2018年,某互联网公司的一条生产事故报告引发了广泛关注:他们的RocksDB实例在写入量激增时突然"卡死",应用层请求超时雪崩。排查日志后发现,罪魁祸首是Write Stall——RocksDB的内部保护机制在L0层文件过多时主动暂停写入。这不是孤例。在LSM-Tree架构的数据库中,Compaction(合并压缩)机制既是性能的守护者,也可能成为故障的导火索。
为什么一个看似后台的维护操作,会对系统产生如此深远的影响?答案藏在LSM-Tree的设计哲学中:将写入的随机I/O转换为顺序I/O,代价是在读取时付出更多的努力,并通过Compaction来管理这份"技术债务"。理解Compaction,就是理解现代写密集型数据库的核心权衡。
从一个简单问题说起:为什么LSM-Tree需要Compaction?
1996年,Patrick O’Neil、Edward Cheng、Dieter Gawlick和Elizabeth O’Neil在《Acta Informatica》上发表了题为《The Log-Structured Merge-Tree (LSM-Tree)》的论文。这篇论文解决了一个看似简单却困扰数据库设计者多年的问题:如何为高写入负载的场景设计高效的索引结构?
传统的B+树在处理随机写入时面临一个根本性困境:每次更新都可能触发页分裂,导致随机I/O。对于机械硬盘,随机I/O的代价是顺序I/O的100倍以上。即使对于SSD,虽然随机I/O的性能显著改善,但写入放大(Write Amplification)仍然会消耗宝贵的写入寿命。
LSM-Tree的解决方案令人耳目一新:不原地更新,只追加写入。数据首先写入内存中的MemTable(C0树),当MemTable达到阈值后,整体刷入磁盘成为不可变的SSTable。这个过程是纯顺序写入,吞吐量极高。
但这里埋下了一个隐患:同一个key可能存在于多个SSTable中,读取时需要从新到旧逐一查找。随着数据积累,SSTable数量不断增长,读取性能线性下降。更糟糕的是,删除操作只是写入一个墓碑标记(Tombstone),被删除的数据仍然占用磁盘空间。
这就是Compaction存在的意义:合并多个SSTable,丢弃过期数据,整理碎片,重建有序结构。没有Compaction,LSM-Tree会退化成一个只能追加的日志文件,读取性能持续恶化。
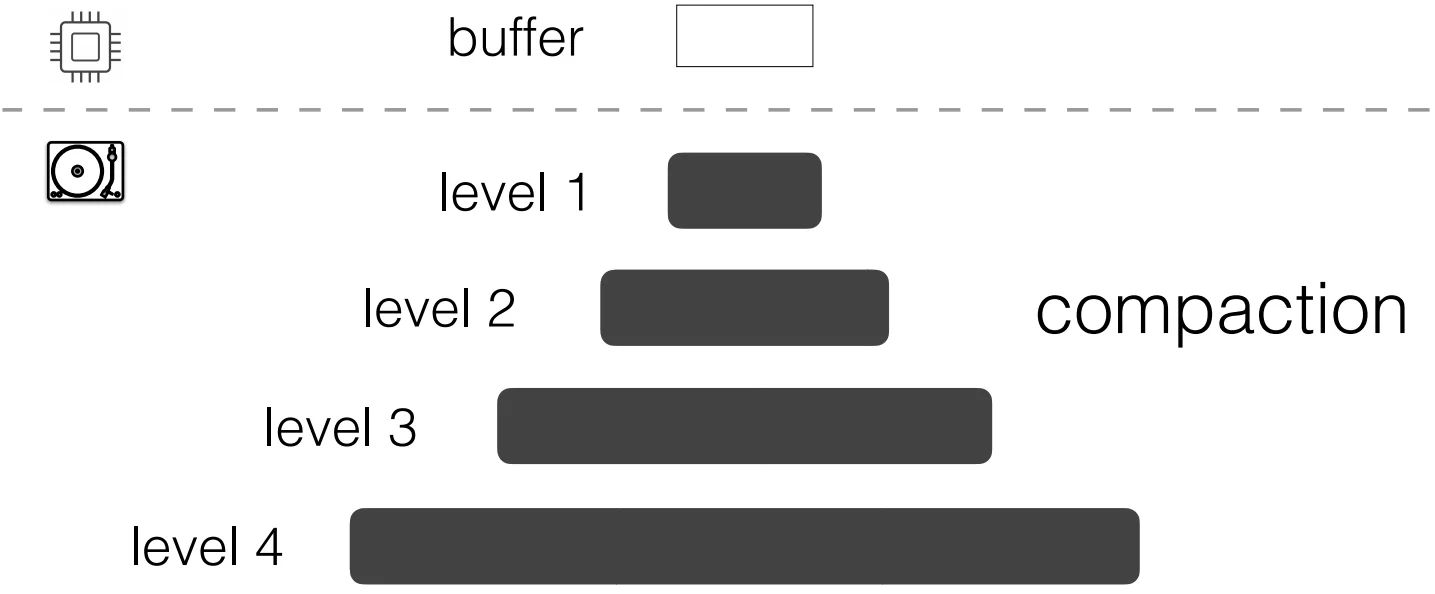
LSM-Tree的基本结构:数据从内存逐级下沉到磁盘各层 图片来源: Compactionary - BU DISC Lab
三种放大的数学本质
在深入Compaction策略之前,必须理解三个核心概念:写放大、读放大和空间放大。这三者构成了LSM-Tree性能的"不可能三角"——你不可能同时优化全部三个指标。
写放大(Write Amplification)
$$WA = \frac{\text{实际写入磁盘的字节数}}{\text{用户写入的字节数}}$$写放大描述的是:为了存储1字节的用户数据,磁盘实际写入了多少字节。在LSM-Tree中,同一份数据可能在Compaction过程中被反复重写。
以RocksDB默认的Leveled Compaction为例,假设层级间的放大因子(fanout)为10,共7层,那么写放大约为:
$$WA \approx n \times T^{1/n}$$其中n是层数,T是总放大倍数。当T=1000(数据量是MemTable的1000倍)时,最优层数约为$\ln(1000) \approx 7$,每层放大因子约为$e \approx 2.7$。但RocksDB默认使用10作为放大因子,因此写放大更高。
实际测量中,RocksDB在默认配置下写放大通常在10-50倍之间。这意味着写入1GB数据,磁盘可能要写入10-50GB。
读放大(Read Amplification)
$$RA = \text{查找一个key需要的磁盘I/O次数}$$读放大描述的是:为了找到一个key,需要访问多少个SSTable。在没有布隆过滤器的最坏情况下,需要检查每一层的SSTable。
Leveled Compaction的设计目标是最小化读放大:每层只有一个有序的run(可能分成多个文件),因此每层最多只需检查一个文件。
空间放大(Space Amplification)
$$SA = \frac{\text{实际磁盘占用}}{\text{逻辑数据大小}}$$空间放大描述的是:为了存储有效数据,额外占用了多少空间。这包括:
- 同一key的多个版本
- 墓碑标记(已删除但未清理的数据)
- Compaction过程中临时的双份数据
Leveled Compaction的空间放大很低,通常在10%-50%之间。而Tiered Compaction的空间放大可能高达100%-200%。
Leveled vs Tiered:两种哲学的碰撞
LSM-Tree的Compaction策略主要分为两大流派:Leveled Compaction(层级合并)和Tiered Compaction(分层合并)。这两种策略代表了两种截然不同的设计哲学。
Leveled Compaction:读优先的设计
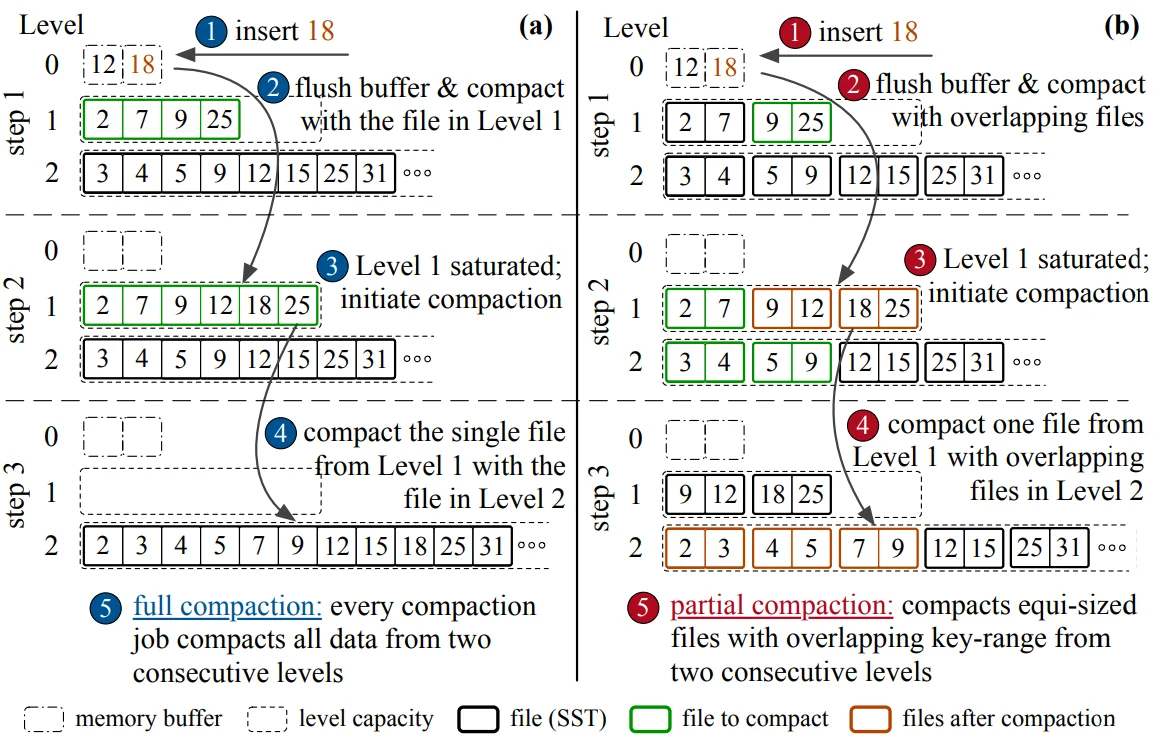
Leveled Compaction最早由LSM-Tree原始论文提出,被LevelDB和RocksDB采用。其核心思想是:每一层维护一个有序的run,通过持续合并来保持这个不变量。
工作流程如下:
- MemTable刷入L0,L0的SSTable之间可能有重叠
- 当L0文件数达到阈值(默认4个),选择文件与L1合并
- L1的每个文件与L2中key范围重叠的文件合并
- 以此类推,逐层下沉
每层的容量是上一层的T倍(T通常为10)。当L1达到容量上限时,数据会被"挤出"到L2。

Leveled Compaction的结构:每层维护一个不重叠的有序文件集合 图片来源: Fjall Blog - Leveled Compaction
优势:读放大极低。每层最多检查一个文件,加上布隆过滤器,点查询通常只需1-2次磁盘I/O。空间放大也很低,通常不超过10%。
代价:写放大较高。每次合并都需要读取和重写下一层的大量数据。假设放大因子T=10,一次L1→L2的Compaction可能需要重写10倍的L1数据。
Tiered Compaction:写优先的设计
Tiered Compaction采用完全不同的策略:允许每层存在多个run,只有当run数量达到阈值时才触发合并。
工作流程如下:
- MemTable刷入L0,成为一个新的run
- 当L0的run数达到阈值(默认4个),将这4个run合并成一个新的run放入L1
- 当L1的run数达到阈值,合并后放入L2
- 以此类推
优势:写放大极低。每次合并只涉及当前层的run,不需要与下一层合并。理论上,每层数据只被重写一次,写放大约为O(L),其中L是层数。
代价:读放大和空间放大都较高。同一key可能存在于多个run中,读取时需要检查更多文件。空间放大可能达到50%-100%,因为大量旧版本数据在被合并前一直存在。
Leveled vs Tiered的对比:前者每层一个run,后者每层多个run 图片来源: Compactionary - BU DISC Lab
数值对比:一个具体的例子
假设总数据量1TB,MemTable大小64MB,层数7:
| 指标 | Leveled Compaction | Tiered Compaction |
|---|---|---|
| 写放大 | 30-50x | 7x(等于层数) |
| 读放大 | 7次I/O(每层一次) | 可能需要检查数十个run |
| 空间放大 | 10-20% | 50-100% |
这个对比揭示了一个深刻的事实:没有完美的Compaction策略,只有特定场景下的最优选择。
生产实践:各大数据库的选择
理论分析之外,真实世界的Compaction策略选择更加复杂。让我们看看主流数据库是如何权衡的。
RocksDB:Leveled为主,Tiered为辅
RocksDB默认采用Leveled Compaction,但提供了丰富的配置选项:
compaction_style = kCompactionStyleLevel // 默认
RocksDB的Compaction实现有几个关键优化:
部分合并(Partial Compaction):不是合并整层,而是选择部分文件与下一层重叠文件合并。这降低了单次Compaction的开销,但也带来了设计复杂性——需要决定选择哪些文件。
子合并(Subcompaction):对于大文件,可以在内部并行执行多个合并任务。这对于多核CPU非常友好。
Write Stalls机制:当Compaction跟不上写入速度时,主动降低写入速率。触发条件包括:
- L0文件数达到
level0_slowdown_writes_trigger(默认20) - 待Compaction字节数达到
soft_pending_compaction_bytes(默认64GB)
// Write Stall的典型日志
Stalling writes because we have 20 level-0 files
Stopping writes because we have 36 level-0 files
这种设计反映了RocksDB的核心理念:宁可慢一点,也不要让系统崩溃。但对于延迟敏感的应用,这种"慢"可能是不可接受的。
Cassandra:Size-Tiered为主,Time-Window为辅
Cassandra的默认Compaction策略是SizeTieredCompactionStrategy(STCS),这是一种Tiered Compaction的变体。
STCS的工作原理:
- 将大小相近的SSTable分组(bucket)
- 当一个bucket中的SSTable数量达到
min_threshold(默认4)时触发合并 - 选择"最活跃"的bucket进行合并
STCS非常适合写入密集型场景,但有一个致命缺陷:随着数据积累,SSTable数量持续增长,读性能持续下降。在大型集群上,可能出现上千个SSTable的情况。
针对时序数据场景,Cassandra引入了TimeWindowCompactionStrategy(TWCS):
CREATE TABLE metrics (
sensor_id int,
timestamp timestamp,
value double,
PRIMARY KEY (sensor_id, timestamp)
) WITH compaction = {
'class': 'TimeWindowCompactionStrategy',
'compaction_window_size': '1',
'compaction_window_unit': 'HOURS'
};
TWCS的核心思想是:将SSTable按时间窗口分组,同一窗口内的SSTable才会被合并。对于TTL数据,这种策略完美契合——旧数据到期后可以直接删除整个SSTable,无需Compaction。
什么时候用哪种策略?
这是一个没有标准答案的问题,但有一些经验法则:
| 场景 | 推荐策略 | 理由 |
|---|---|---|
| 写入密集、读取较少 | Tiered | 最小化写放大 |
| 读取密集、随机查询 | Leveled | 最小化读放大 |
| 时序数据、TTL数据 | TWCS | 时间局部性优化 |
| 空间敏感 | Leveled | 最小化空间放大 |
| 写入和读取都密集 | Hybrid | 平衡权衡 |
Compaction的最新研究方向
学术界和工业界都在持续探索更好的Compaction策略。以下是几个值得关注的方向。
混合策略:Tiered+Leveled
RocksDB的默认配置实际上是一种混合策略:L0使用Tiered(因为文件数少,重叠不可避免),L1及以下使用Leveled。
2018年的Dostoevsky论文提出了更精细的混合策略:Lazy Leveling。核心思想是:只有最大层使用Leveled,其他层使用Tiered。这在不显著增加读放大的情况下,将写放大降低了约50%。
自适应Compaction
Compaction策略的选择不应该是一成不变的。当工作负载从写入密集变为读取密集时,系统应该自动调整策略。
2025年的EcoTune论文提出了一个基于强化学习的自适应框架,能够根据实时的工作负载特征,动态调整Compaction参数。实验显示,这种方法在混合工作负载下,比静态配置提升了20-40%的吞吐量。
KV分离:减少不必要的重写
对于大Value场景,传统的Compaction会造成严重的写放大:每次合并都要移动大Value,即使Key没有变化。
WiscKey(2016年FAST会议)提出了KV分离的设计:Key存储在LSM-Tree中,Value存储在独立的日志文件中。Compaction只处理Key,Value通过垃圾回收机制清理。这种设计将写放大降低了几个数量级。
RocksDB的BlobDB就是这一思想的实现。但KV分离也有代价:读取需要额外的随机I/O,空间管理更复杂。
回到现实:如何调优Compaction?
理论分析之外,实际调优Compaction需要关注几个关键指标:
监控指标:
compaction_pending_bytes:待Compaction的数据量num_running_compactions:正在运行的Compaction任务数stall_micros:Write Stall的累计时间write_amp:实际的写放大倍数
常见问题和解决方案:
问题1:Write Stall频繁触发
- 原因:Compaction速度跟不上写入速度
- 解决:增加
max_background_jobs(更多线程)、增大write_buffer_size(更大MemTable)、调整level0_slowdown_writes_trigger
问题2:L0文件数持续增长
- 原因:L0→L1的Compaction被阻塞
- 解决:启用L0内部合并(Intra-L0 Compaction)、增大L1容量
问题3:空间放大过高
- 原因:Tiered Compaction的特性
- 解决:手动触发Major Compaction、考虑切换到Leveled
问题4:Compaction抖动严重
- 原因:单次Compaction数据量过大
- 解决:减小
target_file_size_base、启用子合并
// 一个典型的RocksDB Compaction调优配置
options.write_buffer_size = 64 * 1024 * 1024; // 64MB MemTable
options.max_write_buffer_number = 4; // 最多4个MemTable
options.level0_file_num_compaction_trigger = 4; // L0达到4个文件触发合并
options.level0_slowdown_writes_trigger = 20; // L0达到20个文件开始减速
options.level0_stop_writes_trigger = 36; // L0达到36个文件停止写入
options.max_background_jobs = 8; // 8个后台线程
options.compaction_style = kCompactionStyleLevel;
结语:没有银弹,只有权衡
Compaction策略的设计,本质上是在回答一个问题:你愿意为什么付出代价?
如果你选择最小化写放大,就必须接受更高的读放大和空间放大。如果你选择最小化读放大,就必须接受更高的写放大。如果你想同时优化两者,就需要引入更复杂的机制(如KV分离、自适应策略),这又带来了新的复杂性和维护成本。
这种权衡不是LSM-Tree的缺陷,而是其设计的必然结果。正是因为有了Compaction这个"后台清理工",LSM-Tree才能在写入性能上达到极致。理解Compaction,就是理解如何在"不可能三角"中找到适合自己的位置。
正如Niv Dayan在Dostoevsky论文中所说:“The LSM-tree design space is a continuum, not a dichotomy."(LSM-Tree的设计空间是一个连续体,而非二元对立。)从纯粹的Tiered到纯粹的Leveled,中间有无数种可能的配置。找到最适合你工作负载的那一种,就是数据库调优的艺术。
参考文献
- O’Neil, P., Cheng, E., Gawlick, D., & O’Neil, E. (1996). The Log-Structured Merge-Tree (LSM-Tree). Acta Informatica, 33(4), 351-385.
- Dayan, N., & Idreos, S. (2018). Dostoevsky: Better Space-Time Trade-Offs for LSM-Tree Based Key-Value Stores via Adaptive Removal of Superfluous Merging. SIGMOD.
- Sarkar, S., et al. (2021). Constructing and Analyzing the LSM Compaction Design Space. VLDB.
- RocksDB Wiki. Compaction. https://github.com/facebook/rocksdb/wiki/Compaction
- RocksDB Wiki. Write Stalls. https://github.com/facebook/rocksdb/wiki/Write-Stalls
- Apache Cassandra Documentation. Compaction. https://cassandra.apache.org/doc/latest/cassandra/managing/operating/compaction/
- The Last Pickle Blog. TWCS part 1 - how does it work and when should you use it? https://thelastpickle.com/blog/2016/12/08/TWCS-part1.html
- Lu, L., et al. (2016). WiscKey: Separating Keys from Values in SSD-conscious Storage. FAST.
- Small Datum Blog. LSM math: revisiting the number of levels that minimizes write amplification. http://smalldatum.blogspot.com/2019/01/lsm-math-revisiting-number-of-levels.html
- Fjall Blog. An overview of Leveled Compaction in LSM-trees. https://fjall-rs.github.io/post/lsm-leveling/