SwiGLU为何成为大模型的标配:从ReLU到门控激活函数的十五年演进
2017年,Transformer论文发表时,作者选择了一个看似平淡无奇的组件作为前馈神经网络(FFN)的激活函数:ReLU。这个在2011年被重新发现的函数,因其计算简单、梯度稳定而成为深度学习的标配。然而,到了2023年,几乎所有新发布的大语言模型——LLaMA、PaLM、Mistral——都在FFN层抛弃了ReLU,转而采用一个名字拗口的组合:SwiGLU。 ...
2017年,Transformer论文发表时,作者选择了一个看似平淡无奇的组件作为前馈神经网络(FFN)的激活函数:ReLU。这个在2011年被重新发现的函数,因其计算简单、梯度稳定而成为深度学习的标配。然而,到了2023年,几乎所有新发布的大语言模型——LLaMA、PaLM、Mistral——都在FFN层抛弃了ReLU,转而采用一个名字拗口的组合:SwiGLU。 ...
当你调用一个大语言模型的API时,通常会传入类似这样的结构: messages = [ {"role": "system", "content": "你是一个有帮助的助手。"}, {"role": "user", "content": "你好!"}, {"role": "assistant", "content": "你好!有什么可以帮助你的吗?"}, {"role": "user", "content": "2+2等于多少?"}, ] 这个整洁的消息列表,在送入模型之前,会被转换成一段连续的文本。问题是:这段文本长什么样? ...

当我们与一个训练完成的大语言模型对话时,它似乎能理解我们的问题、组织连贯的回答、甚至在某些领域展现出接近专家的知识水平。但这个"智能体"并非凭空诞生——在它能说出第一句话之前,背后是一个历时数月、耗资千万美元、涉及万亿级token的复杂训练过程。 ...
1994年2月,Philip Gage在《C Users Journal》上发表了一篇题为"A New Algorithm for Data Compression"的文章。这位程序员的初衷很简单:找到一种更高效的方式来压缩数据。他没有想到,三十年后,他发明的Byte Pair Encoding(BPE)算法会成为让ChatGPT、Claude、LLaMA等大语言模型理解人类语言的第一道关卡。 ...
当一个新的大模型发布时,我们如何判断它到底有多强? 模型技术报告上那些眼花缭乱的数字——MMLU 92%、GSM8K 95%、HumanEval 88%——究竟意味着什么?为什么一个在基准测试中表现优异的模型,实际使用时却常常令人失望? ...
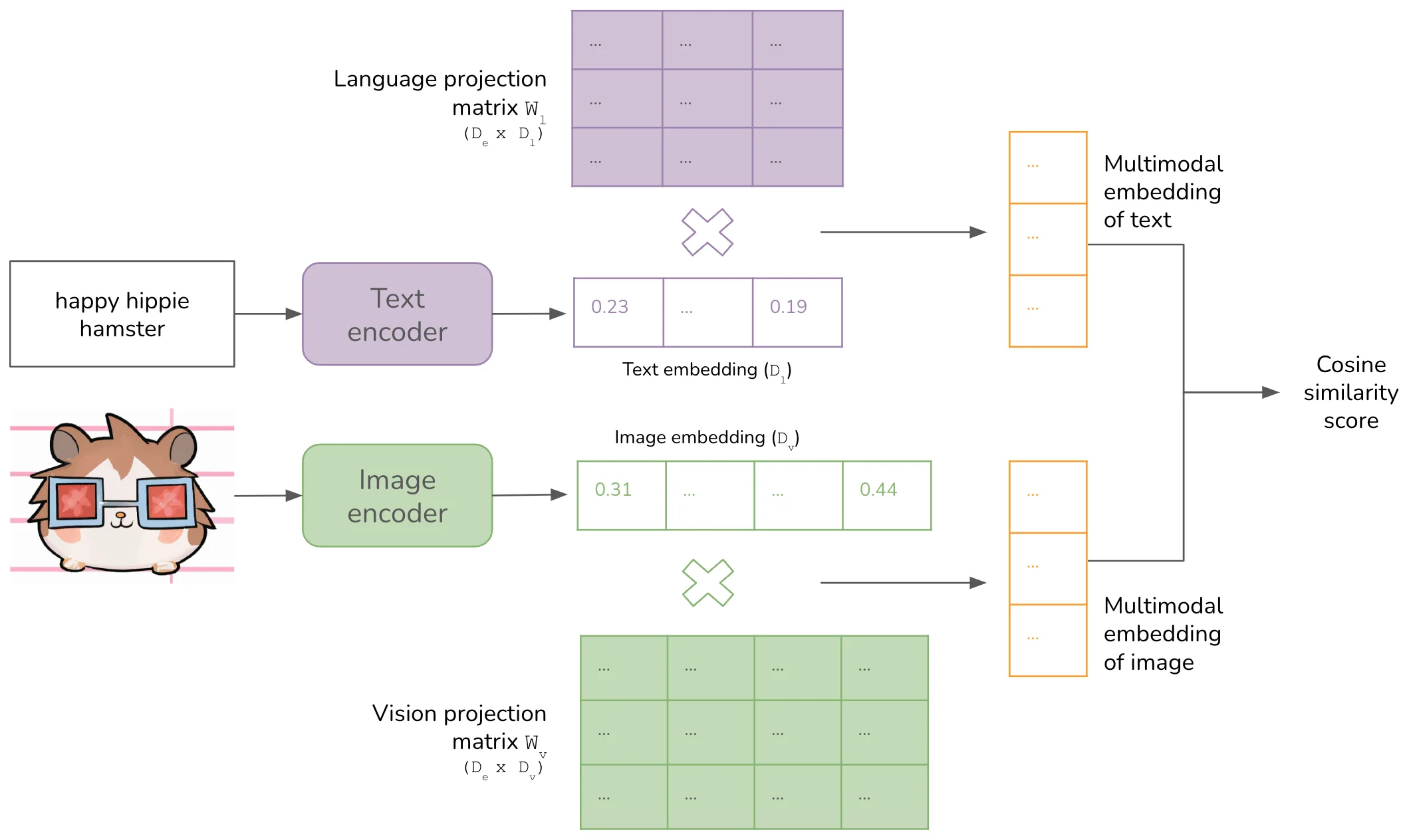
2024年5月,OpenAI发布GPT-4o,这个模型能实时"看"你手机屏幕上的内容并回答问题。对着一张复杂的电路图问"这个电阻的阻值是多少",它能准确定位并读出数值;给它一张手绘的流程图,它能理解逻辑关系并生成代码实现。 ...
搜索"如何学习编程"和"编程入门方法",传统关键词匹配系统会认为这两个查询毫无关系——它们没有共享任何关键词。但人类一眼就能看出这是同一类问题。这个鸿沟困扰了信息检索领域数十年,直到向量嵌入技术给出了一个优雅的数学答案:把文字映射到连续向量空间,让语义相似的文本在几何空间中靠近。 ...