2012年9月,Netflix开源了一个名为Eureka的项目。这不是一个全新的技术发明,而是一个针对AWS云环境的妥协产物。然而,这个妥协引发了微服务社区长达十年的争论:服务注册中心到底应该优先保证一致性还是可用性?
争论的核心指向一个被反复引用却鲜少被正确理解的理论——CAP定理。在分布式系统的设计天平上,服务发现组件恰好站在了最尴尬的位置:它既要承担"目录服务"的基础设施职责,又要面对云环境中网络分区的常态。正是这个定位,让不同厂商做出了截然不同的技术选择。
一个被误解的理论,一场持续十年的分裂
CAP定理常被简化为"三选二",但这种理解在服务发现领域尤其危险。Eric Brewer在2000年提出这个定理时,讨论的是在网络分区发生时的极端情况下的取舍,而非系统常态下的设计目标。
更关键的是,分区容错(Partition Tolerance)在网络环境中不是选择题,而是必选项。真正需要权衡的,只有一致性(Consistency)和可用性(Availability)之间的抉择。
CP系统的承诺:当网络分区发生时,系统可能拒绝响应,以保证任何成功的读取都能获得最新写入的数据。代价是——在分区期间,系统可能完全不可用。
AP系统的承诺:当网络分区发生时,系统继续响应请求,但可能返回过时的数据。代价是——客户端可能获得不准确的服务实例列表。
对于服务发现这个场景,两种选择的后果截然不同:
- CP系统在网络分区时拒绝响应 → 客户端无法获取服务列表 → 整个系统停摆
- AP系统在网络分区时返回过时数据 → 客户端可能访问已下线的实例 → 请求失败,但系统整体仍可用
这正是Netflix选择AP的根源所在。
ZooKeeper的执念与失败
在Eureka出现之前,ZooKeeper几乎是分布式协调的唯一选择。这个诞生于雅虎的项目,最初是为Hadoop生态设计的协调服务,其核心是ZAB协议(ZooKeeper Atomic Broadcast)。
ZAB是一个强一致性的共识协议。它通过Leader选举和原子广播机制,确保所有节点的状态最终一致。在正常情况下,所有写请求都经过Leader,Leader生成提案(Proposal)并广播给Follower,只有当多数节点确认后,提案才会被提交。
这种设计对于配置管理、分布式锁等场景非常合适——你绝对不希望两个节点同时持有同一把锁。但对于服务发现,它暴露了致命的缺陷。
临时节点的陷阱
ZooKeeper通过临时节点(Ephemeral Node)实现服务注册。客户端创建一个临时节点表示服务实例上线,节点携带客户端的会话(Session)。当会话断开——无论是客户端主动下线还是网络故障——临时节点自动被删除。
这个机制听起来完美:服务下线时自动清理注册信息。但在云环境中,它成为了一个灾难。
2014年,一篇题为"Eureka! Why You Shouldn’t Use ZooKeeper for Service Discovery"的文章详细描述了这个问题。当网络分区发生时,ZooKeeper集群可能无法在短时间内选出新的Leader,或者客户端与集群的连接超时。此时:
- 客户端的临时节点被删除(会话超时)
- 客户端尝试重新连接,发现无法连接到Leader
- 客户端尝试重新注册,但注册请求无法被处理(没有Leader)
- 服务实际上仍在运行,但注册信息已丢失
更糟糕的是,ZooKeeper对节点数量的变化极其敏感。当大量服务实例同时下线或上线时,临时节点的创建和删除会触发大量的Watcher通知,可能导致"惊群效应",让整个系统陷入混乱。
会话超时的两难
ZooKeeper的会话超时配置是一个经典的工程两难:
- 设置较短的会话超时(如2秒):对故障响应快,但网络抖动容易误判服务下线
- 设置较长的会话超时(如30秒):容忍网络抖动,但服务真正下线时,注册信息长时间残留
无论怎么选择,都无法完美解决问题。因为在云环境中,网络分区的持续时间是不可预测的。
Eureka的妥协智慧
Netflix的工程师们在AWS环境中深刻体会到了ZooKeeper的局限性。AWS的网络环境比传统数据中心更加动态——实例频繁上下线、自动扩缩容是常态、跨可用区的网络延迟和偶尔的分区故障不可避免。
2012年开源的Eureka,其设计哲学与ZooKeeper截然相反。
AP优先的架构选择
Eureka放弃了强一致性,转而追求最大可用性。其核心设计包括:
点对点复制:Eureka Server之间没有Leader,每个节点都可以接收读写请求。服务注册信息通过异步复制在节点间同步。当某个节点接收到新的注册请求时,它会尝试将信息复制到其他节点,但复制失败不会影响本节点的响应。
客户端优先注册:Eureka客户端只向配置列表中的第一个Server注册。如果该Server不可用,客户端会尝试下一个,直到成功。这种设计避免了Server端的竞争条件。
只读缓存:客户端从Server获取服务列表后,会缓存到本地。后续请求优先使用本地缓存,定期从Server刷新。即使Server完全不可用,客户端仍可使用缓存的列表继续工作(尽管可能过时)。
自保护模式:宁可错信,不可漏判
Eureka最具争议也最具智慧的设计是自保护模式(Self-Preservation Mode)。
当Eureka Server发现最近一分钟收到的心跳数低于预期阈值时(默认期望心跳数的85%),它会进入自保护模式。在该模式下,Server停止清理过期的服务实例,即使这些实例已经停止发送心跳。
自保护模式的计算公式:
$$预期心跳数 = 2 \times N \times 0.85$$其中,$N$是注册的实例数量,每个实例每30秒发送一次心跳(即每分钟2次)。
这个设计的逻辑是:如果大量实例同时停止心跳,更可能是网络问题而非实例故障。在网络恢复前,保留这些"可能存活"的实例比删除它们更安全——因为调用一个已下线的实例只会导致单次请求失败,而删除一个实际存活的实例会导致该实例完全不可达。
当然,自保护模式也有代价:在实例真正大规模故障时,注册列表中会充斥大量无效实例,导致请求失败率上升。但Netflix认为,在AWS环境中,网络问题比大规模实例故障更常见,这个权衡是值得的。
Raft协议与CP系统的新生
虽然Eureka在AWS环境中表现出色,但强一致性系统并未退出历史舞台。2014年,Diego Ongaro和John Ousterhout发表了Raft论文,以一种更易理解的方式实现了分布式共识。
Raft将共识问题分解为三个子问题:Leader选举、日志复制和安全性。其核心思想是:系统中的所有状态变更都通过Leader进行,Leader将操作日志复制到多数节点后提交。
基于Raft的服务发现系统(如etcd和Consul)呈现出与ZooKeeper不同的特性:
etcd:为Kubernetes而生
etcd是CoreOS(后被Red Hat收购)开发的分布式键值存储,专门为Kubernetes设计。作为Kubernetes的核心组件,etcd存储了集群的所有状态信息,包括服务注册信息。
etcd使用Raft协议,提供强一致性保证。每次写入都需要多数节点确认,读取可以配置为强一致或最终一致。
对于Kubernetes而言,强一致性是必要的。因为etcd不仅存储服务注册信息,还存储集群配置、调度状态等关键数据。不一致的调度状态可能导致Pod被调度到已满的节点,或不存在的节点——这些都是不可接受的。
但etcd的强一致性也带来了挑战。在大型集群中,etcd可能成为性能瓶颈。Kubernetes社区为此制定了严格的最佳实践:限制etcd集群规模(通常3或5个节点)、使用SSD存储、控制对象大小等。
Consul:强一致与健康检查的结合
HashiCorp的Consul选择了不同的路径。它同样使用Raft协议保证强一致性,但增加了丰富的健康检查机制。
Consul的架构分为两层:
Gossip层:使用Serf库实现的SWIM协议,用于节点成员管理和故障检测。每个节点定期随机选择其他节点交换状态信息,消息在节点间传播。这使得故障检测更加快速和可靠——一个节点的故障会迅速被多个节点感知。
Raft层:Server节点组成Raft集群,负责服务注册信息的强一致性存储。

这种双层架构让Consul在保持强一致性的同时,实现了快速故障检测。当某个服务实例的健康检查失败时,该信息通过Gossip协议迅速传播,同时Raft集群保证注册信息的一致更新。
Consul还提供了多数据中心支持。不同数据中心的Consul集群通过WAN Gossip连接,实现跨数据中心的服务发现。这对于全球化部署的企业尤为重要。
Nacos:在AP与CP之间切换
阿里巴巴开源的Nacos提供了一个有趣的折中方案:它支持在AP和CP模式之间切换。
Nacos的设计源于阿里巴巴在双11等高并发场景下的实践经验。在某些场景下,强一致性更重要(如配置管理);在另一些场景下,可用性更重要(如服务发现)。
Nacos通过一致性协议选择实现这个目标:
- AP模式:使用Distro协议,每个节点独立处理写入,异步复制到其他节点。适合服务发现场景。
- CP模式:使用Raft协议,写入需要多数节点确认。适合配置管理场景。
这种设计让用户可以根据实际需求选择一致性级别,但也增加了系统的复杂度。用户需要理解两种模式的差异和适用场景,做出正确的选择。
客户端发现与服务端发现
服务发现不仅是注册中心的选择问题,还涉及发现模式的设计。业界主要有两种模式:
客户端发现模式
客户端直接查询服务注册中心,获取可用的服务实例列表,然后根据自己的策略选择一个实例发起调用。
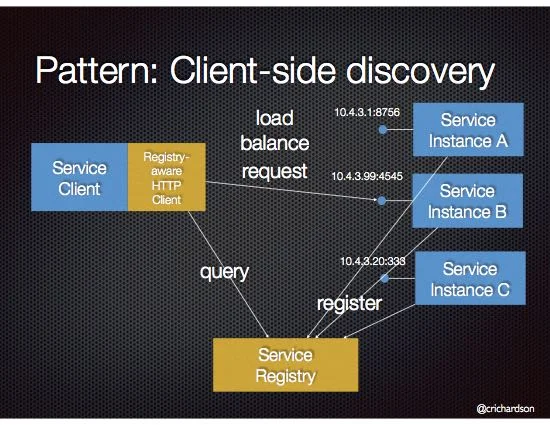
图片来源: microservices.io
这种模式的优势在于:
- 减少网络跳数:客户端直接调用目标实例,无需经过中间代理
- 负载均衡灵活:客户端可以实现任意复杂的负载均衡策略
- 无单点故障:注册中心只提供服务列表,不参与流量转发
缺点也很明显:
- 客户端复杂度增加:每个客户端都需要实现服务发现逻辑
- 语言绑定:不同语言的客户端需要各自的SDK实现
Netflix OSS(Eureka + Ribbon)是这种模式的典型代表。
服务端发现模式
客户端向负载均衡器(或API网关)发送请求,负载均衡器查询服务注册中心,然后将请求转发到选定的实例。
这种模式的优势在于:
- 客户端简单:客户端只需知道负载均衡器的地址
- 语言无关:客户端可以是任何语言,无需特定SDK
- 统一管控:流量策略、安全检查等可以在负载均衡层统一实现
缺点包括:
- 额外跳数:每次请求都经过负载均衡器,增加延迟
- 单点风险:负载均衡器成为系统的关键节点
- 运维复杂:需要额外维护负载均衡基础设施
Kubernetes的Service + kube-proxy是这种模式的代表。
Kubernetes的混合方案
有趣的是,Kubernetes实际上结合了两种模式:
DNS服务发现:CoreDNS为每个Service创建DNS记录,客户端可以通过域名(如my-service.default.svc.cluster.local)访问服务。DNS解析返回Service的ClusterIP,这是服务端发现的入口。
kube-proxy负载均衡:每个节点运行kube-proxy,通过iptables或IPVS规则,将ClusterIP的流量转发到后端Pod。这是服务端发现的核心。
环境变量注入:Kubernetes还会为每个Service注入环境变量,包含Service的地址和端口。这是客户端发现的简化形式。
直接API查询:高级应用可以直接查询Kubernetes API获取EndpointSlice信息,实现更精细的控制。这是客户端发现的高级形式。
graph LR
A[客户端Pod] --> B[CoreDNS]
B --> |DNS解析| C[ClusterIP]
A --> |直接访问| C
C --> D[kube-proxy]
D --> |iptables/IPVS| E[后端Pod]
A -.-> |可选: API查询| F[Kubernetes API]
F -.-> |EndpointSlice| A
这种混合方案让Kubernetes能够适应不同的使用场景:简单的应用使用DNS + Service,复杂的系统可以使用直接API查询实现更精细的控制。
服务网格:发现机制的范式转移
2016年1月,Linkerd作为第一个服务网格项目发布,创造了"服务网格"(Service Mesh)这个术语。随后Istio在2017年加入,服务发现进入了新的阶段。
在服务网格架构中,服务发现不再是应用代码的关注点。每个服务实例旁边都运行一个Sidecar代理(如Envoy),所有的网络通信都通过这个代理进行。
控制平面(如Istiod)负责:
- 从底层平台(如Kubernetes)获取服务注册信息
- 将信息转换为Envoy可理解的配置
- 通过xDS API推送给所有Sidecar代理
数据平面(Envoy)负责:
- 接收xDS配置更新
- 维护本地服务发现信息
- 执行负载均衡、重试、熔断等策略
- 处理实际的网络请求
这种架构将服务发现的复杂性完全从应用代码中剥离。开发者不再需要关心服务发现的细节——调用其他服务就像调用本地函数一样简单。
服务网格还带来了新的可能性:
统一的可观测性:所有流量都经过代理,可以自动生成拓扑图、指标和追踪信息
统一的安全策略:自动mTLS、细粒度的访问控制
统一的流量管理:金丝雀发布、故障注入、流量镜像
但服务网格并非没有代价。Sidecar代理增加了资源消耗(每个实例额外几十MB内存),请求经过额外的网络跳(本地代理),配置传播存在延迟(控制平面到数据平面)。
从历史看未来
回顾服务发现的十五年演进,一条清晰的脉络浮现:
第一阶段(2008-2012):ZooKeeper时代。人们尝试用通用的分布式协调系统解决服务发现问题,发现强一致性与服务发现场景的不匹配。
第二阶段(2012-2017):分裂时代。Netflix的AP方案(Eureka)和各类CP方案(etcd、Consul、ZooKeeper)并存,用户根据自身场景选择。
第三阶段(2017-至今):融合时代。Kubernetes成为事实标准,服务网格将服务发现下沉到基础设施层,应用层几乎不再感知服务发现的存在。
这种演进反映了分布式系统设计的一个深层规律:当一个问题足够普遍时,它终将从应用层下沉到基础设施层。服务发现经历了这个下沉过程,而今天,它已经成为了云原生基础设施的"水电煤"。
选择哪个方案?这个问题在2020年代已经有了相对明确的答案:
- 如果使用Kubernetes:使用内置的Service + CoreDNS,必要时配合服务网格
- 如果是传统环境:Consul是平衡功能和复杂度的较好选择
- 如果是Spring Cloud技术栈:Nacos或Eureka与生态集成更好
无论选择哪个方案,理解其背后的权衡——AP还是CP,客户端发现还是服务端发现——才能在问题出现时做出正确的判断。毕竟,分布式系统的世界里,没有完美的方案,只有适合场景的权衡。
参考资料:
- Netflix OSS Wiki - Eureka at a Glance: https://github.com/Netflix/eureka/wiki/Eureka-at-a-glance
- CAP Theorem - Eric Brewer: https://en.wikipedia.org/wiki/CAP_theorem
- “Eureka! Why You Shouldn’t Use ZooKeeper for Service Discovery”: https://medium.com/knerd/eureka-why-you-shouldnt-use-zookeeper-for-service-discovery-4932c5c7e764
- Raft Consensus Algorithm: https://raft.github.io/
- Consul Architecture - HashiCorp: https://developer.hashicorp.com/consul/docs/architecture
- Nacos Architecture: https://nacos.io/en-us/docs/v2/architecture.html
- Kubernetes Virtual IPs and Service Proxies: https://kubernetes.io/docs/reference/networking/virtual-ips/
- Istio Architecture: https://istio.io/latest/docs/ops/deployment/architecture/
- The History of the Service Mesh: https://thenewstack.io/history-service-mesh/
- Microservices.io - Client-side Discovery Pattern: https://microservices.io/patterns/client-side-discovery