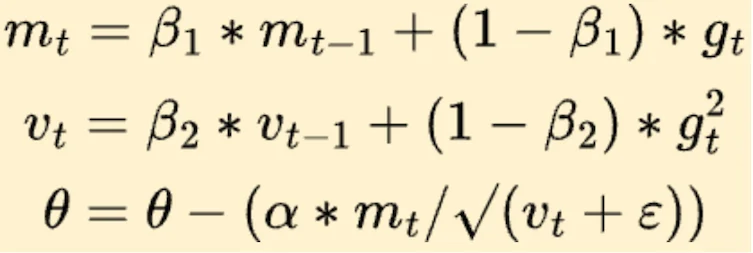权重初始化:为什么一行代码能决定神经网络的生死
2010年,Xavier Glorot和Yoshua Bengio在AISTATS会议上发表了一篇论文,标题是《Understanding the difficulty of training deep feedforward neural networks》。这篇论文揭示了一个困扰深度学习社区多年的问题:为什么深层神经网络在随机初始化下难以训练?他们提出了一种新的初始化方案,后来被称为Xavier初始化。五年后,何恺明等人针对ReLU激活函数提出了He初始化。这两种初始化方法至今仍是现代神经网络训练的基础。 ...