2011年2月3日,迈阿密一场特别的仪式上,ICANN将最后五个/8的IPv4地址块分配给全球五大区域互联网注册管理机构(RIR)。这意味着,IANA掌管的IPv4地址池正式耗尽。当时的预测是:IPv6将在数年内成为主流。
十四年过去了。根据Google的统计,截至2025年初,全球IPv6普及率刚刚超过43%。这个数字听起来不错,但距离"主流"仍有相当距离——超过一半的互联网流量仍在IPv4上运行。更关键的是,这个普及率在过去几年呈现出明显的增长停滞趋势。
一个设计于1998年、能够提供340涧(3.4×10³⁸)个地址的协议,为什么在地址耗尽的倒逼下,依然难以普及?
NAT:一场持续二十五年的缓兵之计
理解IPv6普及困境,必须从IPv4的"续命药"——NAT说起。
1994年,网络地址转换(NAT)技术首次在RFC 1631中提出。它的核心思想很简单:让多台设备共享一个公网IP地址。企业内网使用私有地址段(如10.0.0.0/8、192.168.0.0/16),在网关处进行地址转换,对外只暴露一个公网地址。
图片来源: www.networkacademy.io
{kind=link}
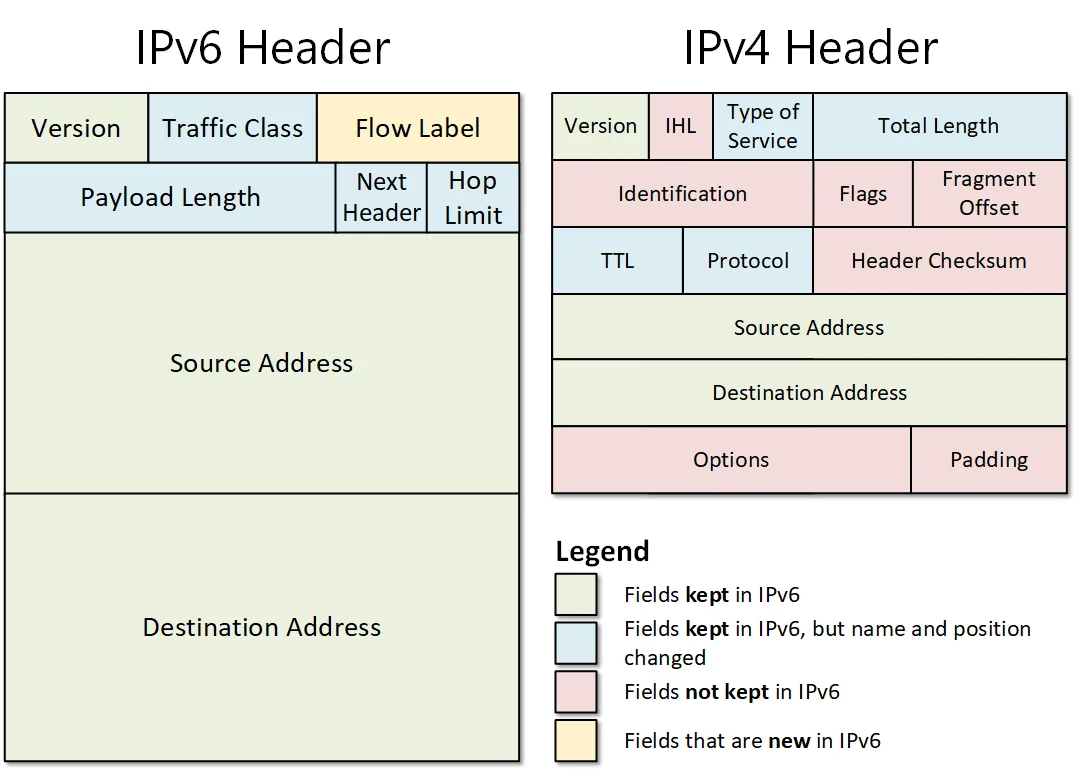
IPv6的头部设计相比IPv4更加简洁。IPv6头部固定为40字节,去掉了IPv4中的校验和、分片相关字段、选项字段等,让路由器处理效率更高。但这个"更优秀的设计"并没有成为普及的驱动力——因为NAT让IPv4"够用了"。
这个"权宜之计"彻底改变了互联网的地址经济学。原本每个设备都需要一个公网IP,现在一个/24网段(256个地址)就可以支撑数万台设备。更重要的是,NAT带来了意外的安全收益——内网设备对外不可见,天然形成了一道防火墙。
NAT的成功带来了一个悖论:它消除了IPv6普及的最强驱动力——地址稀缺。当运营商可以通过NAT让100个用户共享一个公网IP时,为什么还要花钱部署IPv6?当企业可以通过私有地址无限扩展内网时,为什么还要申请IPv6地址块?
Carrier-Grade NAT(CGN)将这个逻辑推向极致。运营商级别的NAT让数万用户共享一个公网地址池,每个用户只能获得一个私有地址。根据Cloudflare的技术分析,CGN虽然解决了IPv4地址短缺问题,却引入了新的复杂性:端口耗尽、连接跟踪表爆炸、P2P应用失灵、用户无法从外部访问家庭网络。
但这些都成了"可以忍受的问题"。CGN的部署成本虽然不低——据估算约150万美元每万用户——但与全面升级到IPv6相比,仍然是更便宜的选项。
结果形成了一个残酷的经济逻辑:NAT让IPv4的"苟延残喘"变得足够便宜,以至于IPv6的"长远正确"显得不够紧迫。
双栈:被迫背负的两套系统
当IPv6部署终于提上日程时,业界选择了一个看似稳妥的策略:双栈(Dual Stack)。即同时运行IPv4和IPv6两套协议栈,让网络能够处理两种流量。
双栈的问题在于,它不是迁移,而是叠加。
想象一下,你是一家企业的网络管理员。原本只需要维护一套IPv4网络:IP地址规划、路由配置、防火墙规则、监控告警。现在,你需要同时维护两套完全独立的网络。IPv6的地址格式不同、配置命令不同、故障排查工具不同、安全策略也不同。你的工作量翻倍,但用户感知不到任何改善——他们不会因为有了IPv6就觉得网速更快、体验更好。
图片来源: www.networkacademy.io
{kind=link}
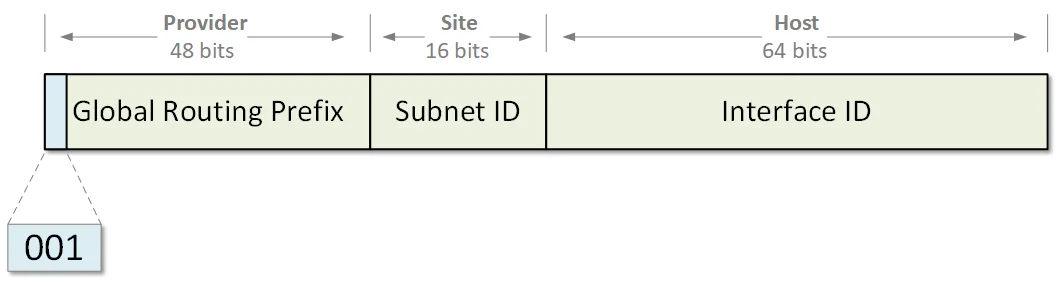
IPv6地址为128位,通常分为全局路由前缀(48位)、子网ID(16位)和接口标识符(64位)。这种结构化的设计便于路由聚合,但也让地址规划变得更加复杂。
更麻烦的是,两套协议栈的行为并不总是一致。一个在IPv4上正常工作的应用,可能在IPv6上神秘失败。原因可能是DNS解析顺序问题,可能是防火墙配置遗漏,也可能是某个中间设备不支持IPv6分片。这些"只见IPv4不见IPv6"的隐性故障,让运维团队疲于奔命。
ARIN(美国互联网号码注册管理机构)在2019年的博客文章中详细分析了双栈的经济学:IPv6部署不仅带来初始投资成本,还意味着长期的运维复杂性增加。设备需要支持双协议栈、团队需要培训两种技能、监控需要覆盖两个平面。对于已经拥有充足IPv4地址的企业来说,这笔投资的回报周期可能长达3-5年。
一项针对企业网络的调查显示,平均每个IPv6部署项目的成本约为240万美元。这包括硬件升级、软件许可、人员培训、测试验证等。对于一家中型企业来说,这是一笔不小的开支。更关键的是,这笔投资的"收益"是什么?除了"为未来做准备",几乎没有任何立竿见影的商业价值。
Happy Eyeballs:连接的隐形延迟
当你打开一个同时支持IPv4和IPv6的网站时,你的浏览器会优先尝试IPv6连接。这本应是好事——IPv6连接通常更干净,没有NAT的额外开销。但问题在于:IPv6连接可能失败,而失败的方式往往是沉默的。
假设你访问的网站有一个配置错误的IPv6地址。浏览器首先尝试IPv6连接,等待超时(可能是几秒甚至几十秒),然后才回退到IPv4。用户看到的症状是"网站打开很慢",但完全不知道这是因为IPv6失败导致的。
这就是为什么RFC 6555提出了Happy Eyeballs算法。它的核心思想是:同时发起IPv6和IPv4连接,谁先成功用谁。IPv6连接会先启动,但如果250毫秒内没有建立,就立即启动IPv4连接作为备份。
Happy Eyeballs有效缓解了"IPv6黑洞"问题,但它也揭示了一个深层困境:IPv6的可靠性仍然不足以让用户放心地优先使用它。根据APNIC的分析,相当比例的网络存在IPv6可达性问题,而这些问题往往在用户投诉前都不会被发现。
更复杂的是,Happy Eyeballs的实现因浏览器而异。Firefox严格遵循RFC推荐的250毫秒延迟,Chrome采用更激进的多连接策略,而某些老旧应用可能根本不实现这个算法。这导致同样的网络环境,在不同应用中可能表现出完全不同的行为。
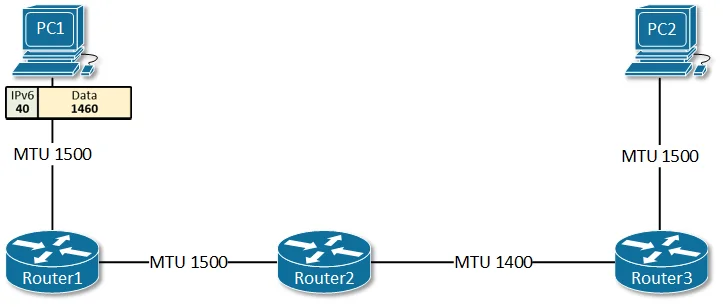
PMTU黑洞:沉默的数据包丢失
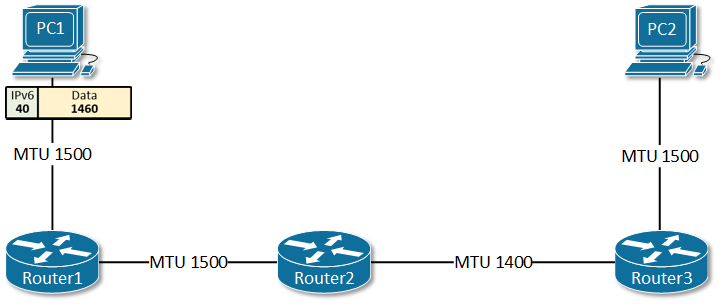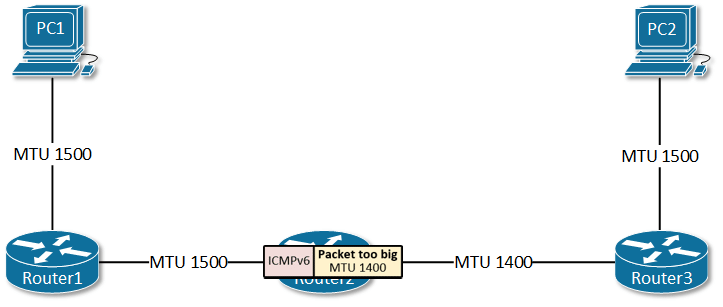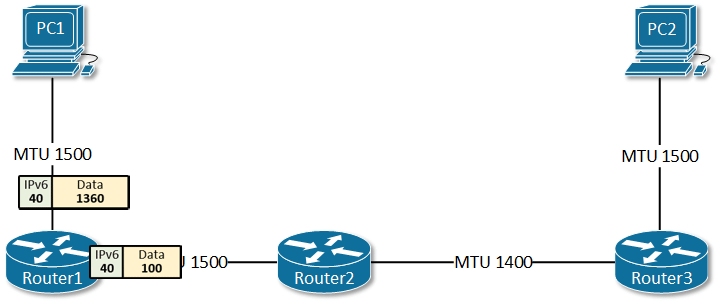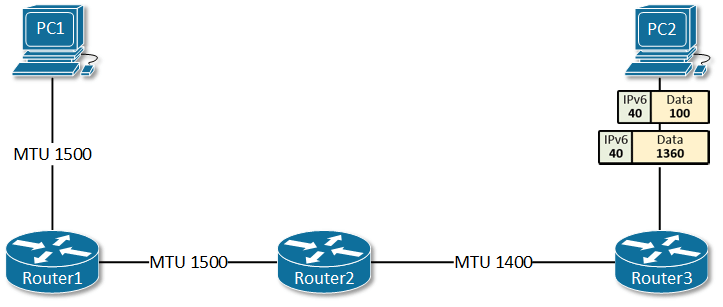
Path MTU Discovery(路径最大传输单元发现)是IPv6设计中的一个关键差异。在IPv4中,路由器可以分片过大的数据包;但在IPv6中,分片只能在源端进行,路由器遇到超过MTU的数据包会直接丢弃并返回ICMPv6 “Packet Too Big"消息。
这个设计的初衷是减轻路由器负担、提高转发效率。但它引入了一个致命问题:如果ICMPv6消息被防火墙过滤掉,源端永远不会知道数据包太大,连接就会陷入沉默失败。
Cloudflare在部署ECMP负载均衡时遇到了这个问题。他们的Anycast IP收到的ICMPv6消息被过滤掉了,导致PMTU Discovery完全失效。某些用户会经历神秘的连接失败——小数据包能通,大数据包被无声丢弃。这种故障极难诊断,因为它发生在网络层,应用层看不到任何错误信息。
图片来源: www.networkacademy.io
{kind=link}
IPv6规范要求最小MTU为1280字节(IPv4的最小MTU是576字节),这缓解了部分问题。但PPP over Ethernet(PPPoE)等链路的MTU可能只有1492字节,而某些隧道协议可能进一步降低MTU。当这些链路上的设备配置错误时,PMTU黑洞就会出现。
RIPE NCC的研究显示,全球约有1-2%的IPv6路径存在PMTU问题。这个比例听起来很低,但对于全球规模的互联网服务来说,意味着数百万用户可能受影响。
安全盲区:防火墙遗漏的IPv6
IPv6的另一个隐形成本是安全配置。
传统上,企业网络安全团队的工作重心是IPv4。防火墙规则、入侵检测系统、流量分析工具——一切都围绕IPv4构建。当IPv6流量开始出现时,这些安全措施往往"默认允许”,因为它们根本没有针对IPv6的规则。
RFC 9099明确指出:在未配置适当过滤规则的情况下启用IPv6流量,会增加网络的攻击面。IPv6的邻居发现协议(NDP)可能被滥用进行地址欺骗攻击;IPv6路由器通告(RA)可能被伪造以劫持流量;IPv6的扩展头部可能被用于绕过安全检测。
更微妙的问题是安全团队对IPv6的陌生感。一个熟悉IPv4子网划分和访问控制列表(ACL)的安全工程师,面对IPv6的/64前缀和全新的地址类型时,往往需要重新学习。这种知识差距导致IPv6的安全配置要么过度宽松,要么干脆禁用。
加拿大网络安全中心在2025年的指南中强调:组织在启用IPv6之前,必须确保网络安全监控和过滤能力已经覆盖IPv6流量。否则,IPv6可能成为一个"隐形通道",让攻击者绕过所有IPv4安全措施。
设备支持:最后一公里的陷阱
即使ISP和企业完成了IPv6部署,还有一个容易被忽视的瓶颈:用户端设备(CPE)。
家庭路由器是IPv6普及的"最后一公里"。大量老旧路由器根本不支持IPv6,或者支持得有缺陷。DHCPv6前缀委派(PD)配置复杂,SLAAC(无状态地址自动配置)与DHCPv6的选择让用户困惑,而某些路由器的IPv6实现存在内存泄漏等严重bug。
2024年Reddit上的一个讨论引发了广泛共鸣:不支持IPv6的路由器应该被视为"有缺陷产品"。消费者购买路由器时很少考虑IPv6支持,因为IPv4"能用"。但当ISP升级到IPv6-only时,这些路由器就成了废品。
移动网络的IPv6支持相对较好,因为运营商对终端设备有更强的控制力。但在固定宽带领域,用户自购路由器的碎片化状况让IPv6部署变得异常复杂。ISP需要在技术支持层面处理大量"我的路由器不支持IPv6"的投诉,这增加了运维成本。
过渡技术:修补与妥协的艺术
面对上述种种困境,业界开发了一系列过渡技术,试图在IPv4和IPv6之间架起桥梁。
NAT64/DNS64 是最主流的方案。DNS64将IPv4的A记录"合成"为IPv6的AAAA记录,使用一个特殊的IPv6前缀(通常是64:ff9b::/96);NAT64则在实际通信时将IPv6地址转换为IPv4地址。这让IPv6-only的客户端能够访问IPv4-only的服务器,但前提是服务器端的DNS和NAT配置都正确。
464XLAT 在NAT64基础上增加了一层转换,让IPv4-only的应用也能在IPv6-only网络上运行。它在客户端运行一个CLAT(Customer-side translator),将应用的IPv4流量封装为IPv6,经过网络后端的PLAT(Provider-side translator)转换后再发送到IPv4互联网。这个方案在移动网络上广泛部署,因为大多数智能手机应用仍以IPv4为主。
DS-Lite(Dual Stack Lite) 采用相反的思路:让IPv4流量跑在IPv6隧道上。客户端的IPv4流量被封装为IPv6,发送到运营商的AFTR(Address Family Transition Router),解封后再进入IPv4互联网。这种方案避免了运营商层面的NAT444,但增加了隧道开销。
MAP-E/MAP-T 是更复杂的状态less映射方案,试图让多个用户共享一个公网IPv4地址的不同端口范围。它的优势是不需要运营商维护大量的连接状态,但配置复杂度很高,且对某些应用(如需要固定端口的P2P软件)不友好。
这些过渡技术的共同特点是:它们都是妥协,都在增加网络的复杂性,都在某种程度上牺牲了端到端的透明性。没有一种方案是完美的,每一种都有其适用场景和局限性。而运营这些复杂过渡机制的成本,往往被忽视在IPv6迁移的ROI计算之外。
中国路径:政策驱动的跨越式发展
在全球IPv6普及版图中,中国是一个独特的存在。
根据中国互联网络信息中心(CNNIC)的数据,截至2024年7月,中国IPv6活跃用户数达7.98亿,在网民中占比73.04%。移动网络IPv6流量占比达64.31%,固定网络IPv6流量占比达21.34%。这些数字远超全球平均水平。
中国的IPv6推进模式具有明显的"顶层设计"特征。2017年,中共中央办公厅、国务院办公厅印发《推进互联网协议第六版(IPv6)规模部署行动计划》,设定了明确的时间表和目标。2024年的《深入推进IPv6规模部署和应用2024年工作安排》进一步要求"优先开展IPv6网络调优,逐步实现IPv6网络时延、丢包率等关键指标优于IPv4"。
这种政策驱动的模式有其优势:运营商、互联网企业、政府机构都在明确的指令下推进IPv6部署,避免了"别人不动我也不动"的观望心态。中国电信、中国移动、中国联通等基础运营商在移动网络上实现了IPv6的全覆盖,头部互联网应用(如微信、淘宝、抖音)也完成了IPv6改造。
但中国的模式也面临挑战。固网宽带的IPv6流量占比仍显著低于移动网络,反映出家庭网络和中小企业网络改造的滞后。用户端设备(尤其是老旧路由器)的IPv6支持不足,限制了IPv6的实际使用。更重要的是,IPv6的"普及"不等同于"优先使用"——很多用户虽然获得了IPv6地址,但他们的流量仍主要通过IPv4传输。
印度模式:移动网络率先突破
印度的IPv6普及路径与中国形成鲜明对比。根据APNIC的统计,印度的IPv6能力率已超过70%,位居全球前列。但这一成就主要来自移动网络——Jio等运营商在4G/5G网络上大规模部署了IPv6-only架构。
印度的特点是:固定宽带基础设施薄弱,移动互联网是绝对主流。这反而成为了IPv6普及的机遇——运营商没有"历史包袱",可以直接部署IPv6-only网络,配合464XLAT等过渡技术处理IPv4流量。
Jio的案例尤其值得关注。这家运营商从建网之初就将IPv6作为首选协议,避免了IPv4地址获取的巨额成本。他们的用户设备(智能手机)天然支持IPv6,应用层通过过渡机制访问IPv4内容。这种"轻装上阵"的模式,让印度在IPv6普及率上实现了对许多发达国家的超越。
印度的经验表明:IPv6普及的最大障碍不是技术,而是历史资产的"粘性"。当一张网络从零开始建设时,IPv6是自然的选择;当一张网络已经深度依赖IPv4时,迁移的阻力会大得多。
未来:IPv6-only的必然性
尽管普及缓慢,IPv6-only的时代终将到来。推动这一转变的,不是地址耗尽的紧迫性,而是运营成本的考量。
当CGN的规模持续扩大时,它的运维成本会越来越高。端口耗尽需要更大的地址池,连接跟踪表需要更多的内存,故障排查需要更复杂的工具。某个时间点,继续维护IPv4基础设施的成本将超过迁移到IPv6的成本。
移动网络可能率先实现IPv6-only。大多数现代智能手机应用已经支持IPv6,运营商对终端设备有完全的控制权,用户对底层协议几乎没有感知。当运营商停止为IPv4流量付费时,IPv6-only就会成为经济上的最优解。
企业网络的IPv6-only转型会更慢,因为企业有更多的"遗留系统"——老旧的应用服务器、专用的网络设备、缺乏IPv6支持的第三方服务。但随着云服务商(如AWS、Azure、Google Cloud)全面支持IPv6,企业应用的IPv6改造成本正在降低。
最终,IPv6普及可能遵循一个非线性的路径:长时间的缓慢增长后,突然达到某个临界点,然后迅速加速。这个临界点可能是某个大型ISP决定停止IPv4服务,可能是某个主要云平台要求客户使用IPv6,也可能是某个国家政策明确淘汰IPv4。
在那之前,双栈、NAT64、464XLAT——这些过渡技术将继续存在,继续增加互联网的复杂性,继续提醒我们:一个好的技术方案,不仅需要技术上的正确性,更需要经济上的可行性。
参考资料
- ICANN, “Available Pool of Unallocated IPv4 Internet Addresses Now Completely Emptied”, February 3, 2011
- Google IPv6 Statistics, https://www.google.com/intl/en/ipv6/statistics.html
- APNIC IPv6 Measurement, https://labs.apnic.net/ipv6-measurement/
- RFC 6555, “Happy Eyeballs: Success with Dual-Stack Hosts”, 2012
- RFC 8305, “Happy Eyeballs Version 2: Better Connectivity Using Concurrency”, 2018
- RFC 9099, “Operational Security Considerations for IPv6 Networks”, 2021
- ARIN Blog, “Economic Factors Affecting IPv6 Deployment”, 2019
- Cloudflare Blog, “Fixing an old hack - why we are bumping the IPv6 MTU”, 2018
- SCIRP, “Challenges and Benefits of Shifting from IPv4 to IPv6”, 2024
- IETF Draft, “Pros and Cons of IPv6 Transition Technologies for IPv4aaS”, 2022
- Roland Berger, “Global IPv6 Development Report 2024”
- 中国互联网络信息中心(CNNIC),《中国IPv6发展状况白皮书(2024)》
- 中央网信办,《深入推进IPv6规模部署和应用2024年工作安排》
- Network Academy, “IPv4 vs IPv6 - Understanding the differences”
- Wikipedia, “IPv6 deployment”, “IPv4 address exhaustion”