1970年7月,波音研究实验室的 Rudolf Bayer 和 Edward McCreight 首次流传了一篇题为"Organization and Maintenance of Large Ordered Indices"的论文,两年后正式发表在 Acta Informatica 期刊。他们发明的 B-tree 在此后五十年里统治了数据库存储引擎的设计。
1996年,Patrick O’Neil 等人在 Acta Informatica 期刊上提出了另一种思路:Log-Structured Merge-tree(LSM-tree)。这篇论文的开篇就直击痛点——对于高插入率的历史表索引,传统 B-tree 会将系统 I/O 成本翻倍。
两种数据结构各领风骚数十年。今天,当你需要为应用选择数据库时,面临的第一个架构决策往往就是:你的数据应该用 B+ 树存储,还是 LSM 树?
这个问题的答案揭示了一个深刻的工程真理:在存储引擎设计中,不存在同时优化读性能、写性能和空间效率的完美方案。
三种放大:存储引擎的性能密码
要理解 B+ 树和 LSM 树的本质差异,必须先理解存储引擎的三个核心指标:
写放大(Write Amplification)
当你向数据库写入 10 MB 数据,却发现磁盘实际写入了 30 MB——这就是写放大为 3。写入 SSD 的次数是有限的,写放大直接影响存储设备的寿命。更重要的是,在机械硬盘上,随机写比顺序写慢一个数量级,写放大会成倍增加 I/O 延迟。
读放大(Read Amplification)
执行一次查询需要读取多少个磁盘页?如果需要读取 5 个页面才能返回结果,读放大就是 5。这个指标决定了查询延迟,尤其是冷数据查询。
空间放大(Space Amplification)
数据库存储了 10 MB 的逻辑数据,却在磁盘上占用了 100 MB——空间放大为 10。这不仅意味着更高的存储成本,还意味着更多的 I/O,更大的备份窗口,更长的恢复时间。
关键洞察:一个数据结构最多只能同时优化其中两项。B+ 树牺牲写性能换取读性能;LSM 树牺牲读性能换取写性能。这不是设计的疏忽,而是物理规律决定的权衡。
B+ 树:为读而生的五十岁老兵
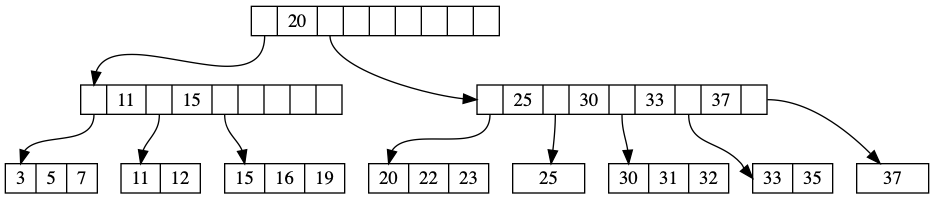
B+ 树是 B-tree 最著名的变体。它的核心设计哲学是:内部节点只存键,叶子节点存键和值,所有叶子节点通过指针串联成链表。
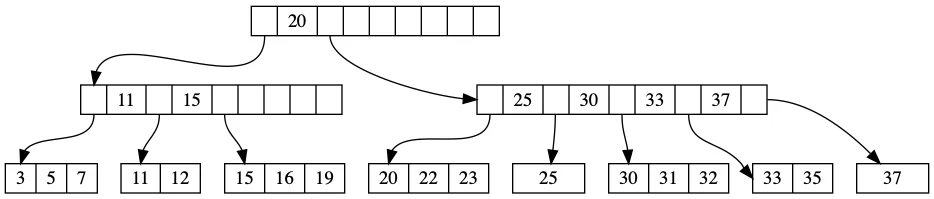
图片来源: tikv.org
{kind=link}
这个结构带来几个关键特性:
O(log N) 的读延迟
在 B+ 树中查找一个键,只需要从根节点遍历到叶子节点。假设每个节点可以存储 100 个键(这在 4KB 页面大小下是合理的),那么一个存储 10 亿条记录的 B+ 树只需要 3-4 层。这意味着即使数据量巨大,点查询也只需要 3-4 次磁盘读取。
当内部节点缓存在内存中时(这在实际系统中是常态),每次查询只需要一次磁盘 I/O——读取叶子节点。
原地更新的代价
B+ 树的更新操作需要先定位到目标叶子节点,然后原地修改。这带来了写放大的问题:
假设页面大小为 4KB,而一条记录只有 100 字节。更新一条记录,却需要将整个 4KB 页面写回磁盘。写放大 = 4096 / 100 = 40 倍。
更糟糕的是页面分裂。当叶子节点满时,插入新记录会导致节点分裂成两个,这需要写入两个新页面,还可能向上传播引发父节点的分裂。在最坏情况下,一次插入可能触发从叶子到根的连锁分裂。
随机写的诅咒
B+ 树最大的性能杀手是随机写。当插入顺序与键序不一致时(这在大多数业务场景中是常态),每次插入都会访问一个随机的叶子页面。在机械硬盘上,这意味着每次插入都伴随一次磁盘寻道(约 10ms)。
SSD 理论上没有机械寻道,但随机写仍然代价高昂。SSD 的写入以"页"为单位(通常 4KB-16KB),但擦除以"块"为单位(通常 4MB)。随机写会导致 SSD 内部的写放大——SSD 控制器需要读取整个块,修改其中一页,然后擦除并重写整个块。
LSM 树:写优化的另辟蹊径
LSM 树的核心思想是:将随机写转换为顺序写。 它通过牺牲读性能和空间效率,换取极高的写入吞吐。
图片来源: tikv.org
{kind=link}
写入路径:从内存到磁盘的延迟阶梯
LSM 树的写入极其简单:
-
写入内存:新数据首先写入内存中的 MemTable(通常是一个跳表或红黑树),同时追加写入 Write-Ahead Log(WAL)用于崩溃恢复。这是纯内存操作,延迟在微秒级。
-
刷盘(Flush):当 MemTable 达到阈值,它被冻结并转换为不可变的 MemTable,然后异步刷入磁盘成为 SSTable(Sorted String Table)。这是顺序写,吞吐量极高。
-
合并(Compaction):后台线程持续将较小的 SSTable 合并成更大的 SSTable。这也是顺序读写操作。
整个写入路径没有一次随机 I/O。这就是 LSM 树在高写入场景下性能碾压 B+ 树的秘密。
读取路径:层层查找的代价
读取是 LSM 树的软肋。要查找一个键,可能需要:
- 查询活跃的 MemTable
- 查询不可变的 MemTable
- 从新到旧查询各层 SSTable
在 Leveled Compaction 策略下,最坏情况需要检查每一层的所有 SSTable。这就是读放大公式 O((log²N/B)/log k) 的来源——它比 B+ 树的 O(log_B N/B) 差得多。
Bloom Filter 救场:为了缓解读放大问题,LSM 树实现者为每个 SSTable 维护 Bloom Filter。Bloom Filter 是一个概率数据结构,能够快速判断一个键"一定不存在"或"可能存在"。在 Bloom Filter 的帮助下,大部分不存在的键查询只需要检查 MemTable 就能返回,无需访问磁盘。
Compaction:后台的双刃剑
Compaction 是 LSM 树最复杂的设计点。它负责合并 SSTable、清理已删除数据、整理碎片。但它本身也带来问题:
写放大:Compaction 过程中,数据会被反复读取和写入。在 Leveled Compaction 策略下,数据从 L0 层流动到最后一层,会被重写约 k·log_k(N/B) 次,其中 k 是相邻层的大小比例(通常为 10)。
空间放大:在 Compaction 完成前,旧数据和新数据同时存在,瞬时空间占用可能翻倍。
性能抖动:Compaction 是 I/O 密集型操作,可能与前台读写竞争资源,导致延迟毛刺。
两种 Compaction 策略
Leveled Compaction(LevelDB、RocksDB 默认):
- 每层维护一个有序的 SSTable 序列
- 写放大较高(约 10-50 倍)
- 空间放大较低(约 10-20%)
- 适合读多写少的场景
Size-Tiered Compaction(Cassandra 默认):
- 每层维护多个大小相近的 SSTable
- 写放大较低(约 3-10 倍)
- 空间放大较高(约 50%)
- 适合写多读少的场景
定量比较:数字不会说谎
TiKV 文档给出了精确的放大公式对比:
| 数据结构 | 写放大 | 读放大 |
|---|---|---|
| B+ 树 | Θ(B) | O(log_B N/B) |
| Leveled LSM | Θ(k·log_k N/B) | Θ((log²N/B)/log k) |
其中 B 是页面大小(字节),N 是数据量,k 是 LSM 树的层间大小比。
这个公式揭示了关键权衡:B+ 树的写放大与页面大小成正比,而 LSM 树的写放大与层数成对数关系。当数据量极大时,LSM 树的写放大优势会越来越明显。
USENIX FAST 2022 发表的一篇论文"Closing the B+-tree vs. LSM-tree Write Amplification Gap"通过实验发现:在传统 SSD 上,RocksDB(LSM)的写放大约为 38,而 B+ 树实现约为 28(8KB 页面)。但在现代存储硬件(带透明压缩)上,这个差距可以进一步缩小。
真实世界的抉择
InnoDB vs MyRocks
MySQL 的默认存储引擎 InnoDB 使用 B+ 树。Facebook 开发的 MyRocks 则基于 RocksDB(LSM 树)。
Facebook 的工程博客分享了他们的迁移经验:在某些工作负载下,MyRocks 比 InnoDB 节省了 50% 的存储空间,写入吞吐提升 2 倍。但代价是读取延迟增加了 30-50%,尤其是在数据不能全部放入内存的场景。
关键结论:当工作数据集大于可用内存时,MyRocks 的压缩优势和写入优势开始显现;当数据可以全部放入内存时,InnoDB 的读性能更优。
为什么 TiKV 选择 LSM 树
TiKV 是一个分布式事务键值存储,选择了 LSM 树作为底层存储引擎。官方文档给出了明确的理由:
“使用缓存技术提升读性能比提升写性能容易得多。”
这是一个深刻的架构洞察:你可以通过增加内存、预热缓存、优化索引来改善读性能,但写放大是存储引擎的固有属性,一旦选定数据结构就很难改变。LSM 树把"难做的优化"(写性能)在数据结构层面解决了,把"易做的优化"(读性能)留给缓存层。
删除操作的天壤之别
B+ 树的删除相对直接:定位记录,标记删除,必要时合并节点。最坏情况是 O(log N),但平均情况是 O(1)。
LSM 树的删除则完全不同:它写入一个"墓碑"(Tombstone)标记,而不是真正删除数据。真正的删除要等到 Compaction 时才会发生。这意味着:
- 删除操作本身极快(只是写入一个标记)
- 但被删除的数据仍然占用空间,直到 Compaction
- 读取时需要过滤掉被标记删除的记录
- 如果删除速度超过 Compaction 速度,空间会持续增长
这是 LSM 树在"删除频繁"场景下的一个陷阱。
近年的优化:两种树在彼此靠近
B+ 树的现代化改造
研究者们从未停止优化 B+ 树:
Bw-Tree(Microsoft):使用 latch-free 的并发控制和增量更新,避免写时加锁,在多核 CPU 上扩展性更好。
Bf-Tree:为现代 SSD 设计,使用变长缓冲池,结合了 B+ 树的读优化和批量写入的写优化。
带压缩感知的 B+ 树:利用现代 SSD 内置的透明压缩功能,在不改变 B+ 树逻辑的情况下减少写放大。
LSM 树的持续进化
WiscKey(FAST 2016):分离键和值的存储。键保持在 LSM 树中,值存储在单独的日志中。这大幅减少了 Compaction 时的写放大,尤其适合值较大的场景。
HashKV:使用哈希分区将值分散到多个日志段,减少垃圾回收的开销。
Pebble(CockroachDB):实现了更精细的 Compaction 调度,减少性能抖动。
如何选择:决策框架
没有放之四海而皆准的答案,但有一个清晰的决策框架:
选择 B+ 树(如 InnoDB、PostgreSQL)当:
- 读多写少(读写比 > 3:1)
- 数据可以放入内存或内存较大
- 需要稳定的读取延迟,不能接受 P99 抖动
- 大量范围查询(B+ 树叶子节点的链表结构对范围扫描极友好)
- 对事务隔离级别有严格要求(B+ 树的锁机制更成熟)
- 频繁的更新和删除操作
选择 LSM 树(如 RocksDB、Cassandra)当:
- 写多读少或写入延迟敏感
- 数据量远超内存容量
- 对存储成本敏感(LSM 树的压缩率更高)
- 可以接受一定的读延迟波动
- 主要是点查询,范围查询较少
- 时序数据、日志、事件流等追加写入场景
特别注意的坑:
LSM 树 + 小随机写:如果你的写入模式是小价值的频繁随机写入,LSM 树的 Compaction 可能会成为瓶颈。此时考虑使用 WiscKey 类的键值分离设计。
B+ 树 + 大数据量 + 小内存:当工作数据集远大于内存时,每次随机写入都会触发磁盘 I/O。此时应该考虑 LSM 树或增加内存。
LSM 树 + 高删除率:墓碑累积会导致空间放大和读放大。确保你的 Compaction 策略能跟上删除速度。
结语
B+ 树和 LSM 树代表了存储引擎设计的两种哲学:B+ 树相信"好的索引结构应该让查找尽可能高效",LSM 树相信"好的索引结构应该让写入尽可能高效"。
它们之间的差异不是实现细节的差异,而是对"什么更重要"这一问题的不同回答。这个差异源于 1970 年和 1996 年两篇论文提出时的不同背景——B+ 树诞生于查询密集的事务处理时代,LSM 树诞生于日志爆炸的互联网时代。
五十年来,存储介质从机械硬盘演变为 SSD,内存容量从 KB 级增长到 TB 级,但这个基本权衡没有改变。我们能做的,是根据自己的业务特点,在两个不完美的选项中做出最不坏的选择。
这就是工程——没有完美的方案,只有权衡。
参考文献
-
Bayer, R., & McCreight, E. (1972). Organization and maintenance of large ordered indices. Acta Informatica, 1(3), 173-189.
-
O’Neil, P., Cheng, E., Gawlick, D., & O’Neil, E. (1996). The log-structured merge-tree (LSM-tree). Acta Informatica, 33(4), 351-385.
-
Qiao, Y., et al. (2022). Closing the B+-tree vs. LSM-tree Write Amplification Gap on Modern Storage Hardware with Built-in Transparent Compression. USENIX FAST.
-
Lu, L., et al. (2016). WiscKey: Separating Keys from Values in SSD-conscious Storage. USENIX FAST.
-
TiKV Documentation. B-Tree vs LSM-Tree. https://tikv.org/deep-dive/key-value-engine/b-tree-vs-lsm/
-
Facebook Engineering. MyRocks: A space- and write-optimized MySQL database. https://engineering.fb.com/2016/08/31/core-infra/myrocks/
-
Dayan, N., & Idreos, S. (2018). The Log-Structured Merge-Bush & the Wacky Continuum. ACM SIGMOD.
-
Graefe, G. (2011). Modern B-tree techniques. Foundations and Trends in Databases, 3(4), 203-402.