {
// 完全不相交
if (qr < l || ql > r) {
return 0;
}
// 当前区间完全被查询区间包含
if (ql <= l && r <= qr) {
return tree[node];
}
// 部分重叠,递归查询子节点
int mid = l + (r - l) / 2;
int leftSum = query(2 * node, l, mid, ql, qr);
int rightSum = query(2 * node + 1, mid + 1, r, ql, qr);
return leftSum + rightSum;
}
// 单点更新:将 data[index] 更新为 value
public void update(int index, int value) {
update(1, 0, n - 1, index, value);
}
private void update(int node, int l, int r, int index, int value) {
if (l == r) {
tree[node] = value;
data[index] = value;
return;
}
int mid = l + (r - l) / 2;
if (index <= mid) {
update(2 * node, l, mid, index, value);
} else {
update(2 * node + 1, mid + 1, r, index, value);
}
tree[node] = tree[2 * node] + tree[2 * node + 1];
}
}
懒惰传播:让区间更新也变成 $O(\log n)$
如果问题需要区间更新(如"将区间 $[l, r]$ 内所有元素加 $k$"),朴素的方法是对区间内每个元素执行单点更新,时间复杂度为 $O(n \log n)$。
懒惰传播(Lazy Propagation)通过"延迟更新"的技巧,将区间更新优化到 $O(\log n)$。核心思想是:如果某个节点代表的区间完全在更新范围内,先更新该节点,然后将要传播给子节点的更新暂存在懒惰数组中,等到真正需要访问子节点时再执行更新。
public class LazySegmentTree {
private int[] tree;
private int[] lazy; // 懒惰标记
private int n;
public LazySegmentTree(int[] nums) {
n = nums.length;
tree = new int[4 * n];
lazy = new int[4 * n];
build(nums, 1, 0, n - 1);
}
private void build(int[] nums, int node, int l, int r) {
if (l == r) {
tree[node] = nums[l];
return;
}
int mid = l + (r - l) / 2;
build(nums, 2 * node, l, mid);
build(nums, 2 * node + 1, mid + 1, r);
tree[node] = tree[2 * node] + tree[2 * node + 1];
}
// 下推懒惰标记
private void pushDown(int node, int l, int r) {
if (lazy[node] != 0) {
int mid = l + (r - l) / 2;
int leftLen = mid - l + 1;
int rightLen = r - mid;
// 更新子节点的值和懒惰标记
tree[2 * node] += leftLen * lazy[node];
tree[2 * node + 1] += rightLen * lazy[node];
lazy[2 * node] += lazy[node];
lazy[2 * node + 1] += lazy[node];
lazy[node] = 0;
}
}
// 区间更新:[ul, ur] 内所有元素加 val
public void updateRange(int ul, int ur, int val) {
updateRange(1, 0, n - 1, ul, ur, val);
}
private void updateRange(int node, int l, int r, int ul, int ur, int val) {
// 完全不相交
if (ur < l || ul > r) {
return;
}
// 当前区间完全在更新范围内
if (ul <= l && r <= ur) {
tree[node] += (r - l + 1) * val;
lazy[node] += val;
return;
}
// 部分重叠:先下推懒惰标记,再递归更新
pushDown(node, l, r);
int mid = l + (r - l) / 2;
updateRange(2 * node, l, mid, ul, ur, val);
updateRange(2 * node + 1, mid + 1, r, ul, ur, val);
tree[node] = tree[2 * node] + tree[2 * node + 1];
}
// 区间查询(需要先处理懒惰标记)
public int queryRange(int ql, int qr) {
return queryRange(1, 0, n - 1, ql, qr);
}
private int queryRange(int node, int l, int r, int ql, int qr) {
if (qr < l || ql > r) {
return 0;
}
if (ql <= l && r <= qr) {
return tree[node];
}
pushDown(node, l, r);
int mid = l + (r - l) / 2;
return queryRange(2 * node, l, mid, ql, qr) +
queryRange(2 * node + 1, mid + 1, r, ql, qr);
}
}
线段树与树状数组的对比
线段树和树状数组(Binary Indexed Tree/Fenwick Tree)都是处理区间问题的经典数据结构,但它们的能力边界不同:
| 特性 | 线段树 | 树状数组 |
|---|---|---|
| 空间复杂度 | $O(4n)$ | $O(n)$ |
| 单点更新 | $O(\log n)$ | $O(\log n)$ |
| 区间查询 | $O(\log n)$ | $O(\log n)$ |
| 区间更新 | $O(\log n)$(懒惰传播) | $O(\log n)$(差分技巧) |
| 可维护信息 | 任意满足结合律的操作 | 仅限前缀可递推的操作 |
| 实现复杂度 | 中等 | 简单 |
树状数组更轻量、更简洁,但线段树更强大、更通用。当需要维护区间最大值、区间 GCD 等信息时,线段树是首选。
LeetCode 经典题目详解
LeetCode 307. Range Sum Query - Mutable
这是线段树最基础的应用:实现一个支持单点更新和区间查询的数据结构。
class NumArray {
private int[] tree;
private int n;
public NumArray(int[] nums) {
n = nums.length;
tree = new int[4 * n];
build(nums, 1, 0, n - 1);
}
private void build(int[] nums, int node, int l, int r) {
if (l == r) {
tree[node] = nums[l];
return;
}
int mid = l + (r - l) / 2;
build(nums, 2 * node, l, mid);
build(nums, 2 * node + 1, mid + 1, r);
tree[node] = tree[2 * node] + tree[2 * node + 1];
}
public void update(int index, int val) {
update(1, 0, n - 1, index, val);
}
private void update(int node, int l, int r, int index, int val) {
if (l == r) {
tree[node] = val;
return;
}
int mid = l + (r - l) / 2;
if (index <= mid) {
update(2 * node, l, mid, index, val);
} else {
update(2 * node + 1, mid + 1, r, index, val);
}
tree[node] = tree[2 * node] + tree[2 * node + 1];
}
public int sumRange(int left, int right) {
return query(1, 0, n - 1, left, right);
}
private int query(int node, int l, int r, int ql, int qr) {
if (qr < l || ql > r) return 0;
if (ql <= l && r <= qr) return tree[node];
int mid = l + (r - l) / 2;
return query(2 * node, l, mid, ql, qr) +
query(2 * node + 1, mid + 1, r, ql, qr);
}
}
LeetCode 315. Count of Smaller Numbers After Self
这道题要求统计每个元素右侧比它小的元素个数。暴力解法是 $O(n^2)$,用线段树可以优化到 $O(n \log n)$。
核心思路:从右向左遍历数组,维护一个值域线段树,统计每个值的出现次数。对于当前元素 nums[i],查询比它小的值的总数,就是它的答案。
class Solution {
public List<Integer> countSmaller(int[] nums) {
// 离散化:将数值映射到排名
int[] sorted = nums.clone();
Arrays.sort(sorted);
Map<Integer, Integer> ranks = new HashMap<>();
int rank = 0;
for (int num : sorted) {
if (!ranks.containsKey(num)) {
ranks.put(num, ++rank);
}
}
int n = nums.length;
int[] tree = new int[4 * (rank + 1)];
Integer[] result = new Integer[n];
// 从右向左遍历
for (int i = n - 1; i >= 0; i--) {
int r = ranks.get(nums[i]);
// 查询比当前元素小的元素个数(排名小于 r 的)
result[i] = query(tree, 1, 1, rank, 1, r - 1);
// 将当前元素加入线段树
update(tree, 1, 1, rank, r);
}
return Arrays.asList(result);
}
private int query(int[] tree, int node, int l, int r, int ql, int qr) {
if (ql > qr || qr < l || ql > r) return 0;
if (ql <= l && r <= qr) return tree[node];
int mid = l + (r - l) / 2;
return query(tree, 2 * node, l, mid, ql, qr) +
query(tree, 2 * node + 1, mid + 1, r, ql, qr);
}
private void update(int[] tree, int node, int l, int r, int index) {
if (l == r) {
tree[node]++;
return;
}
int mid = l + (r - l) / 2;
if (index <= mid) {
update(tree, 2 * node, l, mid, index);
} else {
update(tree, 2 * node + 1, mid + 1, r, index);
}
tree[node] = tree[2 * node] + tree[2 * node + 1];
}
}
LeetCode 327. Count of Range Sum
这道题要求统计区间和在 $[lower, upper]$ 范围内的子数组数量。关键转化是使用前缀和:$S(i, j) = prefix[j+1] - prefix[i]$。
问题转化为:对于每个 $j$,找有多少 $i < j$ 满足 $lower \leq prefix[j+1] - prefix[i] \leq upper$,即 $prefix[j+1] - upper \leq prefix[i] \leq prefix[j+1] - lower$。
class Solution {
public int countRangeSum(int[] nums, int lower, int upper) {
int n = nums.length;
long[] prefix = new long[n + 1];
for (int i = 0; i < n; i++) {
prefix[i + 1] = prefix[i] + nums[i];
}
// 离散化所有可能涉及的值
Set<Long> set = new TreeSet<>();
for (long p : prefix) {
set.add(p);
set.add(p - lower);
set.add(p - upper);
}
Map<Long, Integer> ranks = new HashMap<>();
int rank = 0;
for (long val : set) {
ranks.put(val, ++rank);
}
int[] tree = new int[4 * (rank + 1)];
int result = 0;
for (int i = 0; i <= n; i++) {
long p = prefix[i];
// 查询之前的前缀和在 [p - upper, p - lower] 范围内的数量
int l = ranks.get(p - upper);
int r = ranks.get(p - lower);
result += query(tree, 1, 1, rank, l, r);
// 将当前前缀和加入线段树
update(tree, 1, 1, rank, ranks.get(p));
}
return result;
}
private int query(int[] tree, int node, int l, int r, int ql, int qr) {
if (ql > qr || qr < l || ql > r) return 0;
if (ql <= l && r <= qr) return tree[node];
int mid = l + (r - l) / 2;
return query(tree, 2 * node, l, mid, ql, qr) +
query(tree, 2 * node + 1, mid + 1, r, ql, qr);
}
private void update(int[] tree, int node, int l, int r, int index) {
if (l == r) {
tree[node]++;
return;
}
int mid = l + (r - l) / 2;
if (index <= mid) {
update(tree, 2 * node, l, mid, index);
} else {
update(tree, 2 * node + 1, mid + 1, r, index);
}
tree[node] = tree[2 * node] + tree[2 * node + 1];
}
}
LeetCode 493. Reverse Pairs
这道题要求统计逆序对 $(i, j)$ 满足 $i < j$ 且 $nums[i] > 2 \times nums[j]$。
思路与 315 题类似:从右向左遍历,维护值域线段树,查询当前元素右侧有多少元素的 2 倍小于当前元素。
class Solution {
public int reversePairs(int[] nums) {
// 离散化:考虑原值和 2 倍值
Set<Long> set = new TreeSet<>();
for (int num : nums) {
set.add((long) num);
set.add((long) 2 * num);
}
Map<Long, Integer> ranks = new HashMap<>();
int rank = 0;
for (long val : set) {
ranks.put(val, ++rank);
}
int n = nums.length;
int[] tree = new int[4 * (rank + 1)];
int result = 0;
for (int i = n - 1; i >= 0; i--) {
int num = nums[i];
// 查询 2 * num 的排名,然后找比它小的元素数量
int targetRank = ranks.get((long) 2 * num);
result += query(tree, 1, 1, rank, 1, targetRank - 1);
// 将当前元素加入线段树
update(tree, 1, 1, rank, ranks.get((long) num));
}
return result;
}
private int query(int[] tree, int node, int l, int r, int ql, int qr) {
if (ql > qr || qr < l || ql > r) return 0;
if (ql <= l && r <= qr) return tree[node];
int mid = l + (r - l) / 2;
return query(tree, 2 * node, l, mid, ql, qr) +
query(tree, 2 * node + 1, mid + 1, r, ql, qr);
}
private void update(int[] tree, int node, int l, int r, int index) {
if (l == r) {
tree[node]++;
return;
}
int mid = l + (r - l) / 2;
if (index <= mid) {
update(tree, 2 * node, l, mid, index);
} else {
update(tree, 2 * node + 1, mid + 1, r, index);
}
tree[node] = tree[2 * node] + tree[2 * node + 1];
}
}
线段树的变体与进阶
持久化线段树
持久化线段树(Persistent Segment Tree)允许访问历史版本,实现"时间旅行"式的查询。核心思想是每次更新时,不修改原节点,而是创建新节点。这样,通过保存根节点指针,可以访问任意时刻的数据状态。
典型应用:静态区间第 $k$ 小问题(LeetCode 未收录,但常见于算法竞赛)。
动态开点线段树
当值域非常大(如 $10^9$ 级别)时,预分配 $4n$ 空间不可行。动态开点线段树按需创建节点,只在实际访问时才分配内存。
class DynamicSegmentTree {
private class Node {
int val;
Node left, right;
}
private Node root;
private long L, R; // 值域范围
public DynamicSegmentTree(long L, long R) {
this.L = L;
this.R = R;
root = new Node();
}
public void update(long index, int val) {
update(root, L, R, index, val);
}
private void update(Node node, long l, long r, long index, int val) {
if (l == r) {
node.val += val;
return;
}
long mid = l + (r - l) / 2;
if (index <= mid) {
if (node.left == null) node.left = new Node();
update(node.left, l, mid, index, val);
} else {
if (node.right == null) node.right = new Node();
update(node.right, mid + 1, r, index, val);
}
node.val = (node.left != null ? node.left.val : 0) +
(node.right != null ? node.right.val : 0);
}
}
线段树合并与分裂
线段树合并用于合并两棵线段树,时间复杂度为 $O(n \log n)$。线段树分裂用于将一棵线段树按位置拆分为两棵。这两种操作在处理动态集合问题时非常有用。
实际应用场景
线段树在实际工程中有广泛的应用:
数据库查询优化:关系型数据库在处理范围查询时,内部可能使用类似线段树的结构来加速聚合操作(SUM、MAX、MIN 等)。
图像处理:计算图像某区域的像素统计信息(亮度均值、颜色直方图等)时,可以用二维线段树加速查询。
调度系统:任务调度系统中,可以用线段树维护资源占用情况,快速判断某时间段是否有足够资源。
游戏开发:碰撞检测、视野查询等场景中,线段树可以加速空间范围查询。
复杂度总结
| 操作 | 时间复杂度 | 空间复杂度 |
|---|---|---|
| 构建 | $O(n)$ | $O(4n)$ |
| 单点查询 | $O(\log n)$ | - |
| 单点更新 | $O(\log n)$ | - |
| 区间查询 | $O(\log n)$ | - |
| 区间更新(懒惰传播) | $O(\log n)$ | $O(4n)$(额外懒惰数组) |
刷题建议
入门:307 → 303(用前缀和更简单,但可用线段树练习)
进阶:315 → 327 → 493(离散化 + 值域线段树)
高难度:715(区间加值 + 查询)→ 732(事件统计)→ 699(方块下落)
线段树的魅力在于它的通用性——只需改变节点存储的信息和合并操作,就能适配各种区间问题。从简单的区间求和,到复杂的持久化查询,线段树提供了一套优雅而高效的解决方案。理解其核心思想后,你会发现它在算法竞赛和实际工程中无处不在。
参考资料
- Bentley, J. L. “Algorithms for Klee’s rectangle problems.” Unpublished notes, Carnegie-Mellon University, 1977.
- CP-Algorithms. “Segment Tree.” https://cp-algorithms.com/data_structures/segment_tree.html
- GeeksforGeeks. “Segment Tree Data Structure.” https://www.geeksforgeeks.org/dsa/segment-tree-data-structure/
- GeeksforGeeks. “Lazy Propagation in Segment Tree.” https://www.geeksforgeeks.org/dsa/lazy-propagation-in-segment-tree/
- HackerEarth. “Segment Tree and Lazy Propagation.” https://www.hackerearth.com/practice/notes/segment-tree-and-lazy-propagation/
- LeetCode Discuss. “Introduction to Segment Tree - A Complete Guide.” https://leetcode.com/discuss/general-discussion/1128655/
- VisuAlgo. “Segment Tree Visualization.” https://visualgo.net/en/segmenttree
- USACO Guide. “Segment Tree Beats.” https://usaco.guide/adv/segtree-beats
- OI Wiki. “线段树.” https://oi-wiki.org/ds/seg/
- Wikipedia. “Klee’s Measure Problem.” https://en.wikipedia.org/wiki/Klee%27s_measure_problem