一个拥有1750亿参数的语言模型,微调时只需训练不到2000万参数——这听起来像是天方夜谭,但微软研究院在2021年发表的论文让这个"魔术"变成了现实。
GPT-3的完整微调需要更新全部1750亿个参数,部署独立微调模型的成本高得惊人。而LoRA(Low-Rank Adaptation,低秩适配)通过一个巧妙的数学技巧,将可训练参数减少了10000倍,GPU内存需求降低3倍,同时保持了与全参数微调相当的模型质量。这不是妥协,而是一个深刻的发现:大模型适应新任务时,真正需要改变的东西远比我们想象的少得多。
权重更新的低秩本质
理解LoRA需要先回答一个根本问题:微调时模型权重到底发生了什么变化?
假设预训练模型的某层权重矩阵为 $W$,维度为 $d_{in} \times d_{out}$。在传统微调中,反向传播会学习一个更新量 $\Delta W$,最终权重变为 $W' = W + \Delta W$。如果 $d_{in} = d_{out} = 4096$(Transformer模型中的常见维度),$\Delta W$ 就包含超过1600万个参数。
LoRA的核心假设是:这个更新量矩阵 $\Delta W$ 的"有效秩"远低于它的完整维度。具体而言,$\Delta W$ 可以被近似分解为两个小矩阵的乘积:
$$\Delta W \approx B \cdot A$$其中 $A$ 的维度是 $d_{in} \times r$,$B$ 的维度是 $r \times d_{out}$,$r$ 是秩(rank)参数。当 $r=8$ 时,参数量从 $d_{in} \times d_{out} = 16,777,216$ 降至 $r \times (d_{in} + d_{out}) = 65,536$——减少了256倍。
图片来源: Sebastian Raschka - Improving LoRA: Implementing DoRA from Scratch
图中左侧展示了全参数微调直接更新权重矩阵 $W$,右侧则展示了LoRA保持原始权重冻结,仅训练低秩矩阵 $A$ 和 $B$。这种设计不仅节省内存,还带来一个意外的好处:部署时可以将LoRA权重合并回原始模型,推理阶段零额外开销。
内在维度:为什么低秩假设成立
低秩分解不是新概念,但为什么它对语言模型微调特别有效?答案藏在一个2020年的重要发现中。
Aghajanyan等人在论文《Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning》中提出了一个惊人的实验:通过随机投影,将RoBERTa模型的微调限制在仅200个参数的子空间中,仍然可以达到完整参数微调90%的性能。他们测量了各种预训练模型的"内在维度"——即完成任务所需的最小自由度——发现这个数字远小于模型的表面参数量。
更反直觉的是,更大的模型往往有更低的内在维度。这解释了为什么大模型虽然参数量暴增,却能在少量数据上高效微调——预训练过程已经在高维空间中"压缩"了任务的有效表示。
LoRA正是利用了这一特性。预训练阶段,模型需要在完整的参数空间中学习语言的通用知识;但微调阶段,任务特定的调整只需要在一个低维子空间中进行。秩 $r$ 本质上定义了这个子空间的维度上限。
关键参数:Rank与Alpha的平衡术
LoRA有两个核心超参数需要调优:秩 $r$ 和缩放因子 $\alpha$(alpha)。理解它们的关系是获得最佳性能的关键。
秩 $r$ 决定了LoRA矩阵的表达能力。较大的 $r$ 允许模型学习更复杂的调整,但也意味着更多的参数和潜在的过拟合风险。原始论文的实验显示,即使在GLUE基准测试上使用 $r=1$,某些任务的表现也已经接近全参数微调。
缩放因子 $\alpha$ 控制LoRA更新的影响力。在实际实现中,LoRA输出会乘以 $\alpha/r$:
$$\text{output} = W \cdot x + \frac{\alpha}{r} (B \cdot A \cdot x)$$Sebastian Raschka在数百次实验后总结出一个实用的启发式:$\alpha = 2 \times r$ 通常是一个好的起点。当 $r=8$、$\alpha=16$ 时,缩放比例为2倍。但这种关系并非绝对——在特定模型和数据集上,$r=256$、$\alpha=128$(0.5倍缩放)反而可能表现更好。
| 秩 $r$ | 可训练参数量 (7B模型) | 适用场景 |
|---|---|---|
| 1-8 | ~400万 | 简单任务、资源受限 |
| 16-64 | ~800-3200万 | 通用微调 |
| 128-256 | ~6400万-1.28亿 | 复杂任务、多样数据 |
表格来源:根据Sebastian Raschka实验数据整理
一个容易忽视的细节是目标模块的选择。原始论文建议在注意力层的Query和Value矩阵上应用LoRA,但后续研究表明,扩展到所有线性层(包括MLP)能显著提升性能。代价是参数量增加约5倍,但对于追求质量的场景,这是一个值得的权衡。
QLoRA:把65B模型塞进单卡GPU
LoRA已经大幅降低了微调门槛,但仍然需要加载完整的16位模型权重。对于650亿参数的模型,这意味着至少130GB显存——远超消费级硬件的能力。
2023年,Dettmers等人提出了QLoRA(Quantized LoRA),将量化技术与LoRA结合,实现了在单张48GB GPU上微调65B模型。核心技术包括:
- 4位NormalFloat量化:一种专门为正态分布权重设计的量化格式,比标准4位整数精度更高
- 双重量化:对量化常数本身也进行量化,进一步节省内存
- 分页优化器:处理GPU显存尖峰,避免OOM崩溃
实际测试中,QLoRA节省约33%的GPU内存,代价是训练时间增加约39%。这个权衡对资源受限的开发者极具吸引力——用时间换空间,让个人也能参与大模型微调。
| 方法 | 精度 | 内存占用 (7B模型) | 训练时间 |
|---|---|---|---|
| 全参数微调 | 16-bit | ~100GB | 基准 |
| LoRA | 16-bit | ~21GB | 1.85h |
| QLoRA | 4-bit | ~14GB | 2.79h |
表格来源:Sebastian Raschka实测数据
DoRA:分离幅度与方向
LoRA并非完美无缺。2024年的一项研究指出,LoRA与全参数微调产生的权重更新存在结构性差异——LoRA倾向于同时按比例改变权重的幅度和方向,而全参数微调则能够独立调整两者。
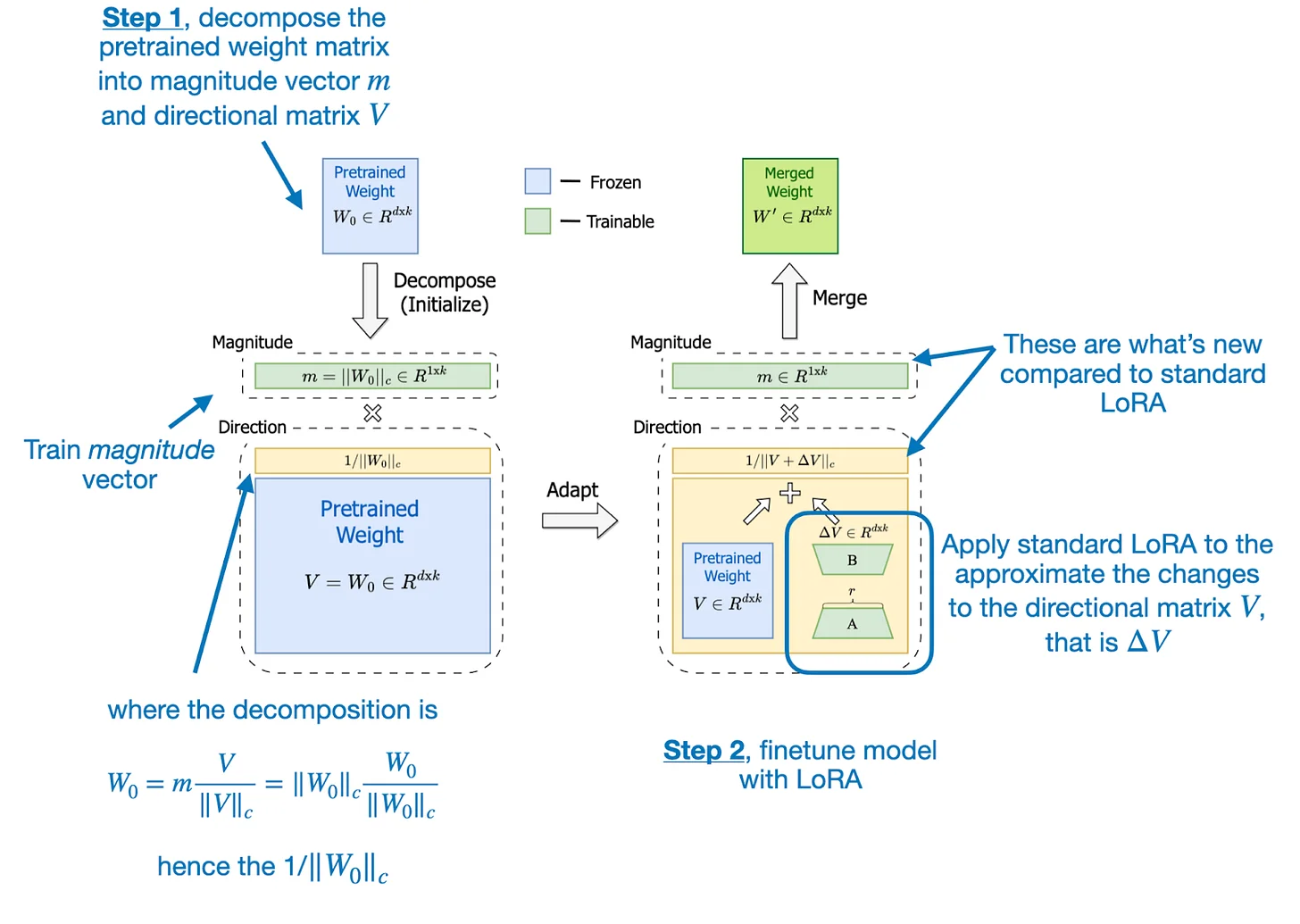
这个观察催生了DoRA(Weight-Decomposed Low-Rank Adaptation)。DoRA的核心创新是将权重分解为两个组件:
$$W = m \cdot V$$其中 $m$ 是幅度向量,$V$ 是方向矩阵。DoRA对 $V$ 应用标准LoRA,同时单独学习 $m$。这种解耦使得模型能够更精细地控制权重的变化模式。
图片来源: DoRA论文
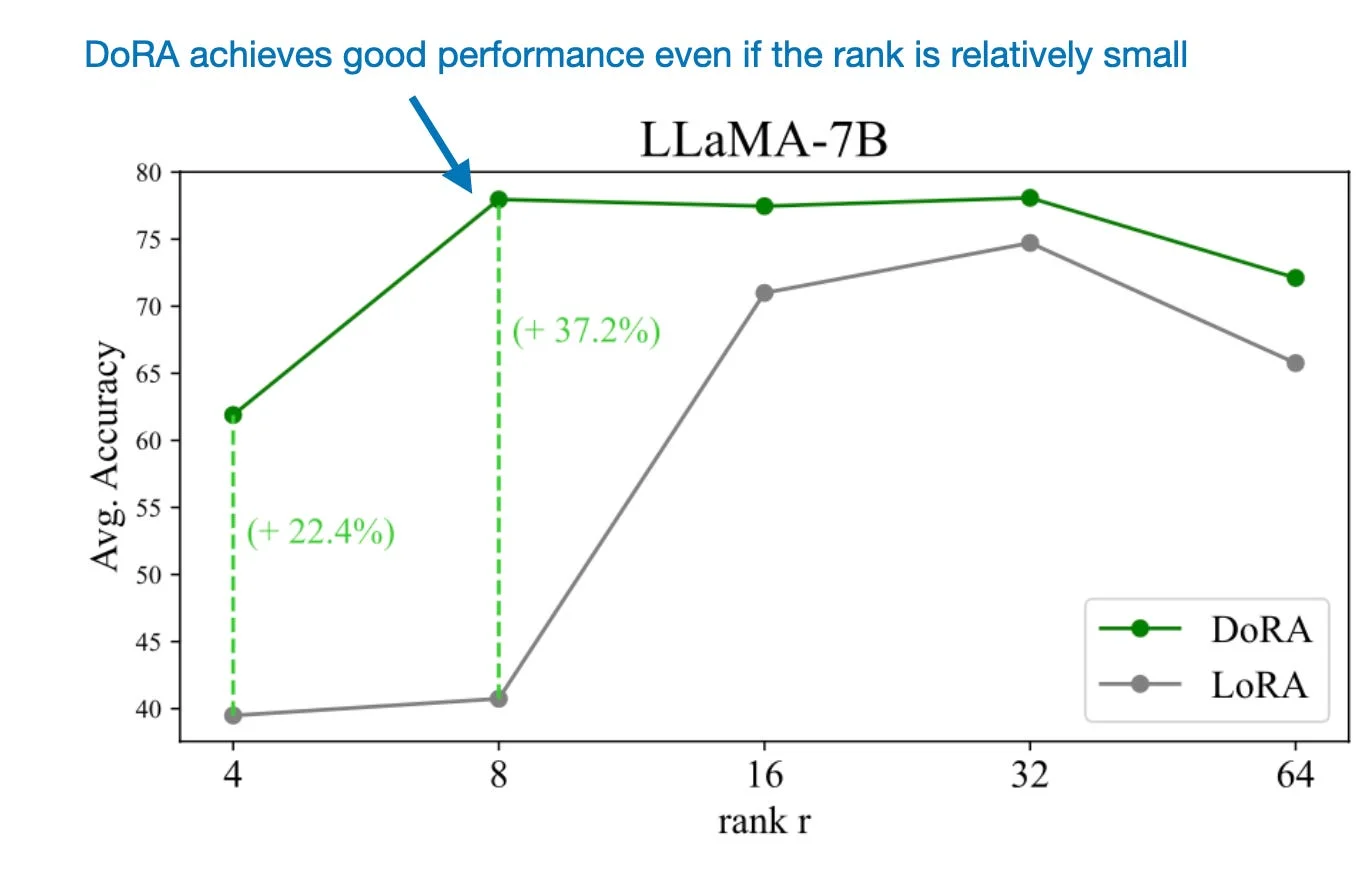
实验结果显示,DoRA在相同秩设置下一致优于LoRA。更令人惊讶的是,DoRA即使使用一半的秩(即一半的参数量),仍然能够超越原始LoRA。幅度向量 $m$ 仅增加0.01%的额外参数,却带来了显著的性能提升。
局限与权衡
LoRA及其变体并非适用于所有场景。2025年发表的一篇论文《LoRA vs Full Fine-tuning: An Illusion of Equivalence》揭示了几个关键问题:
入侵维度(Intruder Dimensions):LoRA微调后的模型会出现全参数微调中不存在的高秩维度,这些维度可能导致模型在持续学习场景下的性能下降。
大批次训练退化:当批次大小增大时,LoRA的性能下降速度比全参数微调更快。这可能与低秩约束在梯度累积中的行为有关。
领域适应的局限:LoRA擅长调整模型的"行为模式"(如指令遵循),但在注入新的领域知识方面效果有限。知识主要通过预训练获得,微调更多是激活已有的能力。
另一个常被讨论的问题是灾难性遗忘。由于LoRA冻结了原始权重,理论上应该更好地保留预训练知识。但实践表明,如果微调数据过于偏向特定任务,模型仍然可能"忘记"其他能力。一个务实的建议是:在微调数据中包含一些原始任务的示例,以维持模型的通用能力。
工程实践指南
基于上述分析,以下是LoRA微调的最佳实践总结:
参数选择:
- 秩 $r$:从8开始,根据任务复杂度调整。简单任务可能只需要 $r=4$,复杂任务可能需要 $r=256$
- Alpha $\alpha$:默认设为 $2 \times r$,但值得尝试不同比例
- 目标模块:若资源允许,覆盖所有线性层
训练策略:
- 避免多轮训练(超过1-2个epoch),防止过拟合
- 使用静态数据集时,优先扩展数据多样性而非增加迭代次数
- 考虑使用QLoRA而非标准LoRA以节省内存
部署优化:
- 训练后合并LoRA权重到基础模型,消除推理开销
- 多租户场景下保持LoRA权重独立,动态加载
从理论到实践的飞跃
LoRA的成功不仅仅是一个算法优化,它揭示了深度学习的一个深层规律:模型的有效表达能力可能远低于其参数量所暗示的。预训练过程将语言的复杂性压缩到一个低维流形上,微调只是在这个流形上找到一个特定的点。
这个发现的影响是深远的。它让个人开发者能够微调千亿参数模型,让企业能够以可控成本部署定制化AI,让学术研究能够在有限资源下探索大模型的前沿。从LoRA到QLoRA再到DoRA,这一技术路线的演进展示了深度学习社区如何将理论洞见转化为工程实践。
当然,LoRA不是万能的。它无法替代预训练获取新知识,在某些场景下性能仍落后于全参数微调。但对于绝大多数应用场景,它提供了一个效率与效果之间几乎完美的平衡点。当你下次面对一个需要微调的大模型时,不妨先问问:我真的需要更新那几十亿参数吗?也许几千分之一就足够了。
参考文献
- Hu, E. J., et al. (2021). LoRA: Low-Rank Adaptation of Large Language Models. arXiv:2106.09685
- Aghajanyan, A., et al. (2020). Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning. arXiv:2012.13255
- Dettmers, T., et al. (2023). QLoRA: Efficient Finetuning of Quantized LLMs. arXiv:2305.14314
- Liu, S., et al. (2024). DoRA: Weight-Decomposed Low-Rank Adaptation. arXiv:2402.09353
- Raschka, S. (2023). Practical Tips for Finetuning LLMs Using LoRA. Ahead of AI Magazine
- Hayou, S., et al. (2024). LoRA+: Efficient Low Rank Adaptation of Large Models. PMLR v235