一个简单的测试揭示了令人困惑的现象:同样的硬件、同样的表结构、同样的索引设计,使用UUID作为主键的表插入速度只有自增主键的十分之一。更奇怪的是,存储空间的占用竟然相差接近一倍。
这不是数据库实现的缺陷,而是B+树数据结构在面对不同写入模式时展现出的迥异行为。理解这一现象的关键在于一个被称为"页分裂"的内部操作——它是维护B+树平衡的必要代价,却也是性能差异的根源所在。
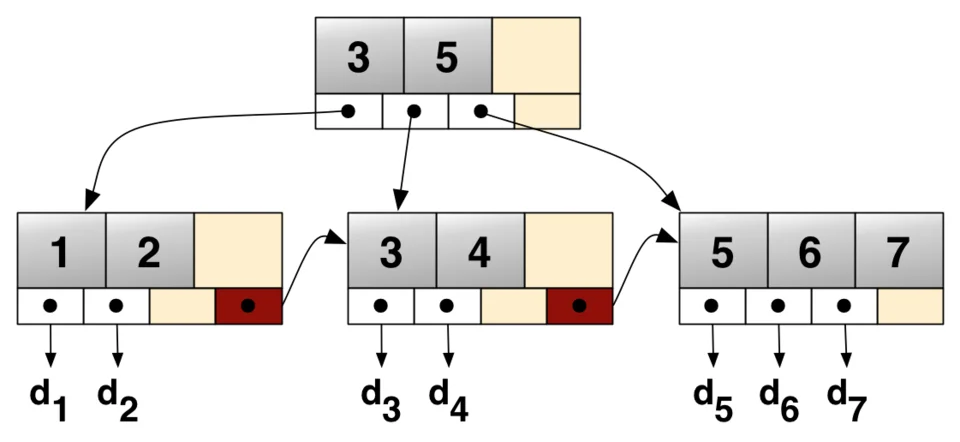
页面:B+树的物理单元
InnoDB存储引擎将数据组织在固定大小的页面中,默认大小为16KB。每个页面可以容纳多条记录,记录按照主键顺序排列。当页面填满时,新记录无法直接插入,此时就会触发页分裂。
B+树的设计哲学是用空间换时间:通过保持树的平衡,确保任何查询都只需要访问有限层数的页面。一棵三层的B+树,在16KB页面大小下,可以存储超过2000万条记录,而查询只需要三次I/O操作。这种优雅的平衡性,建立在持续调整的基础上——页分裂就是调整的核心机制。
图片来源: upload.wikimedia.org
{kind=link}
页面之间通过双向链表连接,叶子节点保存完整的数据记录,内部节点只保存键值和子节点指针。这种结构使得范围查询异常高效:找到起始点后,沿着链表顺序读取即可。
分裂的代价
当一条记录需要插入到已满的页面时,数据库引擎必须做出选择。理想情况下,在页面末尾追加新记录最为高效,但B+树要求记录按键值有序排列,插入位置由键值决定,而非由程序员决定。
页分裂的基本过程如下:首先分配一个新页面,然后将原页面中大约一半的记录移动到新页面,最后更新父节点的指针。这个过程听起来简单,但实际开销相当可观:
sequenceDiagram
participant Client as 客户端
participant Buffer as Buffer Pool
participant Disk as 磁盘
participant Log as Redo Log
Client->>Buffer: INSERT请求
Buffer->>Buffer: 定位目标页面(已满)
Buffer->>Buffer: 申请分配新页面
Buffer->>Buffer: 移动一半记录到新页面
Buffer->>Log: 记录分裂操作日志
Buffer->>Buffer: 更新父节点指针
Buffer->>Log: 记录父节点更新日志
Buffer->>Disk: 刷新脏页(异步)
每次页分裂至少涉及三个页面的修改:原页面、新页面、父页面。更重要的是,分裂会打乱页面的物理顺序。新分配的页面通常位于表空间的末尾,与原页面在物理上相距甚远。当查询需要扫描多个页面时,这种物理上的离散会转化为大量的随机I/O。
InnoDB通过INFORMATION_SCHEMA.INNODB_METRICS表暴露了页分裂的统计信息。关键字段包括index_page_splits(页分裂次数)和index_page_reorg_attempts(页面重组尝试次数),这些指标可以帮助识别潜在的性能问题。
顺序插入:自然的馈赠
如果插入的主键值是递增的,情况会发生奇妙的变化。每条新记录都会落到最右侧叶子页面的末尾。当该页面填满时,只需简单地分配一个新页面,将后续记录写入新页面即可——没有记录移动,没有页面重组,只有纯粹的追加操作。
MySQL官方文档明确指出了这种行为:当记录按顺序(升序或降序)插入时,生成的索引页面大约填满15/16(约94%)。这个数字背后有特定的设计考量:InnoDB刻意保留1/16的空间用于未来的更新操作,避免因记录变长而立即触发分裂。
这种"最右追加"模式的优势是多方面的:
存储效率:页面几乎完全填满,没有浪费的空间。相比之下,随机插入导致的页面平均填充率只有50%到94%,在极端情况下可能低至50%。
I/O效率:连续的页面在磁盘上也倾向于连续存储,范围查询时的顺序读取效率最高。SSD的顺序读取速度可以达到随机读取的数倍。
缓存友好:热点数据集中在最右侧的少数页面中,Buffer Pool的命中率更高。随着数据增长,旧的页面逐渐变冷,但这种"热度梯度"是可预测的。
自增主键正是利用了这一特性。每次插入都落在最右侧,几乎不会在中间位置触发分裂。即使在高并发场景下,多个事务同时插入也只是竞争最后那个页面——这个问题可以通过innodb_autoinc_lock_mode参数优化。
随机插入:连锁反应的开始
当主键值是随机生成时,插入位置变得不可预测。新记录可能落在B+树的任何位置,而那个位置对应的页面可能已经填满。此时必须触发页分裂,将一条记录"挤"进去。
Percona的技术博客通过实验清晰地展示了这种差异。使用UUID作为主键时,页面分布呈现出严重的"稀疏化":大量页面只有一半填充,页面数量远超实际数据量所需,整个索引树变得扁平而宽大。
问题的根源在于分裂算法本身。当随机记录插入到满页面时,标准的分裂策略是将页面一分为二。但这个分裂点附近的数据可能长期保持稀疏——后续的随机插入不太可能恰好落到这些位置。
更糟糕的是,随机插入还会导致页合并与分裂的"拉锯战"。当删除操作腾出空间后,页面可能低于MERGE_THRESHOLD(默认50%)触发合并。但随即的随机插入又可能迫使合并后的页面再次分裂。这种反复操作不仅消耗CPU资源,还会产生大量的redo log。
PlanetScale的测试数据揭示了性能差距的量级:在数据量超过内存容量的场景下,UUIDv4的写入速度可能比顺序插入慢10到50倍。写入放大是罪魁祸首——每条记录的插入都可能触发页分裂,而每次分裂都会产生额外的I/O和日志记录。
主键选择:架构决策的深远影响
主键的选择不仅是数据建模的问题,更是性能架构的基石。不同类型的主键会导致截然不同的页分裂行为:
自增整数(AUTO_INCREMENT):最经典的选择,插入位置固定在最右侧,页面填充率高,分裂频率最低。缺点是在分布式系统中难以协调,且存在信息泄露风险。
UUID v4:128位完全随机值,插入位置不可预测,导致最频繁的页分裂。在聚簇索引场景下,问题被放大:二级索引也必须存储主键值,UUID的288位(CHAR(36)存储)或128位(BINARY(16)存储)会显著增加所有索引的体积。
UUID v1/v6/v7:时间戳前缀版本。UUID v1将时间戳放在高位,理论上具有顺序性,但时间戳字节的排列方式使其在排序上不够理想。UUID v6和v7重新设计了时间戳的排列,使生成值在排序上更接近时间顺序。这些版本在保持全局唯一性的同时,部分缓解了随机插入的问题。
雪花算法(Snowflake ID):结合时间戳、机器ID和序列号的64位整数。按时间近似有序,在分布式系统中易于协调。相比UUID,存储空间减半,且具有良好的局部性。
Percona的另一项研究通过可视化方式展示了不同主键的页面分布。自增主键呈现出紧凑的蓝色块(高密度页面),而UUID主键则是大片的粉红色斑点(低密度、分散的页面)。
不同数据库的分裂策略
B+树是几乎所有关系型数据库的标准索引结构,但不同实现在页分裂策略上存在微妙差异。
MySQL InnoDB:采用中点分裂策略,将满页面一分为二。没有专门的填充因子参数用于常规插入,但innodb_fill_factor控制批量创建索引时的填充率。对于在线事务,InnoDB自动保留1/16的空间。
PostgreSQL:提供fillfactor参数,默认值为90%,可在创建索引时指定。较低的填充因子为后续的插入和更新预留空间,减少分裂频率。PostgreSQL的B-tree还实现了去重(deduplication)机制,对于重复键值可以更紧凑地存储。
SQL Server:同样提供fillfactor参数,默认100%(无预留空间)。SQL Server区分"好的"和"坏的"页分裂:在最右追加导致的分裂被视为"好的",而在中间位置插入导致的分裂则是"坏的"。通过Extended Events可以监控分裂的类型和频率。
DB2 for z/OS:实现了非对称分裂优化。当检测到顺序插入模式时,DB2会采用非50/50的分裂比例,保留更多空间在原页面用于后续插入。这种智能策略进一步减少了顺序场景下的分裂次数。
Latch竞争:分裂的隐形代价
页分裂不仅产生I/O开销,在并发场景下还会引发锁竞争问题。分裂操作需要获取索引树上的排他latch(x-latch),这会阻塞其他试图访问同一索引的操作。
SQL Server的官方文档详细描述了这种竞争模式。在高并发插入场景下,多个线程可能同时竞争最后的叶子页面,形成"最后页插入竞争"。即使都使用自增主键,这种竞争依然存在,只是被限制在最右侧的一个页面。
微软为此引入了OPTIMIZE_FOR_SEQUENTIAL_KEY选项(SQL Server 2019),通过在内存中缓冲最后页的插入来缓解竞争。类似的优化思路在其他数据库中也有体现。
随机插入场景下的竞争更为严重。分裂可能发生在树的任何位置,竞争点分散在整个索引树上。虽然看起来竞争被分散了,但实际上增加了不确定性——任何插入都可能被任意位置的分裂阻塞。
监控与诊断
识别页分裂问题需要关注多个维度的指标:
-- MySQL: 查看页分裂和合并统计
SELECT name, count, status
FROM INFORMATION_SCHEMA.INNODB_METRICS
WHERE name IN ('index_page_splits', 'index_page_merge_attempts',
'index_page_reorg_attempts', 'index_page_reorg_successful');
-- MySQL: 查看表的碎片化程度
SELECT table_name, data_free, data_length,
data_free / (data_length + data_free) AS fragmentation_ratio
FROM INFORMATION_SCHEMA.TABLES
WHERE table_schema = 'your_database';
页分裂频率异常高的典型症状包括:
- 插入性能随数据量增长而持续下降
- 存储空间占用远超预期
- redo log增长速度异常快
- Buffer Pool命中率下降
优化策略
理解页分裂机制后,优化方向变得清晰:
主键设计优先考虑顺序性。如果业务允许,自增整数是最佳选择。分布式场景下,雪花算法或UUID v7比UUID v4好得多。一个常见的折中方案是:内部使用自增整数作为主键,对外暴露UUID作为业务标识。
避免不必要的随机二级索引。每个二级索引都是一个独立的B+树,随机键值的二级索引同样会遭遇频繁分裂。评估索引的必要性,删除不常用的索引。
定期执行索引维护。OPTIMIZE TABLE(MySQL)或REINDEX(PostgreSQL)会重建索引,消除碎片,恢复页面紧凑性。对于高写入表,建议在维护窗口定期执行。
调整填充因子。对于已知会有大量随机插入的索引,可以设置较低的填充因子。这会牺牲一些存储空间,但减少分裂频率。PostgreSQL中创建索引时指定:CREATE INDEX ... WITH (fillfactor = 70)。
考虑表分区。如果数据按时间维度增长,可以将表按时间分区。每个分区是一个独立的物理结构,新数据写入最新分区,旧分区相对稳定。这种模式天然减少了分裂压力。
写在最后
页分裂是B+树维护平衡的必要操作,本身并非缺陷。但当它与随机写入模式相遇时,其代价会被放大到令人不安的程度。
数据库内核开发者们一直在寻找优化方案。B-link树、Bε-tree、LSM-tree等变种从不同角度尝试改进。但在可见的未来,理解并顺应B+树的行为模式,仍然是数据库设计者和运维者的必备技能。
选择自增主键还是UUID,不是非黑即白的决定。关键是理解每种选择在页分裂层面的含义,然后根据具体的业务场景——写入模式、数据规模、可用资源——做出权衡。有时候,接受一定程度的性能下降换取分布式友好性是合理的;有时候,坚持顺序插入是性能优先的唯一答案。
无论选择什么,都应该有意识地监控页分裂的影响,在问题暴露之前发现趋势,在系统不堪重负之前进行调整。数据库性能优化从来不是一劳永逸的工作,而是持续观察、分析和调整的过程。
参考资料
-
MySQL 8.4 Reference Manual: The Physical Structure of an InnoDB Index. https://dev.mysql.com/doc/refman/8.4/en/innodb-physical-structure.html
-
Marco Tusa. InnoDB Page Merging and Page Splitting. Percona, 2017. https://www.percona.com/blog/innodb-page-merging-and-page-splitting/
-
Brian Morrison II. The Problem with Using a UUID Primary Key in MySQL. PlanetScale, 2024. https://planetscale.com/blog/the-problem-with-using-a-uuid-primary-key-in-mysql
-
PostgreSQL 16 Documentation: B-Tree Implementation. https://www.postgresql.org/docs/16/btree-implementation.html
-
Bayer R., McCreight E. Organization and maintenance of large ordered indices. Proceedings of the 1970 ACM SIGFIDET Workshop, 1970.
-
IBM DB2 12 for z/OS: Index splitting for sequential INSERT activity. https://www.ibm.com/docs/en/db2-for-zos/12.0.0?topic=performance-index-splitting-sequential-insert-activity
-
Microsoft SQL Server Documentation: Diagnose and Resolve Latch Contention. https://learn.microsoft.com/en-us/sql/relational-databases/diagnose-resolve-latch-contention
-
Comer D. The Ubiquitous B-Tree. ACM Computing Surveys, 1979.