1970年,计算机科学家Burton Howard Bloom在《Communications of the ACM》上发表了一篇论文,标题是"Space/Time Trade-offs in Hash Coding with Allowable Errors"。论文只有五页,提出的问题却出奇地实用:如果你想在一个有限的内存空间里存储大量数据,并且允许偶尔犯错,能做到什么程度?
半个世纪过去了,这个问题的答案几乎支撑起了现代互联网的基础设施。从Google Bigtable到Apache Cassandra,从Chrome浏览器到以太坊区块链,布隆过滤器无处不在。理解它,就是理解工程师如何在"完美"与"足够好"之间做取舍。
一个打字机时代的问题
Bloom论文开篇举了一个例子:假设你有一本50万词的字典,其中90%的词遵循简单的连字符规则,但剩下的10%需要查阅昂贵的磁盘数据。如果内存足够大,你可以用一个完美哈希表来排除所有不必要的磁盘访问;但在内存有限的年代,Bloom的方法是用一个更小的哈希区域,仍然能消除87%的不必要访问。
这个场景在今天看来有些陌生,但问题本质没有变:当存储资源有限而数据量庞大时,如何快速判断某个元素是否在集合中?
传统方案有明显的短板。哈希表需要存储完整的键值,内存消耗巨大;二叉搜索树需要O(log n)的查询时间;位数组需要为每个可能的元素分配一位,当元素空间巨大时完全不可行。
布隆过滤器的方案是:放弃确定性,换取空间效率。它不会告诉你"元素一定在集合中",只会告诉你"元素可能在集合中"或"元素一定不在集合中"。这个看似退步的妥协,恰恰是它的力量所在。
位数组上的数学魔术
布隆过滤器的核心结构简单得令人惊讶:一个m位的位数组,加上k个哈希函数。
初始状态,所有位都是0。当要插入一个元素时,用k个哈希函数分别计算,得到k个位置索引,将这k个位置都设为1。查询时,同样用k个哈希函数计算位置,检查这些位是否全为1。如果任何一位是0,元素肯定不在集合中;如果全是1,元素可能在集合中。
“可能"二字,是布隆过滤器的灵魂。
为什么会有假阳性?因为不同元素的哈希值可能碰撞。假设元素A设置了位置1、3、5,元素B设置了位置2、4、5,那么查询一个从未插入过的元素C,如果它的哈希值恰好落在1、2、5,就会被误判为"可能在集合中”。
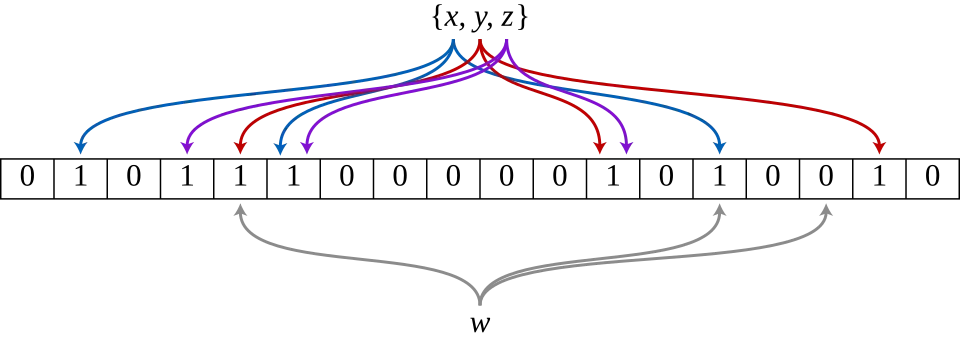
图片来源: upload.wikimedia.org
{kind=link}
上图展示了一个具体的例子:集合{x, y, z}已经被插入,彩色箭头显示每个元素映射到位数组的位置。元素w不在集合中,因为它哈希到了一个值为0的位置,这证明了w绝对不存在。
假阳性率的数学推导
理解布隆过滤器,必须理解假阳性率的计算。这是一个优美的概率论推导。
假设位数组有m位,使用k个哈希函数,已经插入了n个元素。
当插入一个元素时,某一位被某个哈希函数设为1的概率是1/m,不被设为1的概率是1 - 1/m。经过k个哈希函数后,这一位仍然为0的概率是:
(1 - 1/m)^k ≈ e^(-k/m)
插入n个元素后,某一位仍然为0的概率是:
(1 - 1/m)^(nk) ≈ e^(-nk/m)
这一位变为1的概率是:
1 - e^(-nk/m)
当查询一个不在集合中的元素时,假阳性发生的条件是k个哈希位置全为1,概率为:
(1 - e^(-nk/m))^k
这就是布隆过滤器假阳性率的近似公式。更精确的公式需要考虑哈希函数的独立性假设,但这个近似已经足够实用。
最优参数选择
有了假阳性率公式,自然会问:给定n和期望的假阳性率ε,m和k应该选多少?
数学推导表明,最优的k值(使假阳性率最小的哈希函数数量)是:
k = (m/n) × ln(2) ≈ 0.693 × (m/n)
这意味着,如果想用较少的位数组空间存储较多元素(m/n小),应该减少哈希函数数量;如果想降低假阳性率(需要更多空间),则增加哈希函数数量。
给定假阳性率ε,所需的位数组大小为:
m = -n × ln(ε) / (ln(2))^2 ≈ -1.44 × n × ln(ε)
一个惊人的结论是:对于1%的假阳性率,每个元素只需要约9.6个比特,与元素本身的大小无关。存储一个100字节的URL和一个4字节的整数,所需的布隆过滤器空间是一样的。
为什么主流数据库都在用它
布隆过滤器在工业界的成功,源于它解决了LSM树数据库的一个核心痛点。
LSM树与SSTable的查询困境
现代分布式数据库广泛采用LSM树(Log-Structured Merge Tree)作为存储引擎。数据先写入内存中的MemTable,达到阈值后刷盘生成SSTable(Sorted String Table)。随着数据积累,SSTable会越来越多,查询一个键需要遍历所有可能包含该键的SSTable——这是严重的I/O开销。
Google Bigtable的设计文档明确指出了这个问题:
“A read operation has to read from all SSTables that make up the state of a tablet. If these SSTables are not in memory, we may end up doing many disk accesses.”
Bigtable的解决方案是为每个SSTable配备布隆过滤器。查询时,先用布隆过滤器判断目标键是否可能在某个SSTable中。如果布隆过滤器返回"不存在",直接跳过这个SSTable,省去磁盘读取。
Apache Cassandra的官方文档同样强调了布隆过滤器的价值:在典型工作负载下,布隆过滤器能阻止超过90%的不必要磁盘读取。
空间与时间的权衡艺术
以一个具体例子说明:假设数据库有100亿条记录,平均每个SSTable存储100万条,总共需要10,000个SSTable。查询一个不存在的键,理论上需要检查10,000个SSTable。
如果每个SSTable配备一个假阳性率1%的布隆过滤器,错误判断的期望次数只有100次。换句话说,布隆过滤器将I/O开销降低了99%,代价是每个元素约10比特的内存——对于100万条记录,只需要约1.2MB。
这正是Cassandra报告的结果:对于查询不存在键的工作负载,磁盘读取减少超过90%,查询延迟大幅下降。
缓存穿透防护:一个教科书级的应用
布隆过滤器最广为人知的应用场景,是解决缓存穿透问题。
缓存穿透的本质
典型的缓存架构是:应用先查缓存,缓存未命中再查数据库,结果写入缓存。这个模式有一个致命弱点:如果攻击者大量请求不存在的键,每个请求都会穿透缓存直达数据库,瞬间压垮后端。
这不是理论风险。2015年,某电商大促期间,有人用脚本批量请求不存在的商品ID,缓存层完全失效,数据库负载飙升,整个系统瘫痪。
布隆过滤器的防护逻辑
解决方案是在缓存层前加一个布隆过滤器。写入数据库时,同时将键写入布隆过滤器。查询时,先问布隆过滤器:这个键是否存在?
- 如果布隆过滤器说"不存在",直接返回,不查缓存,不查数据库
- 如果布隆过滤器说"可能存在",继续正常流程
由于布隆过滤器没有假阴性,不存在的键一定会被拦截。假阳性只会导致极少数正常请求被误判为不存在——这在实际系统中通常可以接受。
Redis的RedisBloom模块专门为此设计。一条命令BF.ADD添加元素,一条命令BF.EXISTS查询,底层自动处理扩容和哈希函数管理。
一个"不可删除"的设计抉择
布隆过滤器有一个著名限制:标准版本不支持删除元素。
原因很简单:删除一个元素需要将对应的k位设为0,但这些位可能被其他元素共享。贸然清零会引入假阴性,破坏布隆过滤器的根本保证。
这个限制不是缺陷,而是设计权衡的结果。布隆过滤器的价值在于极小的空间开销,支持删除会显著增加复杂度。
Counting Bloom Filter:用空间换功能
如果必须支持删除,可以使用Counting Bloom Filter。将每一位替换为一个计数器,插入时加1,删除时减1。这解决了删除问题,但空间开销通常增加3-4倍。
对于存储海量数据的场景,这个代价可能难以接受。因此,Counting Bloom Filter通常用于需要频繁更新的小规模场景。
Cuckoo Filter:更好的删除支持
2014年,研究者提出了Cuckoo Filter,基于布谷鸟哈希实现。它的核心优势是支持删除且空间效率更高,在低假阳性率场景下甚至比标准布隆过滤器更省空间。
Cuckoo Filter存储的是元素的指纹而不是简单的位,可以在保持O(1)查询的同时支持删除。代价是实现更复杂,且删除操作需要额外的指纹验证。
RedisBloom模块同时支持布隆过滤器和Cuckoo过滤器,用户可以根据场景选择。
Chrome浏览器:用2.4MB存储200万恶意URL
布隆过滤器的另一个经典应用是Google Chrome的安全浏览功能。
Chrome需要判断用户访问的URL是否在恶意网站列表中。问题在于,这个列表包含约200万个URL,每个URL平均约50字节,总大小超过100MB。将这个列表完整存储在每个用户的浏览器中是不现实的。
布隆过滤器提供了一个优雅的解决方案:用一个2.4MB的布隆过滤器存储这200万个URL的指纹。
工作流程是:
- 用户访问URL时,先用本地布隆过滤器判断
- 如果布隆过滤器说"不存在",直接放行
- 如果布隆过滤器说"可能存在",向Google服务器发起验证请求
由于假阳性率设置为很低的值(约0.01%),99.99%的正常请求直接在本地完成,只有极少数需要网络请求。这个设计既保护了用户隐私(Google不知道用户访问了哪些正常网站),又节省了带宽。
Akamai CDN:过滤一次性请求的智能缓存
内容分发网络Akamai发现了一个有趣的现象:约75%的缓存对象只被访问一次,被称为"one-hit-wonders"。将这些对象写入磁盘缓存纯属浪费资源。
Akamai的解决方案是用布隆过滤器跟踪哪些URL被访问过。只有当URL第二次被访问时,才将它写入磁盘缓存。
这个看似简单的策略产生了显著效果:
- 磁盘写入量大幅减少
- 缓存命中率提高(因为缓存空间留给了真正热门的内容)
- 磁盘I/O压力下降
Akamai的研究论文指出,布隆过滤器在这种场景下的价值是"以极小的内存代价,换取显著的磁盘资源节省"。
爬虫去重:处理数十亿URL的内存挑战
网络爬虫面临一个经典问题:如何避免重复爬取同一个URL?
对于小规模爬虫,用哈希表存储已爬取的URL即可。但对于大规模爬虫——比如需要处理数十亿URL的搜索引擎——哈希表的内存开销令人望而却步。
假设有10亿个URL,平均每个URL 50字节,哈希表需要至少50GB内存。换成布隆过滤器,用1%假阳性率,只需要约1.2GB。
假阳性率的代价是:约1%的URL会被错误地判断为"已爬取",从而被跳过。对于搜索引擎而言,这通常是可以接受的精度损失,换来的是两个数量级的内存节省。
现实世界的参数选择
理论推导给出最优公式,但实际应用需要考虑更多因素。
哈希函数的选择
布隆过滤器需要k个独立的哈希函数。实践中,通常不使用k个完全独立的哈希函数,而是用"双重哈希"技术:用两个基础哈希函数H1和H2,生成k个哈希值:
Hi(x) = H1(x) + i × H2(x)
常用的哈希函数包括MurmurHash、xxHash和FNV系列。它们的特点是计算速度快,分布均匀,碰撞率低。密码学安全的哈希函数(如SHA-256)虽然更安全,但计算开销太大,通常不用于布隆过滤器。
误判率的实际影响
理论假阳性率是统计期望,实际应用中会有波动。对于关键系统,建议:
- 设计时预留20%的额外空间
- 监控实际的假阳性率
- 当假阳性率超过阈值时重建过滤器
扩容策略
标准布隆过滤器的大小是固定的。如果插入的元素超过预期,假阳性率会急剧上升。
Scalable Bloom Filter解决了这个问题。它维护一组按指数增长的布隆过滤器,当当前过滤器接近饱和时,自动创建新的过滤器。查询时需要检查所有过滤器,但空间效率得以保持。
为什么不是每个场景都适合
布隆过滤器并非万能工具。理解它的局限性,才能正确使用。
不适合存储元素本身
布隆过滤器只回答"元素是否在集合中",不存储元素本身。如果需要获取元素的值,必须配合其他数据结构。
假阳性的代价必须可接受
在某些场景,假阳性是不可接受的。比如,一个判断用户是否在黑名单中的系统,假阳性会导致合法用户被拒绝访问。
无法精确计数
布隆过滤器不能告诉你集合中有多少元素。虽然可以通过位数组中1的比例估算,但结果只是近似值。
持久化与重建
当假阳性率上升时,需要重建布隆过滤器。这意味着需要重新插入所有元素——如果元素来源是外部系统,可能需要同步操作。
结语:工程是关于权衡的艺术
布隆过滤器的成功,不在于它解决了什么问题,而在于它如何解决问题。
它放弃了完美准确性,换取了极致的空间效率。它放弃了删除能力,换取了实现的简单性。它放弃了存储元素本身,换取了O(1)的查询复杂度。
每一个设计决策,都是在特定约束下做的权衡。这正是工程思维的本质:没有完美的解决方案,只有最适合特定场景的方案。
当你下次在系统设计面试中讨论缓存穿透、在数据库优化中分析查询性能、在爬虫开发中处理URL去重,布隆过滤器可能是那个"刚刚好"的工具。它不完美,但在很多场景下,它足够好。
参考资料
- Bloom, B. H. (1970). Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7), 422-426.
- Chang, F., et al. (2006). Bigtable: A Distributed Storage System for Structured Data. OSDI ‘06.
- Fan, L., et al. (2000). Summary Cache: A Scalable Wide-Area Web Cache Sharing Protocol. IEEE/ACM Transactions on Networking.
- Fan, B., et al. (2014). Cuckoo Filter: Practically Better Than Bloom. CoNEXT ‘14.
- Apache Cassandra Documentation. Bloom Filters. https://cassandra.apache.org/doc/latest/cassandra/managing/operating/bloom_filters.html
- Redis Documentation. Bloom Filter. https://redis.io/docs/latest/develop/data-types/probabilistic/bloom-filter/
- Wikipedia. Bloom filter. https://en.wikipedia.org/wiki/Bloom_filter
- Brilliant Math & Science Wiki. Bloom Filter. https://brilliant.org/wiki/bloom-filter/
- Medium. How Chrome uses Bloom Filters for Safe Browsing. https://medium.com/@mr.sourav.raj/advanced-algorithms-every-senior-developer-must-know-part-3-bloom-filters-2e6092e343aa