
Beam Search:为什么这个「折中」算法统治了序列生成三十年
1997年,IBM的研究人员在开发统计机器翻译系统时遇到了一个棘手的问题:如何在庞大的搜索空间中找到最优的翻译序列?穷举搜索计算量太大,贪婪搜索又太短视。他们最终选择了一个折中方案——Beam Search。二十多年过去了,这个算法不仅没有被淘汰,反而成为了Transformer、GPT等现代大模型的标准配置。一个「妥协」的产物为何能统治序列生成领域如此之久? ...
1997年,IBM的研究人员在开发统计机器翻译系统时遇到了一个棘手的问题:如何在庞大的搜索空间中找到最优的翻译序列?穷举搜索计算量太大,贪婪搜索又太短视。他们最终选择了一个折中方案——Beam Search。二十多年过去了,这个算法不仅没有被淘汰,反而成为了Transformer、GPT等现代大模型的标准配置。一个「妥协」的产物为何能统治序列生成领域如此之久? ...
同样的文本内容,在一个模型中可能只需要100个token,在另一个模型中却可能膨胀到300个。这背后的差异源于一个经常被忽视但至关重要的设计决策:词表大小的选择。 ...

2017年,Vaswani等人在《Attention Is All You Need》论文中提出了Transformer架构。在缩放点积注意力的公式中,有一个看似不起眼的细节:点积结果要除以$\sqrt{d_k}$。这个操作在代码中只是一行,但它背后隐藏着深度学习中最核心的问题之一——梯度消失。 ...

一个困惑的起点 你问 GPT-4:“告诉我关于量子纠缠的事情”,它给你一段教科书式的定义。你换个说法:“量子纠缠到底有多诡异?能用通俗的方式解释吗?“回答变得生动有趣,甚至还用了比喻。 ...
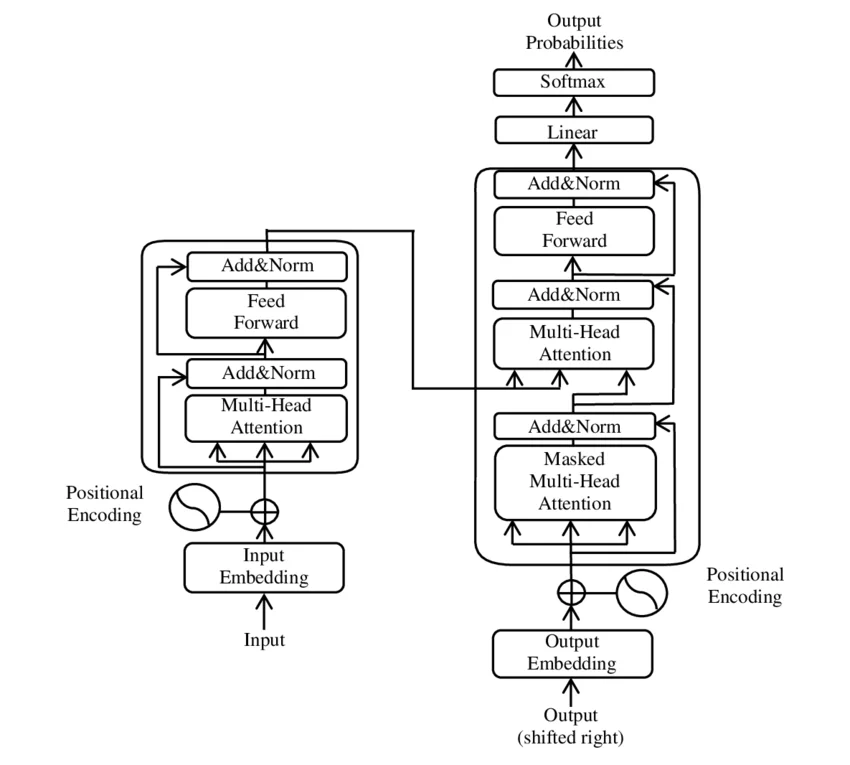
你正在训练一个Transformer模型,Loss曲线稳定下降,一切看起来都很顺利。然后你决定启用混合精度训练来加速——只需一行代码.half()。100步之后:Loss: NaN。训练彻底崩溃。 ...
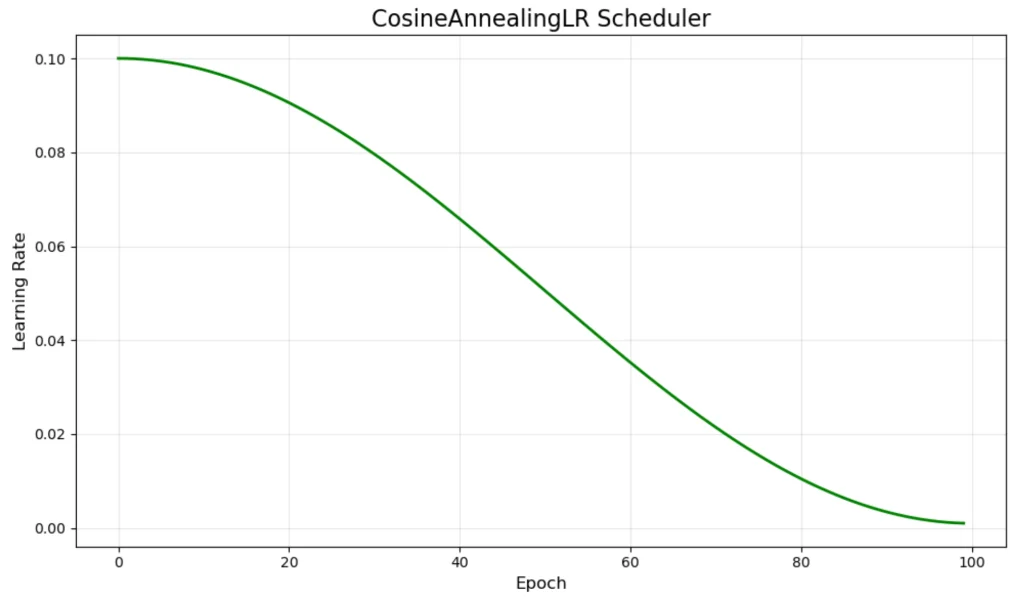
训练过大模型的人都知道,学习率是最关键的超参数之一。设置得太小,训练几个月也收敛不了;设置得太大,模型直接发散。但即使找到了一个看似合适的初始值,直接从头到尾使用恒定学习率,效果往往也不尽如人意。 ...
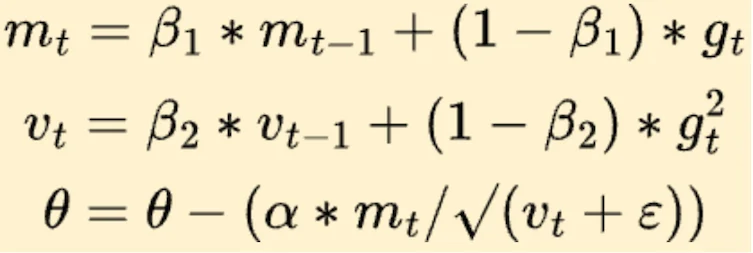
打开任何一个大语言模型的训练代码——GPT-3、LLaMA、BERT、Mistral——你会发现一个惊人的共性:它们清一色使用AdamW优化器。不是经典的随机梯度下降(SGD),不是带动量的SGD,而是AdamW。 ...