监控大屏上,API的平均响应时间稳定在50毫秒左右,一切看起来运行良好。直到用户投诉开始涌入——“页面加载好慢”、“请求经常超时”。你打开日志,发现大量请求耗时超过2秒,有些甚至超过5秒。平均值没有撒谎,但它也没有告诉你完整的故事。
这不是偶发事件,而是分布式系统中的常态。平均延迟掩盖了尾部延迟的存在,而这个"长尾"正在悄悄侵蚀用户体验和系统可靠性。
P99延迟:最被误解的性能指标
P99延迟(99th Percentile Latency)是一个统计学术语,表示99%的请求响应时间都低于这个值。如果P99延迟是200毫秒,意味着每100个请求中,有99个在200毫秒内完成,只有最慢的1个可能超过这个值。
这个指标为什么重要?因为在大规模系统中,1%的请求可能对应着数万甚至数百万次用户交互。如果服务每天处理1亿次请求,1%的慢请求就是100万次糟糕的用户体验。更重要的是,这些慢请求往往暴露了系统中最深层的瓶颈。
平均值之所以危险,是因为它被快速请求"稀释"了。假设100个请求中,99个在10毫秒内完成,但最慢的一个花了2秒。平均值是(99×10 + 2000)/100 = 29.9毫秒,看起来很健康。但P99是2000毫秒,这才是用户实际感受到的"最差情况"。
Azul Systems的CTO Gil Tene在其经典演讲"How NOT to Measure Latency"中展示了一组数据:对于大多数网页,用户在一次访问中体验到P99延迟的概率超过50%。P99延迟在大规模系统中不是"罕见事件",而是大多数用户都会遇到的现实。
延迟放大:为什么微服务让问题更严重
理解尾延迟的关键是理解"延迟放大"(Latency Amplification)效应。这在微服务架构中尤为明显。
假设一个请求需要并行调用10个后端服务,每个服务的P99延迟都是100毫秒。整体请求的P99是多少?直觉可能告诉你还是100毫秒左右,但数学告诉我们一个残酷的真相。
整体请求必须等待所有子请求完成。如果每个子请求有1%的概率超过100毫秒,那么至少有一个子请求超过100毫秒的概率是:
P(至少一个超时) = 1 - (1-0.01)^10 ≈ 9.5%
这意味着整体请求的P90延迟就已经超过100毫秒了。要计算整体P99延迟,需要找到一个时间T,使得所有子请求都在T内完成的概率达到99%:
(1 - P(子请求超时))^10 = 0.99
解得P(子请求超时) ≈ 0.1%,对应的百分位是P99.9。换句话说,要保证整体P99在100毫秒内,每个子服务的P99.9延迟必须在100毫秒内。
这就是延迟放大的数学本质。Paul Cavallaro在其博客中推导了一个通用公式:当父请求扇出到N个子请求时,要达到父请求的P percentile,子请求需要达到的百分位是:
P_child = (P_parent)^(1/N)
例如,扇出到100个子请求,要达到父请求的P90延迟,子请求需要达到P90^(1/100) ≈ P99.9。
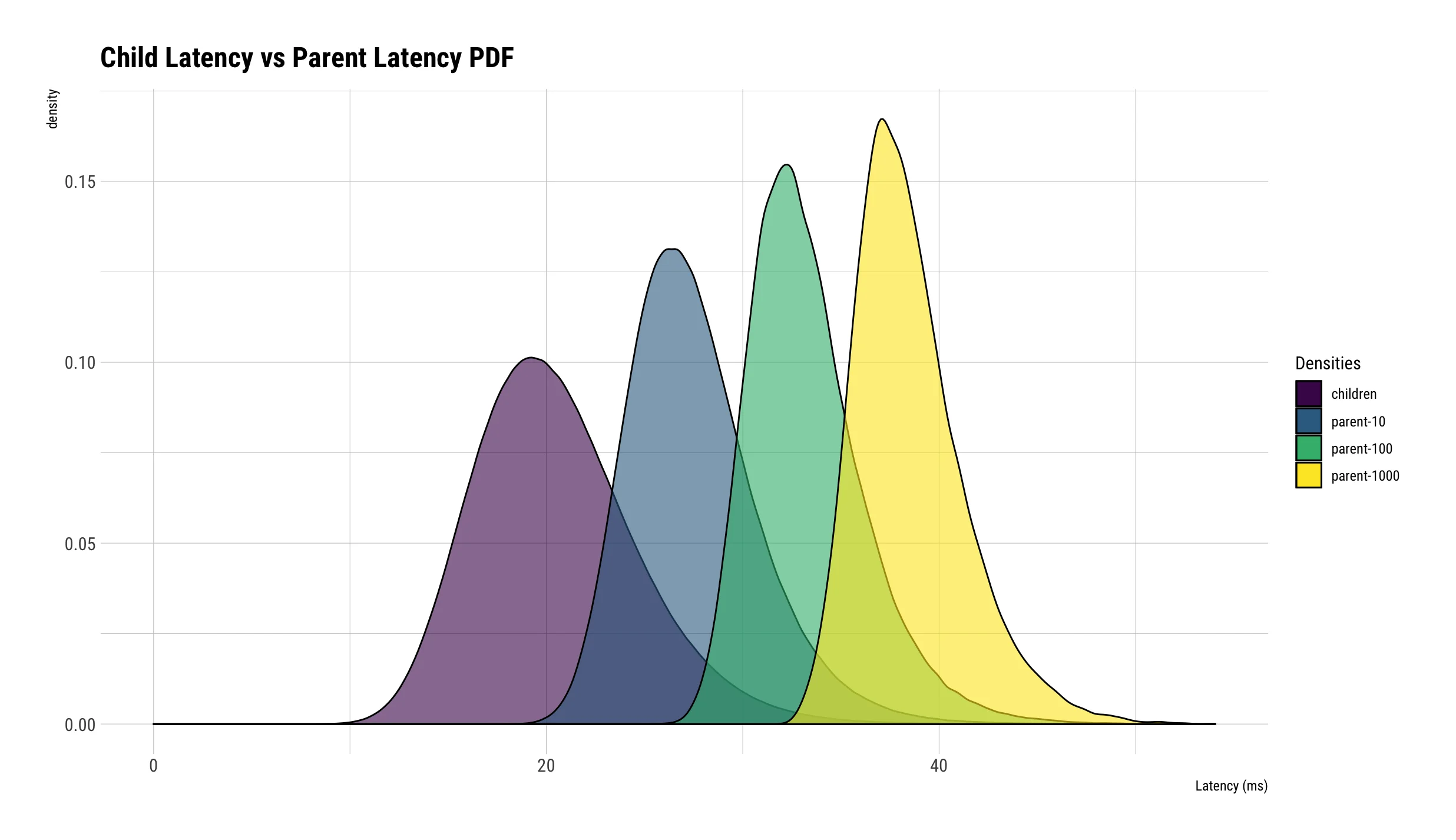
图片来源: paulcavallaro.com
{kind=link}
上图展示了不同扇出规模下的延迟分布变化。当扇出规模从10增加到1000时,父节点的延迟分布急剧恶化,几乎完全由子节点的尾延迟主导。
Google在2013年发表的《The Tail at Scale》论文中给出了一个真实案例:一个大规模扇出服务中,单个叶子节点的P99延迟是10毫秒,但所有叶子节点的P99延迟是140毫秒——等待最慢的5%请求完成,贡献了P99延迟的一半。
尾延迟的六大来源
理解延迟放大后,下一个问题是:这些慢请求从何而来?Jeff Dean和Luiz Barroso在论文中系统梳理了尾延迟的主要来源。
共享资源竞争
现代数据中心是资源共享的环境。同一台物理机上可能运行着多个应用,它们竞争CPU核心、处理器缓存、内存带宽和网络带宽。即使你的应用代码完美无瑕,也可能因为邻居应用的资源消耗而变慢。
更隐蔽的是应用内部的资源竞争。不同请求可能争夺同一个线程池、数据库连接池或内存缓冲区。当某个请求触发了一条慢查询,后续所有请求都得排队等待。
守护进程和后台任务
操作系统和各种运行时环境会定期执行后台任务:日志轮转、监控数据采集、定时任务触发。这些任务在平均意义上消耗很少资源,但在执行瞬间可能造成毫秒级的停顿。
对于追求极致低延迟的系统,即使是1毫秒的停顿也可能是不可接受的。Google发现,在某些服务中,后台活动是尾延迟的主要贡献者之一。
全局资源共享
跨机器的全局资源同样会引发竞争。网络交换机、共享文件系统、分布式锁服务——任何一个成为热点,都会在系统中产生连锁反应。
分布式文件系统的数据重建、存储系统的日志压缩、垃圾回收语言的周期性GC——这些维护活动可能在某些节点上产生明显的延迟峰值。
垃圾回收停顿
对于使用Java、Go、Python等带有垃圾回收机制的语言,GC停顿是尾延迟的经典来源。传统的Stop-The-World GC会在回收时暂停所有应用线程,停顿时间从几毫秒到几百毫秒不等。
Cassandra用户报告过这样的问题:大部分读操作在2毫秒内完成,但每隔一段时间就会有读操作卡在50毫秒——正好对应Java的GC周期。
现代低延迟GC(如ZGC、Shenandoah)将停顿时间控制在了亚毫秒级别,但代价是更高的CPU开销和更复杂的实现。OpenJDK的ZGC在Java 25中已经实现了近乎无停顿的垃圾回收,最长的GC停顿只有约50微秒。
网络抖动和丢包
分布式系统依赖网络通信,而网络天生是不可靠的。数据包丢失、路由震荡、链路拥塞都会增加延迟。
TCP协议通过重传机制处理丢包,但代价是延迟。一次丢包可能导致数十甚至数百毫秒的额外等待,这取决于TCP的超时配置。如果0.1%的请求遭遇丢包,它们就会成为P99.9延迟的主要贡献者。
AWS在其构建者文库中建议,超时设置应该基于下游服务的延迟百分位。如果希望0.1%的误报率,就应该参考P99.9延迟来设置超时。
SSD内部活动
即使是高性能的SSD存储,也存在延迟波动。SSD需要定期执行垃圾回收和磨损均衡,这些内部活动可能暂时阻塞I/O操作。
研究表明,在高写入负载下,SSD的读延迟波动可能增加100倍。对于依赖本地存储的数据库系统,这是尾延迟的一个重要来源。
Google的尾容忍技术
与其试图消除所有延迟变异源——在大规模系统中这几乎不可能——Google提出了一系列"尾容忍"(Tail-Tolerant)技术,用软件手段掩盖底层的不确定性。
Hedged Requests:对冲请求
最简单的尾容忍技术是对冲请求(Hedged Requests)。客户端首先向首选副本发送请求,如果在一定时间内没有收到响应,就向另一个副本发送相同的请求。最终使用最先返回的结果,取消其他请求。
关键在于"延迟阈值"的设置。Google建议使用P95延迟作为阈值——这样只有约5%的请求会触发对冲,额外的负载增加有限,但P99延迟可以大幅降低。
在一个BigTable基准测试中,读取1000个键值(分布在100个服务器上),对冲请求延迟设为10毫秒时,P99.9延迟从1800毫秒降到了74毫秒,而额外请求只增加了2%。
sequenceDiagram
participant Client
participant Replica1
participant Replica2
Client->>Replica1: Primary Request
Note over Client: Wait 10ms (P95 latency)
Client->>Replica2: Hedged Request
Replica1-->>Client: Response (first)
Client->>Replica2: Cancel
Tied Requests:绑定请求
对冲请求有一个缺点:两个副本可能同时执行相同的请求,造成资源浪费。绑定请求(Tied Requests)通过服务器间的协调来解决这个问题。
客户端同时向两个副本发送请求,每个请求都携带另一个副本的标识。当一个副本开始执行请求时,它会向另一个副本发送取消消息。如果另一个副本的请求还在排队,就可以立即取消。
Google在分布式文件系统中实现这个技术后,在负载较高的场景下,P99.9延迟降低了32%-38%,而额外的磁盘利用率增加不到1%。
Canary Requests:金丝雀请求
对于扇出规模极大的系统(如搜索引擎同时查询数千个分片),一个有问题的请求可能在所有分片上触发错误,导致大规模级联故障。
金丝雀请求的思路是:先向少量(1-2个)分片发送请求,如果它们在预期时间内正常返回,再向剩余分片发送。这类似于煤矿中的金丝雀——先探测危险,再大规模行动。
虽然金丝雀阶段会增加少量延迟(因为要等待第一个响应),但它提供了重要的安全保障。Google的所有大规模扇出搜索系统都使用了这个技术。
微分区和选择性复制
除了请求级别的技术,Google还在系统架构层面做了优化。
微分区(Micro-Partitions)将数据分成比服务器数量更多的分区,然后动态分配给各个服务器。假设平均每台服务器管理20个分区,系统就可以以5%的粒度调整负载。当某台服务器变慢时,可以快速迁移部分分区到其他服务器。
选择性复制(Selective Replication)更进一步。系统检测热点数据,为其创建额外副本,分散读取负载。Google的Web搜索系统会为热门文档创建多个副本,根据查询语言的变化动态调整。
延迟诱导的观察期
有时候,简单地将持续变慢的服务器从服务池中移除,反而能改善整体延迟。这听起来违反直觉——减少了服务能力,怎么会更快?
原因是变慢的服务器会拖累整体请求的尾延迟。将其移除后,剩余服务器分担更多负载,但整体响应可能更加一致。系统继续向观察期的服务器发送"影子请求",监控其延迟,待其恢复后重新加入。
生产环境的实践教训
Netflix、Uber、Lyft等公司在P99 CONF会议上分享了他们的实践经验。
Uber的多层次优化
Uber的工程师Ranjib Dey分享了在微服务中优化尾延迟的经验。他们从两个层面入手:
微观层面:JVM和Go的GC调优、并发配置优化、线程池大小调整。
宏观层面:架构层面的改进——一致性级别选择、缓存策略、分片方案。
一个关键发现是,简单地增加线程数并不总能改善延迟。当线程数超过CPU核心数时,上下文切换的开销会增加延迟波动。
Lyft的特征存储优化
Lyft的Bhanu Renukuntla讲述了他们优化在线特征存储P99延迟的经历。核心挑战是为实时推荐系统提供低延迟的特征查询。
他们发现数据模型的选择对尾延迟有巨大影响。将高频访问的特征单独存储、使用内存缓存预热、合理设置压缩算法——这些看似微小的决策,累积起来可以将P99延迟降低一个数量级。
Netflix的全局性能工程
Netflix的Prasanna Vijayanathan介绍了他们如何构建全球规模的高性能应用。关键策略包括:
使用数据进行决策:Netflix建立了详细的性能模型,预测不同地区的用户体验。
边缘计算:将部分计算推向离用户更近的位置,减少网络延迟的不确定性。
优雅降级:当某些组件变慢时,优先保证核心功能,而非阻塞等待所有组件。
超时和重试的艺术
AWS构建者文库提供了关于超时和重试的详细指导,这是控制尾延迟的关键手段。
超时设置
设置超时的核心原则是:基于下游服务的延迟分布,而非凭感觉。如果希望0.1%的误报率,就参考P99.9延迟;如果希望1%的误报率,就参考P99延迟。
需要注意的是,超时应该覆盖整个请求链路,包括DNS解析、TLS握手、连接建立等。许多超时配置只覆盖了数据传输阶段,忽略了这些潜在瓶颈。
重试策略
重试是"自私"的——它用服务器资源换取客户端的成功率。在正常情况下这没问题,但当服务器过载时,重试可能加剧问题。
AWS建议:
- 使用指数退避(Exponential Backoff)增加重试间隔
- 添加抖动(Jitter)避免重试请求的同步
- 限制重试次数,避免无限重试
- 考虑使用令牌桶限制重试速率
一个经典的反面案例是:五层服务调用栈,每层独立重试三次。当最底层数据库开始变慢时,实际负载可能放大243倍(3^5),几乎不可能恢复。
可观测性:看见长尾
要优化尾延迟,首先要能看见它。传统的平均值监控会掩盖问题,需要专门的观测工具。
百分位指标
Prometheus等监控系统支持直方图指标,可以计算任意百分位的延迟。关键配置是桶(Bucket)的边界——太稀疏会损失精度,太密集会增加存储开销。
典型的延迟监控会追踪P50、P90、P95、P99、P99.9,以及最大值。P50代表"典型体验",P99代表"最差合理体验",P99.9则捕捉极端异常。
分布式追踪
Jaeger、Zipkin等分布式追踪工具可以记录单个请求经过的所有服务,精确识别哪个环节拖慢了整体响应。
追踪数据的聚合分析可以揭示系统性问题:某个服务的P99延迟在特定时间段飙升,可能与定时任务相关;某个数据库查询的尾延迟异常,可能需要索引优化。
延迟热力图
热力图(Heatmap)将延迟分布随时间的变化可视化。不同于单一的百分位数字,热力图展示了完整的分布形态,可以发现平均值监控无法察觉的模式。
Datadog等商业可观测性平台提供了高级的热力图功能,开源方案如Prometheus配合Grafana也可以实现类似效果。
SLO与错误预算
将P99延迟纳入服务级别目标(SLO)是管理尾延迟的有效方式。典型的SLO声明可能是:“P99延迟在200毫秒以内,99.9%的时间内有效”。
错误预算的概念将可靠性量化:如果SLO是99.9%,那么每月大约有43分钟的"预算"可以超标。当预算消耗过快时,团队应该优先处理可靠性问题,而非新功能开发。
这种机制将尾延迟从技术问题转化为管理问题——它不再只是"性能优化",而是"产品交付能力"的一部分。
工程权衡
优化尾延迟不是免费的。每一种技术手段都有代价:
对冲请求增加额外负载,可能放大系统的压力。
绑定请求需要服务器间协调,增加了系统复杂度。
金丝雀请求增加了一次额外往返,对低延迟服务可能不可接受。
微分区增加了元数据管理的开销。
选择性复制消耗更多存储空间,带来一致性问题。
低延迟GC使用更多CPU资源。
工程师需要在延迟、吞吐量、成本、复杂度之间找到平衡。没有完美的解决方案,只有在特定场景下的最佳权衡。
尾声
API响应时间的波动不是bug,而是分布式系统的基本属性。共享资源、网络通信、存储设备——每一个环节都有不确定性,这些不确定性在规模放大后会显著影响用户体验。
理解P99延迟的意义,认识延迟放大的数学原理,掌握尾容忍的技术手段——这些是构建可预测系统的基本功。
平均值告诉你系统"通常"表现如何,P99告诉你系统"真正"表现如何。用户的信任建立在一贯的体验之上,而非偶尔的高光时刻。
参考资料
- Dean, J., & Barroso, L. A. (2013). The Tail at Scale. Communications of the ACM, 56(2), 74-80.
- Cavallaro, P. Fanouts and Percentiles. paulcavallaro.com
- AWS Builder’s Library. Timeouts, retries, and backoff with jitter.
- Aerospike. What Is P99 Latency? Understanding the 99th Percentile of Performance.
- Last9. Tail Latency: Key in Large-Scale Distributed Systems.
- P99 CONF. 20+ Low-Latency Engineering Case Studies: Netflix, Twitter, TikTok, Square, Uber & More.
- Google Research. The Tail at Scale.
- Nguyen, A., et al. (2016). The Tail at Scale: How to Predict It? USENIX HotCloud.
- IBM Community. Kubernetes CPU Throttling: The Silent Killer of Response Time.
- ACM Digital Library. Understanding the Long Tail Latency of TCP in Large-Scale Cloud Networks.
- Tene, G. How NOT to Measure Latency. Strange Loop, 2015.