困惑度如何成为语言模型评估的黄金标准:从信息论到现代大模型的五十年演进
一个语言模型的好坏,究竟该如何衡量? 假设你训练了两个语言模型。模型A对句子"猫坐在垫子上"给出了0.01的概率,模型B给出了0.001的概率。哪个模型更好?直觉告诉我们模型A更好——它对真实存在的句子赋予了更高的概率。但如果模型A对所有句子都赋予高概率呢?包括那些毫无意义的句子组合? ...
一个语言模型的好坏,究竟该如何衡量? 假设你训练了两个语言模型。模型A对句子"猫坐在垫子上"给出了0.01的概率,模型B给出了0.001的概率。哪个模型更好?直觉告诉我们模型A更好——它对真实存在的句子赋予了更高的概率。但如果模型A对所有句子都赋予高概率呢?包括那些毫无意义的句子组合? ...
在神经网络的输出层,我们经常看到这样一个公式: $$\text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{K} e^{z_j}}$$它看起来如此简单——指数、求和、归一化。但为什么是这个特定的形式?为什么不直接除以总和?为什么要有指数?为什么这个函数能统治从图像分类到大语言模型的几乎所有概率输出? ...
同样的文本内容,在一个模型中可能只需要100个token,在另一个模型中却可能膨胀到300个。这背后的差异源于一个经常被忽视但至关重要的设计决策:词表大小的选择。 ...
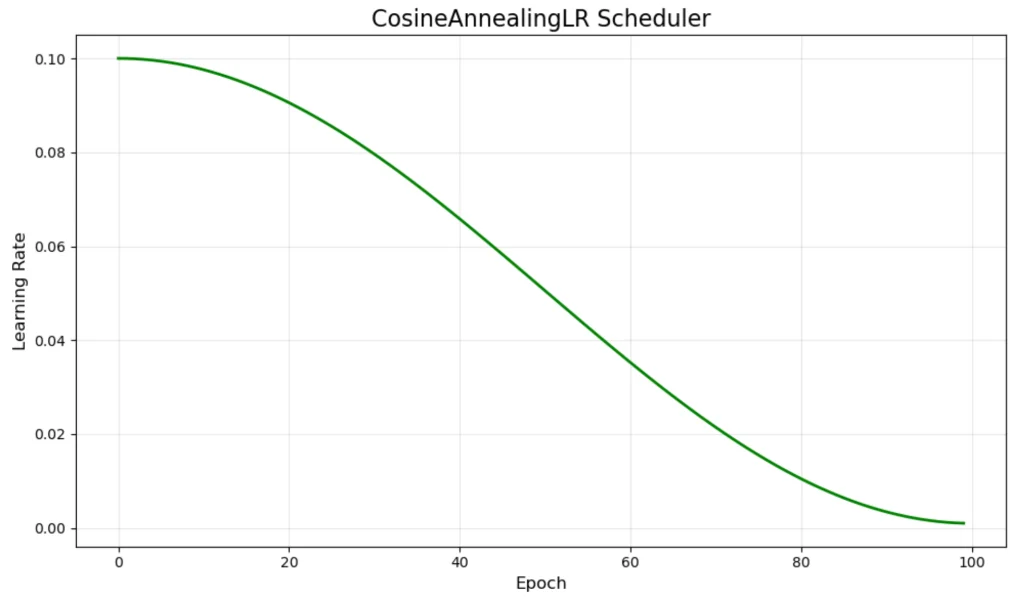
训练过大模型的人都知道,学习率是最关键的超参数之一。设置得太小,训练几个月也收敛不了;设置得太大,模型直接发散。但即使找到了一个看似合适的初始值,直接从头到尾使用恒定学习率,效果往往也不尽如人意。 ...
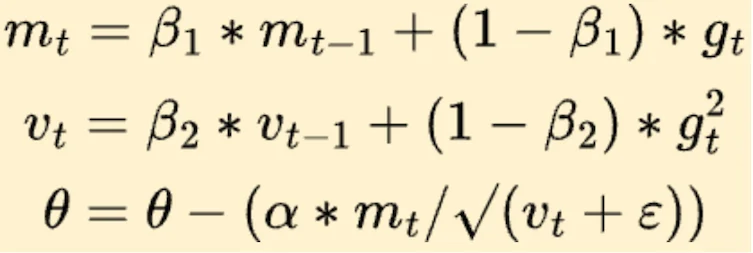
打开任何一个大语言模型的训练代码——GPT-3、LLaMA、BERT、Mistral——你会发现一个惊人的共性:它们清一色使用AdamW优化器。不是经典的随机梯度下降(SGD),不是带动量的SGD,而是AdamW。 ...
2017年,Transformer论文发表时,作者选择了一个看似平淡无奇的组件作为前馈神经网络(FFN)的激活函数:ReLU。这个在2011年被重新发现的函数,因其计算简单、梯度稳定而成为深度学习的标配。然而,到了2023年,几乎所有新发布的大语言模型——LLaMA、PaLM、Mistral——都在FFN层抛弃了ReLU,转而采用一个名字拗口的组合:SwiGLU。 ...

当我们与一个训练完成的大语言模型对话时,它似乎能理解我们的问题、组织连贯的回答、甚至在某些领域展现出接近专家的知识水平。但这个"智能体"并非凭空诞生——在它能说出第一句话之前,背后是一个历时数月、耗资千万美元、涉及万亿级token的复杂训练过程。 ...