1953年,IBM工程师Hans Peter Luhn在一份内部备忘录中提出了一个改变计算机科学进程的想法:用哈希函数将数据映射到固定位置,实现快速查找。这个被称为"哈希表"的数据结构,至今仍是计算机领域应用最广泛的发明之一。
十七年后,波音研究实验室的Rudolf Bayer和Edward McCreight面临另一个问题:如何让磁盘上的数据查找变得高效?他们发明了B树。再过二十年,马里兰大学教授William Pugh在1990年发表了跳表论文,用概率性方法替代严格平衡,宣称比平衡树更简单、更快。
这些发明背后有一个共同点:它们都在解决"权衡"问题。没有一种数据结构能在所有维度上都胜出——这就是数据结构设计的第一性原理。
时间与空间:无法兼得的两个维度
计算机科学中最基本的权衡发生在时间与空间之间。用更多内存缓存计算结果,可以减少重复计算的时间;压缩数据节省空间,解压时却要付出时间代价。
这种权衡在数据结构层面表现得尤为明显。以布隆过滤器为例,它用9.6个比特就能存储一个元素的"可能存在"状态,代价是存在约1%的误判率。如果换成哈希表存储实际元素,每个元素需要数十到上百比特,但查询结果100%准确。
| 数据结构 | 空间效率 | 查询准确率 | 典型应用 |
|---|---|---|---|
| 布隆过滤器 | ~10 bits/元素 | 可能假阳性,绝无假阴性 | 缓存穿透防护、垃圾邮件过滤 |
| 哈希表 | 64-128 bits/元素 | 100%准确 | 键值存储、内存数据库 |
| 位图 | 1 bit/元素(元素范围已知) | 100%准确,仅限整数 | 用户标签、权限管理 |
选择哪种结构,取决于你愿意为准确性付出多少空间代价。
动态规划中的时空权衡
时空权衡最经典的体现是动态规划。斐波那契数列的朴素递归实现时间复杂度为O(2^n),因为存在大量重复计算。引入备忘录(memoization)后,时间降为O(n),但需要O(n)的额外空间。如果进一步优化为只保留前两个值,空间可以降到O(1),但代码可读性下降。
# 朴素递归:时间O(2^n),空间O(1)
def fib_naive(n):
if n <= 1:
return n
return fib_naive(n-1) + fib_naive(n-2)
# 备忘录:时间O(n),空间O(n)
def fib_memo(n, memo={}):
if n <= 1:
return n
if n in memo:
return memo[n]
memo[n] = fib_memo(n-1, memo) + fib_memo(n-2, memo)
return memo[n]
# 迭代优化:时间O(n),空间O(1)
def fib_iter(n):
if n <= 1:
return n
a, b = 0, 1
for _ in range(2, n+1):
a, b = b, a + b
return b
这三种实现没有绝对的优劣——如果你只计算几次斐波那契数,朴素递归的简单性可能更值;如果需要频繁计算,备忘录更合适;如果内存极度受限,迭代方案是唯一选择。
读与写:数据库存储引擎的根本分歧
进入磁盘存储领域,权衡变得更加复杂。磁盘的物理特性引入了新的变量:随机读写与顺序读写的性能差异可达百倍。
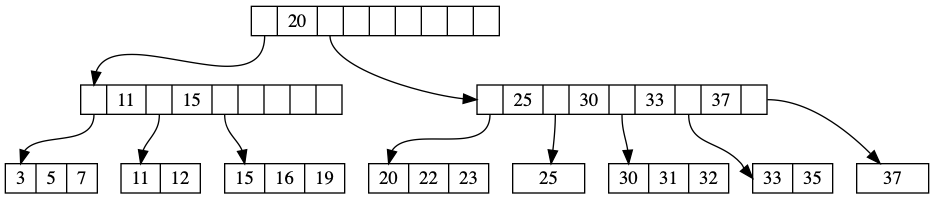
B树:读优先的选择
B树(及其变体B+树)的设计哲学是优化读取性能。它的核心特点是:
- 节点大小与磁盘页对齐:每个节点通常存储数百到上千个键,一次磁盘IO就能读取大量数据
- 树的高度极低:对于一个存储十亿条记录的B树,高度通常只有3-4层
- 数据有序存储:支持高效的范围查询
但B树在写入时存在固有的开销。每次插入可能触发节点分裂,导致数据在磁盘上的移动和重写。这就是"写放大"(write amplification)问题。
根据TiKV团队的量化分析,B+树的写放大为Θ(B),其中B是页大小(字节)。如果页大小为16KB,写入1MB数据可能触发16MB的实际磁盘写入。
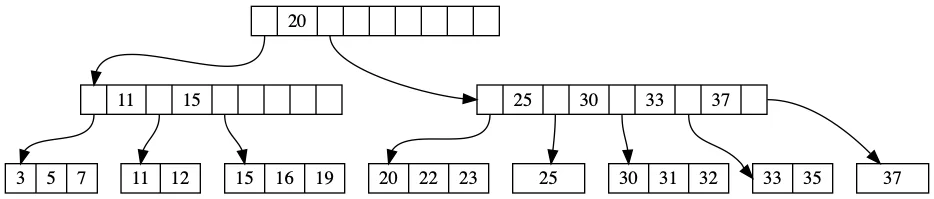
图片来源: tikv.org
{kind=link}
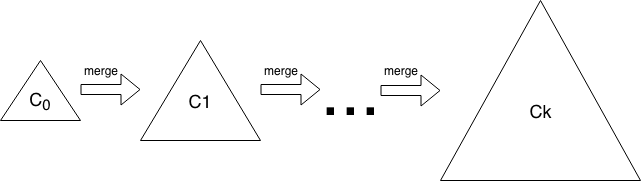
LSM树:写优先的选择
Log-Structured Merge Tree(LSM树)采用了完全不同的策略。它将写入操作先记录在内存中,周期性地将内存数据合并写入磁盘。
LSM树的写入过程:
- 数据首先写入内存中的memtable
- memtable达到阈值后,转换为不可变的SSTable写入磁盘
- 后台线程定期执行compaction,合并多个SSTable
这种"追加写入"模式将随机写转换为顺序写,极大提升了写入吞吐。代价是读取时可能需要检查多层SSTable,读放大较高。
TiKV的对比数据:
| 数据结构 | 写放大 | 读放大(冷缓存) |
|---|---|---|
| B+树 | Θ(B) | O(log_B(N/B)) |
| LSM树 | Θ(k·log_k(N/B)) | Θ((log²(N/B))/log k) |
其中k是LSM树的层增长因子(通常为10),B是页大小,N是数据量。
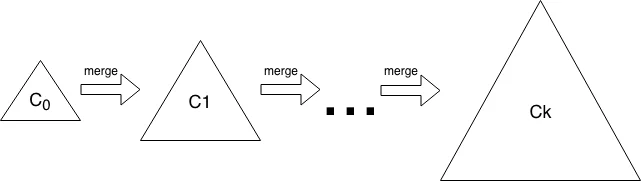
图片来源: tikv.org
{kind=link}
这就是为什么PostgreSQL、MySQL等传统数据库使用B+树,而Cassandra、RocksDB等追求高写入吞吐的系统选择LSM树。选择取决于你的读写比例。
内存访问:被忽视的第三个维度
传统的复杂度分析假设所有内存访问的代价相同。但在现代CPU上,这个假设已经失效。访问L1缓存约需4个时钟周期,访问主内存则需要200-300个周期——差距超过50倍。
数组 vs 链表:理论之外的差距
在复杂度层面,数组和链表的遍历都是O(n)。但实际性能可能相差10倍以上。
数组的元素在内存中连续存储。当CPU访问第一个元素时,整个缓存行(通常64字节)会被加载到缓存中。后续访问同一缓存行中的元素就是缓存命中,几乎零延迟。
链表的每个节点可能分散在内存的任意位置。访问一个节点后,下一个节点几乎必定不在缓存中,导致缓存未命中。
// 数组遍历:缓存友好
int sum_array(int* arr, int n) {
int sum = 0;
for (int i = 0; i < n; i++) {
sum += arr[i]; // 连续内存访问
}
return sum;
}
// 链表遍历:缓存不友好
int sum_list(Node* head) {
int sum = 0;
Node* curr = head;
while (curr) {
sum += curr->value; // 跳跃内存访问
curr = curr->next;
}
return sum;
}
2017年的一项性能测试显示,在处理100万个32位整数时,数组遍历比链表快约8倍,尽管两者的时间复杂度相同。
这解释了为什么现代高性能哈希表(如Google的SwissTable)使用开放寻址而非链式法处理冲突——连续内存布局带来显著的缓存优势。
B树 vs 红黑树:磁盘与内存的分野
红黑树和AVL树在内存中的查找性能通常优于B树,因为它们的高度更低(对于相同数量的元素)。但当数据需要持久化到磁盘时,B树的优势显现:
- 减少磁盘IO次数:B树每个节点存储多个键,一次IO可以读取大量数据
- 更好的局部性:同一节点的数据在磁盘上连续存储
- 更高的缓存利用率:B树节点通常设计为与缓存行对齐
这就是为什么Java的TreeMap使用红黑树(内存数据结构),而MySQL的InnoDB使用B+树(磁盘数据结构)。场景决定选择。
实现复杂度:工程不能忽视的代价
理论上最优的数据结构,在实践中可能因为实现复杂度而被放弃。
跳表 vs 平衡树:简单性的胜利
1990年,William Pugh在《Communications of the ACM》上发表了跳表论文,标题直言不讳:“Skip Lists: A Probabilistic Alternative to Balanced Trees”。
跳表的核心思想是用概率代替确定性维护平衡。插入时,每个新节点有50%的概率"提升"到更高层。这种简单规则使得跳表的查找、插入、删除都是O(log n),与红黑树相当。
为什么Redis选择跳表而非红黑树实现有序集合(ZSET)?Redis作者antirez在StackOverflow上的回答揭示了原因:
- 实现简单:跳表的代码量约为平衡树的一半,更易维护
- 并发友好:跳表在并发环境下更容易实现无锁操作
- 内存效率:跳表的指针开销可预测,不像平衡树那样因旋转而变化
跳表的另一个优势是范围查询效率。在找到起点后,沿最底层链表顺序遍历即可,无需像平衡树那样执行中序遍历。
哈希表冲突处理:链式法 vs 开放寻址
哈希表的两个主流冲突处理方案各有优劣:
链式法(Chaining):
- 每个槽位存储一个链表
- 插入简单,只需追加到链表
- 内存不连续,缓存性能差
- Java HashMap采用此方案
开放寻址(Open Addressing):
- 所有元素存储在数组中
- 冲突时探测下一个空位
- 内存连续,缓存友好
- 负载因子过高时性能急剧下降
- Python dict、Ruby Hash采用此方案
链式法哈希表:
槽位[0] -> [元素A] -> [元素B] -> NULL
槽位[1] -> [元素C] -> NULL
槽位[2] -> NULL
开放寻址哈希表:
[元素A] [元素C] [元素B] [空] [元素D] [空] ...
↑冲突后线性探测到此处
近年来,开放寻址在高性能场景中占据上风。Google的SwissTable通过SIMD指令优化探测过程,将开放寻址的性能推向新高度。
特殊场景:领域特定的最优解
某些场景需要专门设计的数据结构,通用结构难以胜任。
Trie:前缀匹配的利器
Trie(前缀树)专门用于字符串集合的前缀查询。它的每个节点代表一个字符,从根到叶的路径组成一个完整字符串。
Trie的优势在于前缀查询的效率——查找所有以"pro"开头的单词,只需遍历到"pro"节点,然后收集所有后代即可。用哈希表则需要遍历所有键逐一检查。
但Trie的空间效率堪忧。存储100万个平均长度10的字符串,需要约1000万个节点,每个节点需要存储26个子指针(假设只处理小写字母)。优化方案包括:
- 压缩Trie(Patricia Trie):合并单分支路径
- 使用哈希表代替数组存储子节点:节省空间,但丢失有序性
环形缓冲区:数据流处理的标配
环形缓冲区(Ring Buffer)是生产者-消费者场景的经典选择。它利用固定大小的数组和两个指针(读指针、写指针),实现O(1)的入队和出队。
环形缓冲区的优势:
- 内存预分配:无动态内存分配开销
- 缓存友好:数据连续存储
- 无锁实现:单生产者单消费者场景下可无锁实现
Linux内核的网络数据包处理、高性能消息队列(如Disruptor)都使用环形缓冲区。
选择框架:如何做出正确的决策
面对具体问题,如何选择数据结构?以下是系统化的决策流程:
第一步:明确核心操作
首先列出数据结构需要支持的操作及其频率:
- 查找:精确查找还是范围查找?
- 插入/删除:频率如何?在头部、尾部还是任意位置?
- 遍历:顺序遍历还是随机访问?
第二步:量化数据规模
数据量级决定了最优策略:
- 小规模(<1000):实现简单性优先,O(n²)算法也可接受
- 中等规模(1000-100万):O(n log n)和O(n)算法的性能差异显著
- 大规模(>100万):缓存友好性、并行化成为关键考量
第三步:识别存储层次
数据主要存储在哪里?
- 纯内存:选择更灵活,缓存友好性重要
- 磁盘持久化:IO次数是核心瓶颈,考虑B树或LSM树
- 混合场景:可能需要多级结构,如内存索引+磁盘数据
第四步:权衡实现成本
高性能往往伴随实现复杂度:
- 团队是否熟悉该数据结构?
- 是否有成熟的开源实现?
- 维护成本是否可接受?
第五步:实测验证
理论和实践总有差距。在做出选择后,务必进行基准测试:
- 使用真实数据和工作负载
- 测量P50、P99延迟,而不仅是平均值
- 考虑极端情况(高并发、数据倾斜)的表现
常见的选型误区
误区一:追求"最优"复杂度
时间复杂度只是描述增长趋势,常数因子同样重要。O(log n)的跳表在实践中可能与O(1)的哈希表性能相当甚至更好,因为前者的常数因子更小。
误区二:忽视预分配成本
某些数据结构虽然单次操作快,但预分配成本高昂。例如,动态数组的均摊O(1)插入,在扩容时会有一次O(n)的操作。实时系统可能无法接受这种毛刺。
误区三:过度优化
Donald Knuth的名言常被误读:“过早优化是万恶之源"并非反对优化,而是反对没有测量基础的盲目优化。正确的做法是:先测量,找到瓶颈,再针对性优化。
误区四:忽视并发需求
单线程下性能最优的数据结构,在多线程场景可能性能崩溃。例如,Java的HashMap在并发写入时可能进入死循环。选择数据结构时,必须考虑并发访问模式。
结语
数据结构的选择,本质是在多个维度上进行权衡:时间与空间、读写性能、内存与磁盘、实现复杂度与性能。不存在"最好"的数据结构,只存在"最适合当前场景"的数据结构。
1953年的哈希表、1970年的B树、1990年的跳表,这些发明之所以经久不衰,正是因为它们在特定场景下做出了正确的权衡。当我们站在前人的肩膀上设计系统时,理解这些权衡背后的逻辑,比记住复杂度公式更重要。
下一次面对数据结构选择时,不妨先问自己三个问题:
- 我的场景里,哪个维度是最关键的瓶颈?
- 我愿意为提升这个维度牺牲什么?
- 我的团队能否驾驭这种结构的实现?
答案,就藏在这三个问题的权衡之中。
参考资料
- Pugh, W. (1990). Skip lists: a probabilistic alternative to balanced trees. Communications of the ACM, 33(6), 668-676.
- Bayer, R., & McCreight, E. (1970). Organization and maintenance of large ordered indexes. Acta Informatica, 1(3), 173-189.
- O’Neil, P., Cheng, E., Gawlick, D., & O’Neil, E. (1996). The log-structured merge-tree (LSM-tree). Acta Informatica, 33(4), 351-385.
- Knuth, D. E. (1973). The Art of Computer Programming, Volume 3: Sorting and Searching. Addison-Wesley.
- TiKV Documentation. B-Tree vs LSM-Tree. https://tikv.org/deep-dive/key-value-engine/b-tree-vs-lsm/
- Redis Documentation. Redis Data Types. https://redis.io/technology/data-structures/
- GeeksforGeeks. Time Complexities of Different Data Structures. https://www.geeksforgeeks.org/dsa/time-complexities-of-different-data-structures/
- Stack Overflow. Why Redis SortedSet uses Skip List instead of Balanced Tree? https://stackoverflow.com/questions/45115047/
- Big-O Cheat Sheet. https://www.bigocheatsheet.com/
- Wikipedia. Hash array mapped trie. https://en.wikipedia.org/wiki/Hash_array_mapped_trie
- IEEE Spectrum. Hans Peter Luhn and the Birth of the Hashing Algorithm. https://spectrum.ieee.org/hans-peter-luhn-and-the-birth-of-the-hashing-algorithm