一个开发者盯着慢查询日志,发现一条耗时3秒的SELECT语句。他熟练地添加了一个索引,查询时间降到50毫秒。第二天,他又用同样的方法解决了另一个慢查询。一个月后,这张表已经积累了12个索引。
然后,奇怪的事情发生了。一次原本应该很快的UPDATE操作,执行时间突然从10毫秒飙升到200毫秒。更诡异的是,某些SELECT查询的执行计划开始变得不稳定——有时使用索引A,有时使用索引B,而两者的性能差异高达一个数量级。
这不是数据库的bug,也不是配置问题。问题的根源在于一个被广泛忽视的技术事实:索引不是免费的性能加速器,而是一种需要持续支付维护成本的存储结构。
写入操作的真实代价
理解索引成本的第一步,是搞清楚数据库在执行INSERT、UPDATE、DELETE时究竟做了什么。
以PostgreSQL的B-tree索引为例。当一个新行被插入表中时,数据库必须完成以下操作:
- 将行数据写入表的主存储结构(堆表)
- 对于表上的每一个索引,找到正确的插入位置
- 在索引的叶子节点中插入新的键值对
- 如果叶子节点已满,执行页分裂(Page Split)
- 如果页分裂导致父节点溢出,递归向上分裂
关键在于步骤2到5必须对每个索引重复执行。如果一张表有10个索引,一次INSERT操作实际上触发了11次写入(1次堆表写入 + 10次索引写入)。
2026年1月,PostgreSQL核心贡献者Hubert Lubaczewski(depesz)发表了一项系统性基准测试,量化了这一开销。测试使用一张21列的表(1列主键 + 20列数据),分别测试0到21个索引时的数据加载性能:
| 索引数量 | 总大小(MB) | 加载时间(ms) | 加载速度(kB/s) |
|---|---|---|---|
| 0 | 190.8 | 2,500 | 78,139 |
| 1 | 212.2 | 3,552 | 61,176 |
| 5 | 307.7 | 16,781 | 18,777 |
| 10 | 427.3 | 35,031 | 12,489 |
| 21 | 688.5 | 77,731 | 9,069 |
数据揭示了一个反线性关系:当表的总大小增加约3.6倍(从190MB到688MB),写入性能下降了约8倍。这意味着索引的写入开销不是简单的线性累加,而是存在放大效应。
放大效应的来源是页分裂。当B-tree节点填满时,数据库必须将节点分裂为两个,这涉及:
- 分配新的磁盘页
- 复制约一半的数据到新页
- 更新父节点的指针
- 可能触发更上层的分裂
随着索引数量增加,页分裂的概率和频率也随之上升,形成恶性循环。
UPDATE和DELETE的特殊性
UPDATE操作的成本更高,尤其是当更新涉及索引列时。数据库实际上执行的是一次DELETE加一次INSERT:
UPDATE users SET email = '[email protected]' WHERE id = 100;
如果email列上有索引,数据库必须:
- 从索引中删除旧的
email条目 - 在索引中插入新的
email条目
这两次操作都可能触发页分裂或页合并。更重要的是,UPDATE操作在索引层面产生的写入量可能远大于表层面。
DELETE操作同样不"便宜"。虽然删除本身只是标记行为(在MVCC架构中),但VACUUM进程最终必须清理索引中的废弃条目,这同样消耗I/O和CPU。
缓冲池的无形竞争
写入开销只是故事的一部分。索引的另一重隐形成本在于内存占用。
现代数据库都使用缓冲池(Buffer Pool)来缓存热点数据页。PostgreSQL称之为Shared Buffers,MySQL/InnoDB直接称为Buffer Pool,SQL Server则叫做Buffer Cache。无论名称如何,核心机制相同:有限的内存空间必须在表数据和索引数据之间分配。
假设数据库分配了4GB的缓冲池,而一张表有1GB数据和5GB索引(包含主键和多个二级索引)。在冷启动状态下,所有数据都需要从磁盘加载。随着查询执行,缓冲池逐渐被填充——问题是,填充的是什么?
如果一个高频查询只需要扫描主键索引,那么这1GB的表数据会占据缓冲池的相当比例。但如果系统同时在维护多个很少使用的二级索引,这些索引的页也会被加载到缓冲池中(因为写入操作必须更新它们),挤占宝贵的内存空间。
这导致了一个容易被忽视的性能问题:缓冲池命中率下降。
当缓冲池命中率从95%下降到85%时,意味着10%的数据请求需要访问磁盘。对于随机I/O,这可能导致查询延迟增加一个数量级。
如何量化索引的内存影响
pganalyze工具提出了一个名为Index Write Overhead的指标,用于估算索引维护的I/O成本:
索引写入开销 = 索引条目大小 / 行大小 × 部分索引选择性
对于一个简单的示例:
CREATE TABLE users (
id bigserial PRIMARY KEY,
email text,
organization_id bigint
);
CREATE INDEX ON users (organization_id);
假设列的平均宽度为:id=8字节,email=20字节,organization_id=8字节。
- 索引条目大小 = 8(头部) + 8(organization_id) = 16字节
- 行大小 = 23(头部) + 4(指针) + 8 + 20 + 8 = 63字节
- 索引写入开销 = 16 / 63 ≈ 0.25
这意味着:每向表写入1字节,该索引就需要额外写入约0.25字节。如果有5个类似的索引,写入放大就达到了1.25倍——还没有考虑页分裂的开销。
优化器的选择困境
索引数量增加带来的另一个问题是:查询优化器的决策变得更加困难。
数据库的查询优化器使用成本模型来评估不同执行计划的预期代价。成本计算依赖于两个核心输入:
- 基数估计(Cardinality Estimation):预测每个操作会返回多少行
- 选择性估计(Selectivity Estimation):预测谓词会过滤掉多少比例的行
这两个估计都依赖于统计信息,而统计信息的质量与维护成本之间存在矛盾。
当表上有多个索引时,优化器面临的选择空间急剧扩大。考虑一个简单的场景:
SELECT * FROM orders
WHERE customer_id = 100
AND status = 'PENDING'
AND created_at > '2024-01-01';
假设表上有三个独立的单列索引:idx_customer、idx_status、idx_created。优化器可以:
- 使用
idx_customer,然后过滤其他条件 - 使用
idx_status,然后过滤其他条件 - 使用
idx_created,然后过滤其他条件 - 使用索引合并(Index Merge)
- 直接全表扫描
每个选择的预期成本都不同,而成本估计的准确性取决于统计信息的质量。如果统计信息过时或不够精细,优化器可能选择错误的路径。
一个经典的失败案例是低选择性列上的索引。假设status列只有5个不同的值(PENDING、PROCESSING、SHIPPED、DELIVERED、CANCELLED),每个值大约占20%的行。如果在status上创建索引,优化器可能错误地认为使用该索引是高效的,而实际上:
- 索引扫描需要访问约20%的索引页
- 然后需要回表获取完整的行数据
- 最终的总I/O可能超过全表扫描
这就是为什么索引数量增加会导致执行计划不稳定——优化器有更多机会做出错误决策。
统计信息的维护成本
为了支持优化器做出正确决策,数据库需要维护详细的统计信息,包括:
- 每列的直方图(Histogram)
- 不同值的数量(Distinct Values)
- 列之间的相关性(Correlation)
- 索引的聚簇因子(Clustering Factor)
这些统计信息不是免费的。ANALYZE命令需要扫描表数据,消耗CPU和I/O。在大型表上,完整的统计信息收集可能需要数小时。
因此,很多生产系统配置了自动统计信息收集,但采样比例可能较低(如10%)。这又回到了之前的问题:不精确的统计信息可能导致错误的执行计划。
索引碎片化:性能的慢性杀手
随着时间推移,频繁的插入、更新和删除会导致索引碎片化。
碎片化有两种主要形式:
逻辑碎片化:索引页的逻辑顺序与物理顺序不一致。对于范围扫描,这导致更多的随机I/O。
内部碎片化:索引页内部存在大量空闲空间。这增加了索引的物理大小,降低了缓冲池效率。
SQL Server的官方文档明确指出:在许多工作负载中,增加页密度带来的性能提升,比减少碎片化更显著。
考虑一个例子:一个原本100%填充的页,因为插入操作导致页分裂,变成两个各约50%填充的页。这带来三重影响:
- 索引物理大小翻倍
- 缓冲池中需要缓存更多的页
- 范围扫描需要读取更多的页
碎片化的程度可以用avg_fragmentation_in_percent(逻辑碎片化)和avg_page_space_used_in_percent(页密度)来衡量。
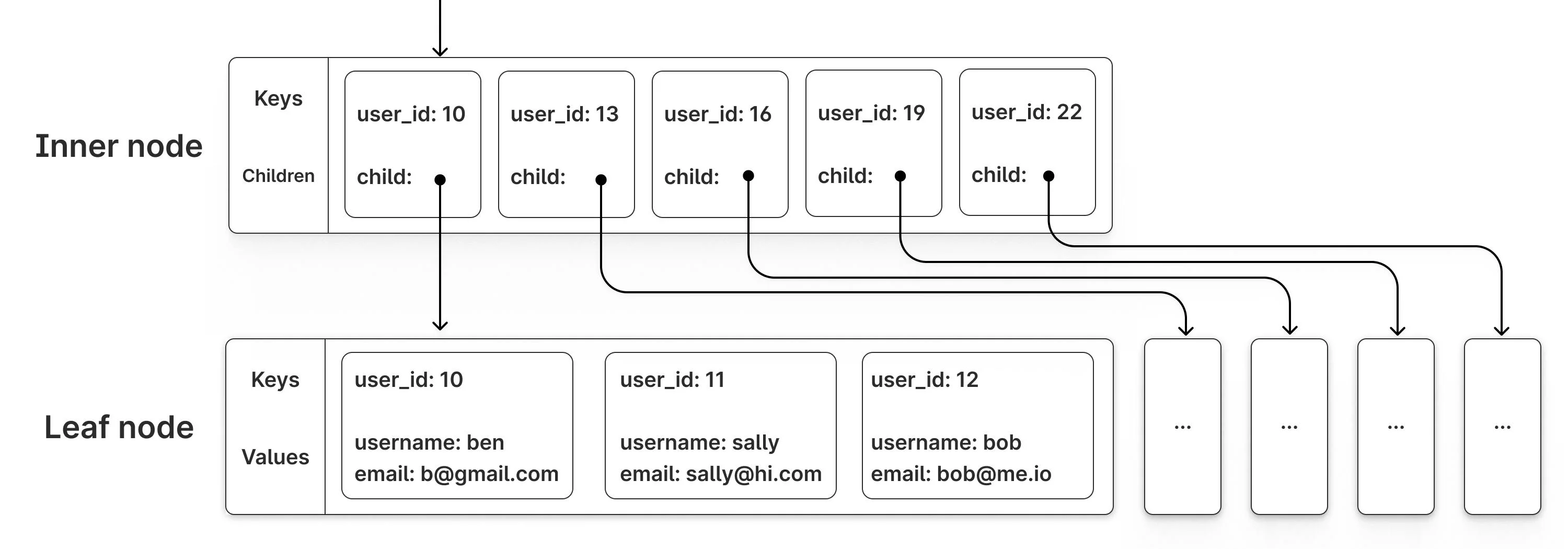
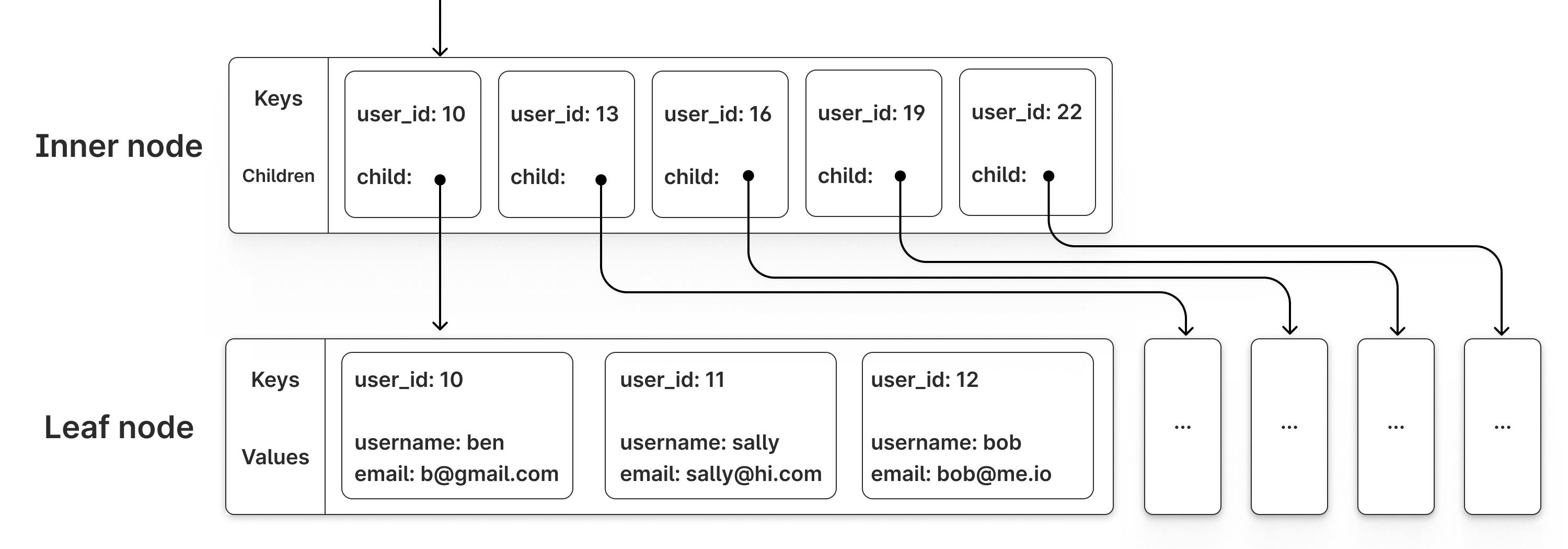{kind=link}
上图展示了B+tree的基本结构。内部节点只存储键和子节点指针,而叶子节点存储完整的键值对。当叶子节点分裂时,两个新节点的填充度各约50%。
索引重建的选择
面对碎片化,有两种主要的维护策略:
重组(REORGANIZE):在线操作,只处理叶子层级的碎片化,资源消耗较低。
重建(REBUILD):完全重新创建索引,可以调整填充因子,但资源消耗较高。
微软的建议是:不要仅基于碎片化阈值来决定维护策略,而应该通过实际测试来验证性能收益。一个关键发现是,很多时候重建索引带来的性能提升,实际上来自于统计信息的更新(重建索引会自动更新统计信息),而非碎片化本身的减少。
写入密集型场景:B-tree vs LSM-tree
对于写入密集型的工作负载,传统B-tree索引的根本性限制开始显现。这催生了另一种索引范式:LSM-tree(Log-Structured Merge-tree)。
TiKV项目的技术文档详细比较了两种数据结构的性能特征:
| 数据结构 | 写入放大 | 读取放大 |
|---|---|---|
| B+tree | Θ(B) | O(log_B(N/B)) |
| LSM-tree | Θ(k·log_k(N/B)) | Θ((log²(N/B))/log k) |
其中B是页大小,N是数据总量,k是LSM-tree的层级增长因子。
核心结论是:LSM-tree的写入性能优于B+tree,而B+tree的读取性能优于LSM-tree。
B+tree的写入放大约为B(页大小),因为每次写入都可能需要更新一个完整的页。LSM-tree的写入放大与层数相关,通过批量合并(Compaction)来摊销写入成本。
这也解释了为什么:
- 传统关系数据库(PostgreSQL、MySQL)使用B+tree,适合读密集或读写均衡的场景
- 时序数据库、日志系统(InfluxDB、Cassandra)使用LSM-tree,适合写入密集的场景
实践指南:如何正确管理索引
基于以上分析,索引管理的核心原则是:索引是权衡(Trade-off),而非免费的优化。
识别无效索引
PostgreSQL提供了pg_stat_user_indexes视图来监控索引使用情况:
SELECT indexrelname, idx_scan, idx_tup_read
FROM pg_stat_user_indexes
WHERE idx_scan = 0 AND idx_tup_read = 0;
idx_scan = 0表示自上次统计重置以来,该索引从未被用于扫描。这些索引是删除的首选候选。
但需要注意:单次快照可能误导。某些索引可能只在月末报表或季度结算时使用。建议在足够长的时间窗口内(如一个完整的业务周期)监控索引使用情况。
评估索引的成本收益
添加索引前,应该回答以下问题:
- 查询频率:该查询的执行频率是多少?
- 性能增益:索引能将查询时间从多少降到多少?
- 写入开销:表的写入频率是多少?新索引会增加多少写入放大?
- 内存压力:新索引会增加多少内存占用?
一个简化的成本收益公式:
收益 = 查询频率 × (原查询时间 - 索引后查询时间)
成本 = 写入频率 × 索引写入开销系数
只有当收益显著超过成本时,索引才是合理的。
复合索引优于多个单列索引
depesz的测试也验证了这一点:一个10列的复合索引,比10个单列索引的写入开销低得多。
复合索引的列顺序设计遵循以下原则:
- 等值谓词列优先:
WHERE a = ? AND b > ?的索引应该是(a, b) - 范围谓词列其次:范围条件之后的列无法用于索引定位
- 排序和覆盖列最后:用于避免排序和回表
-- 对于查询:
SELECT id, status FROM orders
WHERE customer_id = 100
AND created_at > '2024-01-01'
ORDER BY created_at DESC
LIMIT 50;
-- 推荐索引:
CREATE INDEX idx_orders_customer_created
ON orders (customer_id, created_at DESC);
这个索引可以:
- 通过
customer_id快速定位 - 顺序扫描
created_at范围 - 直接返回有序结果,避免排序
部分索引:精确打击
部分索引(Partial Index)只索引满足特定条件的行,可以显著降低维护成本:
CREATE INDEX idx_active_sessions
ON sessions (user_id)
WHERE status = 'ACTIVE';
这个索引只包含活跃会话,维护成本与活跃会话数量成正比。对于状态分布不均匀的场景(如大部分会话已结束),部分索引的效率提升可能达到一个数量级。
延迟索引:批量导入的策略
对于大规模数据导入,标准做法是:
- 创建表结构,但不创建二级索引
- 导入数据
- 创建索引
- 运行
ANALYZE更新统计信息
这种方法的优势在于:索引创建是一次性批量操作,避免了逐行维护索引的开销。对于千万级以上的数据导入,性能差异可能达到10倍以上。
索引并非万能
索引的本质是一种空间换时间的权衡。它用额外的存储空间和持续的维护成本,换取特定查询的加速。
这个权衡只有在正确的场景下才是值得的:
- 读密集型工作负载:索引的收益通常大于成本
- 写密集型工作负载:需要谨慎评估,可能需要选择LSM-tree等替代方案
- 混合工作负载:通过监控和调优找到平衡点
最后,记住一个简单的原则:每个索引都应该能回答一个问题——“这个索引为哪个查询服务?“如果答不上来,这个索引很可能就是负担而非资产。
参考文献
- Lubaczewski, H. (2026). What is index overhead on writes? depesz.com
- pganalyze. Index Write Overhead Documentation.
- TiKV Project. B-Tree vs LSM-Tree Deep Dive.
- Microsoft. Index Maintenance Guide - SQL Server Documentation.
- Winand, M. Use The Index, Luke - Covering Index Chapter.
- Percona. Benchmarking PostgreSQL: The Hidden Cost of Over-Indexing.
- PlanetScale. B-trees and Database Indexes.