1971年,ACM Computing Surveys发表了一篇题为《System Deadlocks》的论文。作者Edward G. Coffman Jr.、M. J. Elphick和Arie Shoshani系统阐述了死锁发生的四个必要条件——互斥、持有并等待、非抢占、循环等待。这篇论文奠定了此后半个多世纪死锁研究的理论基础。然而,五十年过去了,死锁仍然是数据库系统中最常见的生产事故之一。2021年,北卡罗来纳州立大学的研究团队对106个数据库后端Web应用进行调研,收集了49个真实的死锁案例。研究发现,跨请求的数据库锁死锁不仅最常见,也是现有工具最难处理的类型。
死锁的数学本质
死锁的本质是一个图论问题。将每个事务视为图中的一个节点,如果事务A正在等待事务B持有的锁,则从A到B画一条有向边。这张图被称为等待图(Wait-for Graph)。当且仅当等待图中存在环路时,系统处于死锁状态。
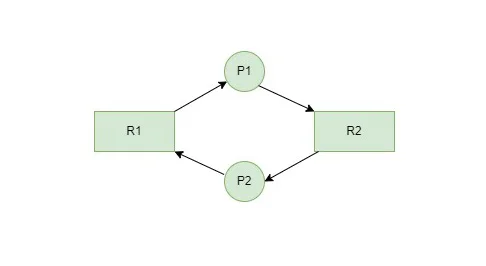
图片来源: media.geeksforgeeks.org
{kind=link}
Coffman等人的贡献在于,他们证明了死锁发生的充要条件:四个条件必须同时成立。这意味着,只要能破坏其中任何一个条件,死锁就不会发生。但这四个条件的破坏代价各不相同。
互斥条件几乎无法破坏——数据库的本质就是并发访问共享数据,如果所有资源都可共享,锁机制就失去了意义。
非抢占条件同样难以改变——强制抢占正在执行的事务持有的锁,意味着事务必须回滚,这在语义上是不可接受的。
因此,实际可行的策略集中在持有并等待和循环等待两个条件上。
检测而非预防:主流数据库的选择
主流数据库系统几乎都选择了"检测-恢复"而非"预防"的策略。这并非偶然。
Wait-for Graph的代价
Wait-for Graph检测需要在每次锁请求时检查是否形成环路。理论上,这需要遍历整个等待图,时间复杂度为O(V+E),其中V是等待中的事务数,E是等待关系数。
在高并发系统中,这个开销不容忽视。更重要的是,构建和维护等待图本身也需要内存和CPU资源。PostgreSQL的设计文档明确指出:“The check for deadlock is relatively expensive, so the server doesn’t run it every time it waits for a lock."(死锁检查相对昂贵,所以服务器不会在每次等待锁时都执行。)
PostgreSQL的惰性检测
PostgreSQL采用了"惰性检测"策略。事务请求锁时,如果锁不可用,事务会先进入等待状态。只有在等待时间超过deadlock_timeout参数(默认1秒)后,才会触发死锁检测。
-- PostgreSQL死锁检测配置
SET deadlock_timeout = '1s'; -- 等待1秒后才开始检测
SET log_lock_waits = on; -- 记录长时间锁等待
这种设计基于一个假设:大多数锁等待会在短时间内解决,真正的死锁是少数情况。因此,与其为每次锁等待付出检测开销,不如等一段时间再检测。代价是,当死锁真的发生时,事务至少要等待1秒才会被检测到。
MySQL InnoDB的积极检测
MySQL InnoDB采用了更积极的策略。对于简单的两事务死锁,InnoDB可以立即检测。但对于复杂场景,它也会退化为周期性检测。
-- MySQL InnoDB死锁检测配置
SET innodb_lock_wait_timeout = 50; -- 最大等待时间(秒)
SET innodb_deadlock_detect = ON; -- 启用死锁检测
SET innodb_print_all_deadlocks = ON; -- 记录所有死锁
InnoDB的检测算法经历了重大演进。在8.0.17之前,检测算法需要在锁系统上执行DFS遍历,这要求在检测期间锁定整个锁系统——在高并发场景下成为严重瓶颈。
8.0.18引入了全新的"稀疏图"算法。核心洞察是:不需要构建完整的等待图,只需要为每个事务记录一个等待指针,指向它等待的那个事务。这样,图的结构被极大简化,检测可以在常量内存中完成。
MySQL官方博客详细描述了这个算法。简单来说,如果存在死锁环路,那么环路中的事务一定都在等待状态——它们不会消失。因此,可以在不"停止世界"的情况下,对等待事务数组进行快照,然后在快照上执行环路检测。
SQL Server的折中方案
SQL Server的Lock Monitor每5秒执行一次死锁检测。在高争用场景下,检测频率会提高。victim选择基于两个因素:事务优先级和回滚成本。默认情况下,回滚成本最低的事务会被选为victim。
-- 设置事务优先级
SET DEADLOCK_PRIORITY LOW; -- 低优先级事务更可能被选为victim
SET DEADLOCK_PRIORITY HIGH; -- 高优先级事务更可能存活
-- 启用死锁跟踪
DBCC TRACEON(1222, -1); -- 输出详细死锁信息到错误日志
Victim选择:回滚谁?
当死锁被检测到后,必须选择一个事务作为victim进行回滚。这看似简单,实则涉及复杂的权衡。
MySQL InnoDB倾向于选择"轻量级"事务——即插入、更新或删除行数较少的事务。这个策略的假设是:回滚小事务的代价更低,对系统的影响更小。
SQL Server则考虑更多因素:事务优先级、日志使用量、已执行时间等。管理员可以通过SET DEADLOCK_PRIORITY显式指定事务优先级,这在某些场景下非常有用——例如,后台批处理任务可以设置低优先级,优先保护前台用户请求。
PostgreSQL则选择触发死锁检测的事务作为victim——通常是最后请求锁的那个事务。这个策略简单直接,但可能不是最优选择。
预防策略:从理论到实践
既然检测和恢复有开销,为什么不直接预防死锁?
Wait-Die与Wound-Wait
Wait-Die和Wound-Wait是两种经典的基于时间戳的死锁预防策略,由Rosenkrantz、Stearns和Lewis于1978年在ACM Transactions on Database Systems上提出。
Wait-Die(非抢占):如果请求事务比持有事务更老,则等待;否则,请求事务"死亡”(回滚)。
Wound-Wait(抢占):如果请求事务比持有事务更老,则"伤害"持有事务(强制其回滚);否则,请求事务等待。
| 策略 | 老事务请求年轻事务持有的锁 | 年轻事务请求老事务持有的锁 |
|---|---|---|
| Wait-Die | 等待 | 年轻事务死亡 |
| Wound-Wait | 年轻事务被伤害 | 等待 |
这两种策略都能保证无死锁,因为它们都确保了等待关系是单向的——只允许按时间戳顺序等待。
然而,这些策略在实践中很少被数据库系统采用。原因在于:它们需要维护全局时间戳,且可能导致大量事务被不必要地回滚。对于短事务为主的OLTP系统,这种开销难以接受。
银行家算法:理论上的完美
Edsger Dijkstra在1970年代提出的银行家算法是最著名的死锁避免算法。它通过预先检查资源分配是否会导致不安全状态,来避免死锁。
但银行家算法有一个致命缺陷:它要求事务在开始时声明所需的最大资源数。这对于数据库系统是不现实的——SQL查询的锁需求取决于执行计划,而执行计划可能在运行时才确定。
应用层的统一锁顺序
最有实用价值的预防策略发生在应用层:统一锁顺序。
如果所有事务都按相同顺序获取锁,循环等待条件就被破坏了。这是最简单、最有效的死锁预防方法。
-- 危险:不同事务按不同顺序访问表
-- 事务1
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE orders SET status = 'paid' WHERE account_id = 1;
-- 事务2
UPDATE orders SET status = 'pending' WHERE account_id = 2;
UPDATE accounts SET balance = balance + 50 WHERE id = 2;
-- 安全:统一按accounts -> orders顺序访问
-- 事务1
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
UPDATE orders SET status = 'paid' WHERE account_id = 1;
-- 事务2(修正顺序)
UPDATE accounts SET balance = balance + 50 WHERE id = 2;
UPDATE orders SET status = 'pending' WHERE account_id = 2;
然而,在实践中统一锁顺序并不容易。北卡罗来纳州立大学的研究发现了12种不同的死锁模式,其中很多涉及隐式锁获取——外键检查、唯一索引检查、间隙锁等。这些隐式锁的获取顺序不受应用代码控制。
InnoDB的锁复杂性
InnoDB的锁系统远比"行锁"复杂。它包含多种锁类型:
- Record Lock:锁定索引记录
- Gap Lock:锁定索引记录之间的间隙
- Next-Key Lock:Record Lock + Gap Lock
- Insert Intention Lock:插入操作在插入前获取的间隙锁
这些锁类型在Repeatable Read隔离级别下组合使用,导致了复杂的死锁场景。
-- 一个经典的Gap Lock死锁示例
CREATE TABLE t (id INT PRIMARY KEY);
INSERT INTO t VALUES (1), (3), (5);
-- 事务1
BEGIN;
SELECT * FROM t WHERE id = 4 FOR UPDATE; -- 获取(3,5)间隙的Gap Lock
-- 事务2
BEGIN;
SELECT * FROM t WHERE id = 2 FOR UPDATE; -- 获取(1,3)间隙的Gap Lock
-- 事务1继续
INSERT INTO t VALUES (2); -- 被事务2的Gap Lock阻塞
-- 事务2继续
INSERT INTO t VALUES (4); -- 被事务1的Gap Lock阻塞 → 死锁!
这个例子来自MySQL官方手册。两个SELECT FOR UPDATE语句锁定了不同的间隙,但随后两个INSERT语句分别需要对方的间隙锁,形成死锁。
生产环境的真实代价
北卡罗来纳州立大学的研究对36个来自真实Web应用的死锁进行了分类,发现了四种主要的环路模式:
- 嵌套事务:单个线程开启多个数据库连接,形成自死锁
- 简单环路:两个事务、两个资源
- 多事务共享锁环路:多个事务持有同一共享锁,然后都请求排他锁
- 锁队列环路:InnoDB锁等待队列形成的复杂环路
其中,第三种和第四种模式最难理解和调试。它们涉及InnoDB内部的锁队列机制,应用开发者往往无法从错误日志中推断出根本原因。
研究的另一个发现是:修复策略相对简单。36个案例中,28个通过完全消除死锁可能性来修复:
- 改变查询顺序统一锁顺序(3例)
- 移除不必要的查询(3例)
- 移除不必要的SELECT FOR UPDATE(1例)
- 移除不必要的事务(4例)
- 应用层锁避免并发(3例)
- 顺序执行避免并发(3例)
- 改变查询或逻辑避免冲突(7例)
- 避免嵌套事务(3例)
- 改用缓存(1例)
另外5例通过减少事务长度或资源请求数来降低死锁概率,3例采用"捕获并重试"策略接受死锁的存在。
分布式系统:死锁的新维度
在分布式数据库中,死锁检测变得更为复杂。没有单一节点拥有完整的等待图,检测算法必须在节点间协调。
经典的分布式死锁检测算法包括:
- 集中式:一个节点收集所有等待信息
- 层次式:等待图按层次组织,逐层上报
- 分布式:检测信息沿着等待路径传播
然而,分布式死锁检测面临根本性挑战:网络延迟意味着任何节点的信息都可能过时。这导致了"幻影死锁"问题——检测到死锁时,死锁可能已经自行解除。
现代分布式数据库往往选择避免分布式事务。Google Spanner使用TrueTime API和两阶段提交,但代价是延迟。CockroachDB和TiDB采用分布式事务协议,但也需要在性能和一致性间权衡。
应用层的生存指南
对于应用开发者,以下策略可以有效降低死锁风险:
1. 统一表访问顺序
这是最有效的预防措施。在代码评审时,检查所有事务是否按相同顺序访问表。
2. 缩短事务范围
# 危险:事务中包含外部调用
def transfer(account_from, account_to, amount):
with transaction():
deduct(account_from, amount)
external_api.notify(account_from) # 可能耗时数秒
credit(account_to, amount)
# 安全:外部调用放在事务外
def transfer(account_from, account_to, amount):
deduct(account_from, amount)
credit(account_to, amount)
external_api.notify(account_from) # 在事务提交后执行
3. 实现重试机制
死锁是并发系统的固有现象,100%避免不现实。对于被选为victim的事务,应自动重试。
import time
import random
from sqlalchemy.exc import OperationalError
def execute_with_retry(func, max_retries=3):
for attempt in range(max_retries):
try:
return func()
except OperationalError as e:
if 'deadlock' in str(e).lower() and attempt < max_retries - 1:
# 指数退避 + 抖动
delay = (2 ** attempt) * 0.1 + random.uniform(0, 0.1)
time.sleep(delay)
else:
raise
4. 优化索引
缺少索引会导致全表扫描,事务可能锁定比预期更多的行。
-- 危险:无索引的WHERE条件导致全表扫描
UPDATE orders SET status = 'shipped' WHERE customer_name = 'John';
-- 安全:为查询条件创建索引
CREATE INDEX idx_orders_customer_name ON orders(customer_name);
UPDATE orders SET status = 'shipped' WHERE customer_name = 'John';
5. 选择合适的隔离级别
Serializable隔离级别虽然最安全,但并发性最差。Read Committed隔离级别锁的范围更小,死锁概率更低。
结语
死锁是并发系统的固有属性,不是可以彻底消除的bug。五十年来,从操作系统的资源分配到数据库的事务调度,研究者们提出了各种检测和预防算法。然而,没有任何一种方案能够完美平衡性能、正确性和实现复杂度。
对于数据库系统,“检测-恢复"成为主流选择,因为它在大多数情况下性能最优。对于应用开发者,统一锁顺序、缩短事务范围、实现重试机制是最实用的策略。理解底层的锁机制和检测算法,能够帮助诊断和解决那些看似随机的死锁问题。
最后,记住Coffman论文的洞见:只要破坏四个条件中的任何一个,死锁就不会发生。问题是,我们要为此付出多大代价。
参考资料
- Coffman, E. G., Elphick, M., & Shoshani, A. (1971). System Deadlocks. ACM Computing Surveys, 3(2), 67-78.
- Rosenkrantz, D. J., Stearns, R. E., & Lewis, P. M. (1978). System Level Concurrency Control for Distributed Database Systems. ACM Transactions on Database Systems, 3(2), 178-198.
- Knapp, E. (1987). Deadlock Detection in Distributed Databases. ACM Computing Surveys, 19(4), 303-328.
- Qiu, Z., Shao, S., Zhao, Q., & Jin, G. (2021). A Characteristic Study of Deadlocks in Database-Backed Web Applications. IEEE ISSRE.
- MySQL Reference Manual. (2024). InnoDB Deadlock Detection. Oracle Corporation.
- PostgreSQL Documentation. (2024). Lock Management. PostgreSQL Global Development Group.
- Microsoft Learn. (2022). SQL Server Deadlocks Guide. Microsoft Corporation.
- Arpit Bhayani. (2024). Why Do Databases Deadlock and How Do They Resolve It. arpitbhayani.me.
- MySQL Blog. (2021). InnoDB Data Locking – Part 3: Deadlocks. Oracle Corporation.
- GeeksforGeeks. (2025). Wait For Graph Deadlock Detection in Distributed System.