2005年4月6日,Linus Torvalds在Linux内核邮件列表中写道:「我一直在考虑自己写一个SCM。」第二天,他做出了第一个提交——用Git自己提交Git的代码。这个最初只有约10,000行代码的工具,在接下来二十年里彻底改变了软件协作的方式。
2025年,在Git诞生20周年的访谈中,Linus回顾道:「我本来以为CVS会一直占据市场,我写Git只是为了解决自己的问题,根本没指望它会流行起来。」
Git的成功不是偶然。它采用了一套看似「笨拙」但实则精妙的设计:内容寻址存储、有向无环图(DAG)历史、分布式架构。这些设计决策共同构成了一个既简单又强大的版本控制系统。
一个「反CVS」的宣言
Git的诞生源于一场许可证纠纷。Linux内核社区从2002年开始使用BitKeeper——一个商业版本控制系统。2005年初,BitKeeper的创建者Larry McVoy宣布撤销部分内核开发者的免费许可证,原因是有人逆向工程了BitKeeper。
Linus当时面临一个困境:市面上没有适合Linux内核开发的开源版本控制系统。CVS太慢且设计糟糕,Subversion本质上是「换皮的CVS」,而其他分布式系统要么不成熟,要么性能无法满足需求。
在AOSA(Architecture of Open Source Applications)的访谈中,Linus明确了他的设计目标:
哲学目标:成为「反CVS」
三个实用性目标:
- 支持类似BitKeeper的分布式工作流
- 提供强保护以防止内容损坏
- 高性能——应用100个补丁不应需要「喝杯咖啡的时间」
这三个目标深刻影响了Git的每一个设计决策。
内容寻址存储:为什么「笨」即是好
Git最核心的设计是它的对象数据库——一个内容寻址文件系统(Content-Addressable Filesystem)。
什么是内容寻址?
传统文件系统通过路径(如/home/user/document.txt)定位文件。内容寻址则不同:它通过内容的哈希值来定位内容。
当你向Git存储一段内容时:
echo "hello world" | git hash-object -w --stdin
3b18e512dba79e4c8300dd08aeb37f8e728b8dad
Git返回一个40字符的SHA-1哈希。这个哈希就是内容的「地址」。要检索内容,你只需要知道这个哈希:
git cat-file -p 3b18e512dba79e4c8300dd08aeb37f8e728b8dad
hello world
为什么选择SHA-1?
很多人质疑Git使用SHA-1的决定——尤其是在2017年Google和CWI研究所宣布成功实施SHA-1碰撞攻击(SHAttered)之后。Linus在访谈中解释了他的理由:
「使用SHA-1哈希从来不是为了安全,而是为了检测损坏。」
在BitKeeper时代,内核社区确实遇到过数据损坏问题——BitKeeper使用CRC和MD5,但并非对所有内容都使用。Linus决定Git要保护「绝对所有内容」——每个对象都用一个强哈希保护。
这种设计带来几个关键优势:
完整性保证:任何数据损坏都能被检测。如果磁盘错误改变了一个字节,哈希值将完全不匹配。
去重:相同内容只存储一次。如果你在十个地方引用同一个文件内容,Git只存储一份。
无锁设计:不需要复杂的锁机制。两个开发者同时创建相同内容,会得到相同哈希,不会产生冲突。
图片来源: git-scm.com
{kind=link}
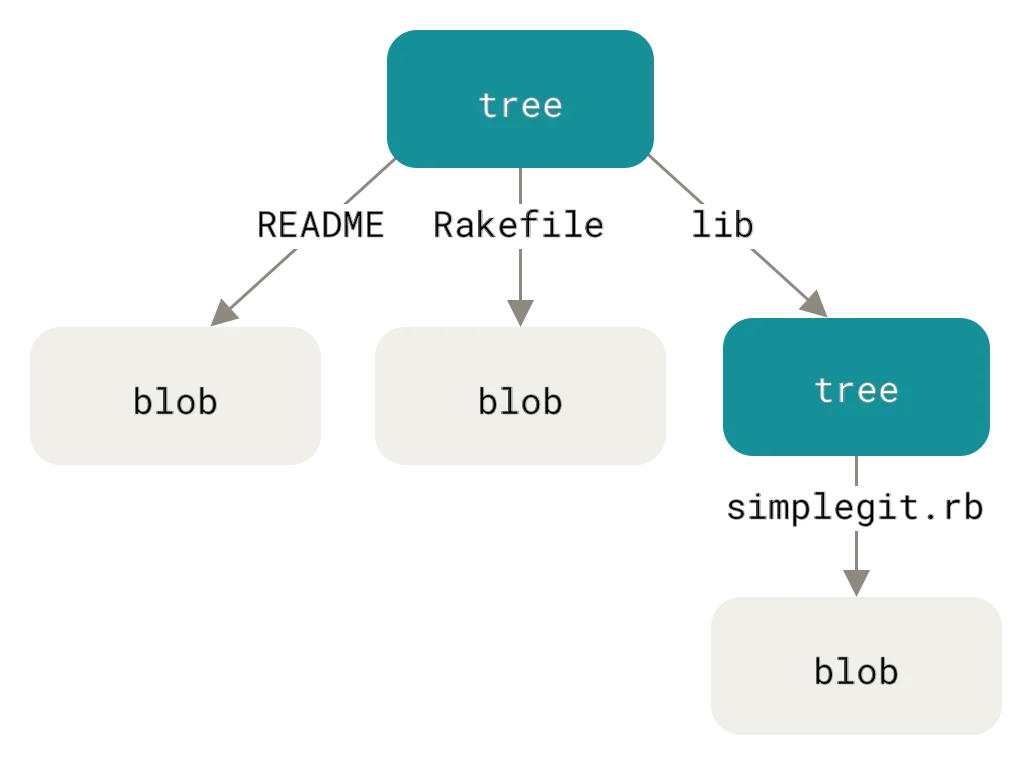
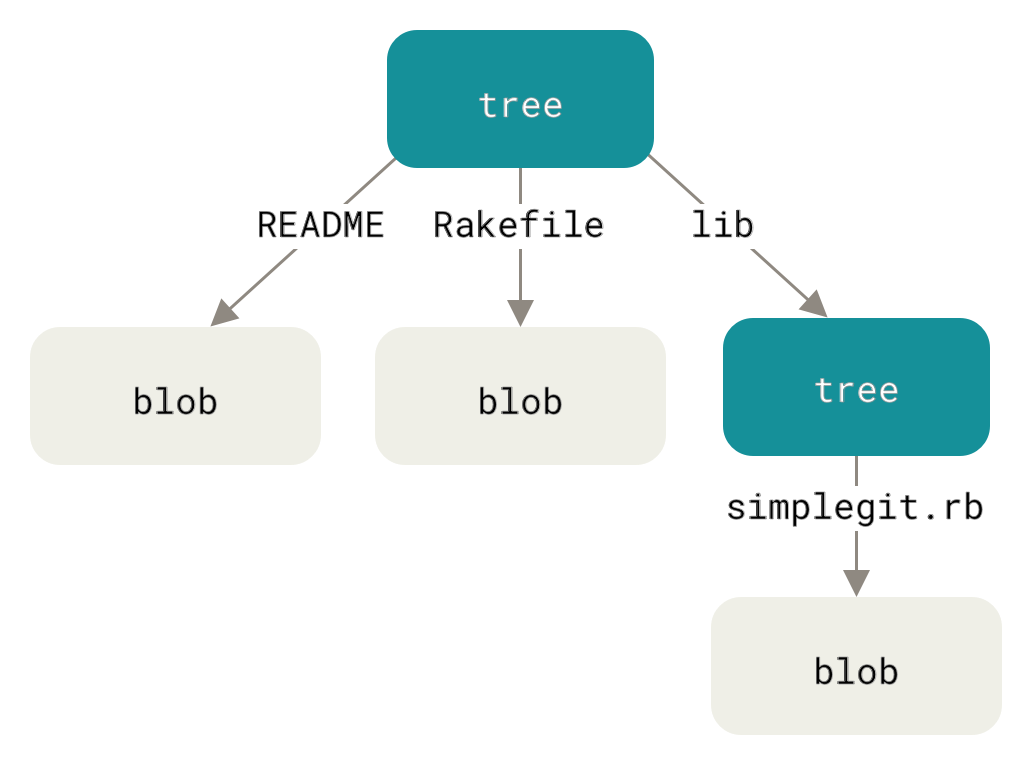
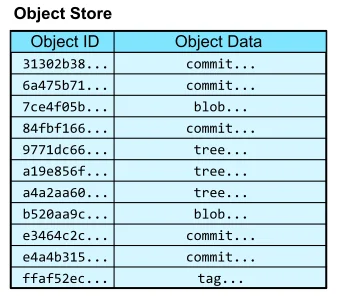
四种对象类型
Git的对象数据库包含四种基本对象类型:
Blob对象:存储文件内容。注意,blob不存储文件名、权限或任何元数据——只有内容本身。
Tree对象:存储目录结构。一个tree包含一系列条目,每个条目指向一个blob(文件)或另一个tree(子目录),同时记录文件名和Unix权限。
Commit对象:存储项目快照。包含指向根目录tree的指针、作者信息、提交信息,以及指向父提交的指针。
Tag对象:存储 annotated tag。包含指向特定对象的指针、标签信息、签名等。
这种分层设计创造了一个有向无环图(DAG):
图片来源: git-scm.com
{kind=link}
对象存储格式
每个Git对象的存储格式是:
[header][content][zlib压缩]
Header格式为:<类型> <字节数>\0
例如,存储"hello world"这个blob:
header = "blob 11\0" # 11是内容字节数
store = header + "hello world"
sha1 = SHA1(store) # 3b18e512dba79e4c8300dd08aeb37f8e728b8dad
compressed = zlib(store)
最终存储路径是.git/objects/3b/18e512dba79e4c8300dd08aeb37f8e728b8dad。
这个设计看似简单,但它有一个重要含义:所有对象都是不可变的。一旦创建,永不改变。这消除了并发访问的复杂性。
Packfile:当「笨」变得聪明
每个文件都独立存储听起来很浪费空间——如果你修改了一个大文件中的一个字符,难道要存储两份完整的文件?
Git的答案是Packfile——一个延迟执行的压缩机制。
Loose Objects vs Packed Objects
初始创建的对象以「松散对象」(loose objects)形式存储——每个对象一个文件,zlib压缩但无增量压缩。这快速但低效。
当运行git gc或对象数量达到阈值时,Git将松散对象打包成packfile。Packfile使用增量压缩(delta compression)——存储对象之间的差异而非完整内容。
图片来源: github.blog
{kind=link}
Delta压缩的原理
Packfile支持两种delta表示:
REF_DELTA:存储基础对象的SHA-1哈希。
OFS_DELTA:存储到基础对象的偏移量(更紧凑)。
Delta编码的核心思想是:给定一个基础对象,用一系列指令重建目标对象。指令只有两种类型:
- 复制:从基础对象复制一段字节
- 插入:插入新的字节数据
这种编码对于文本文件特别高效——大多数修改只是添加、删除或更改少量文本。
Pack Index:快速查找的秘诀
Packfile本身不包含按哈希索引的结构——要查找对象需要扫描整个文件。Git使用pack index(.idx文件)来解决这个问题。
Pack Index包含:
- 256项的fanout表(用于快速二分查找)
- 按哈希排序的对象列表
- 每个对象的CRC32校验和(用于验证压缩数据)
- 每个对象在packfile中的偏移量
查找流程:
- 用对象哈希的前一个字节在fanout表中定位范围
- 在该范围内二分查找
- 找到后获取偏移量
- 从packfile读取对象数据
GitHub的工程师Taylor Blau在博客系列「Git’s database internals」中详细解释了这种设计如何支持大规模仓库的高效操作。
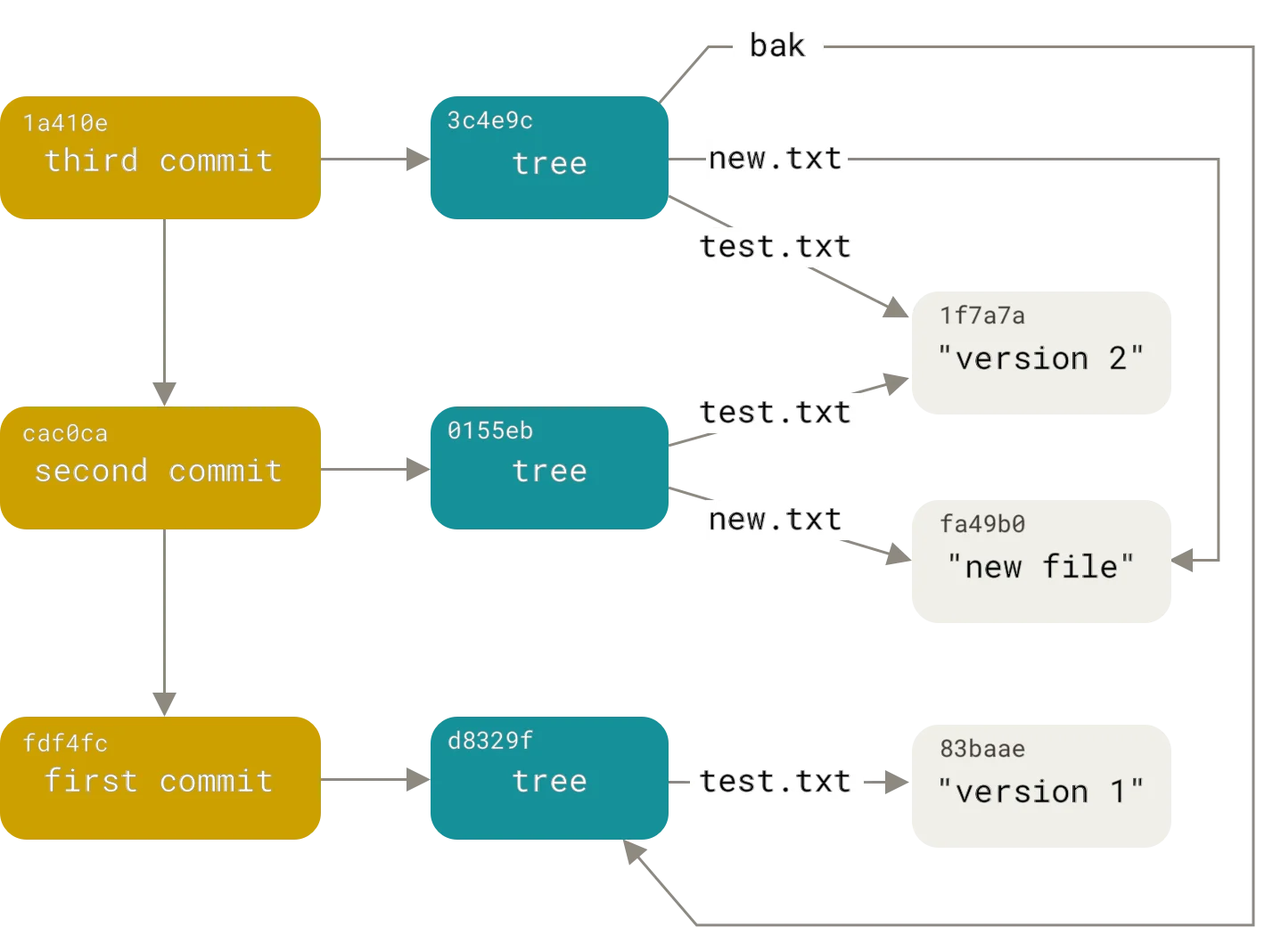
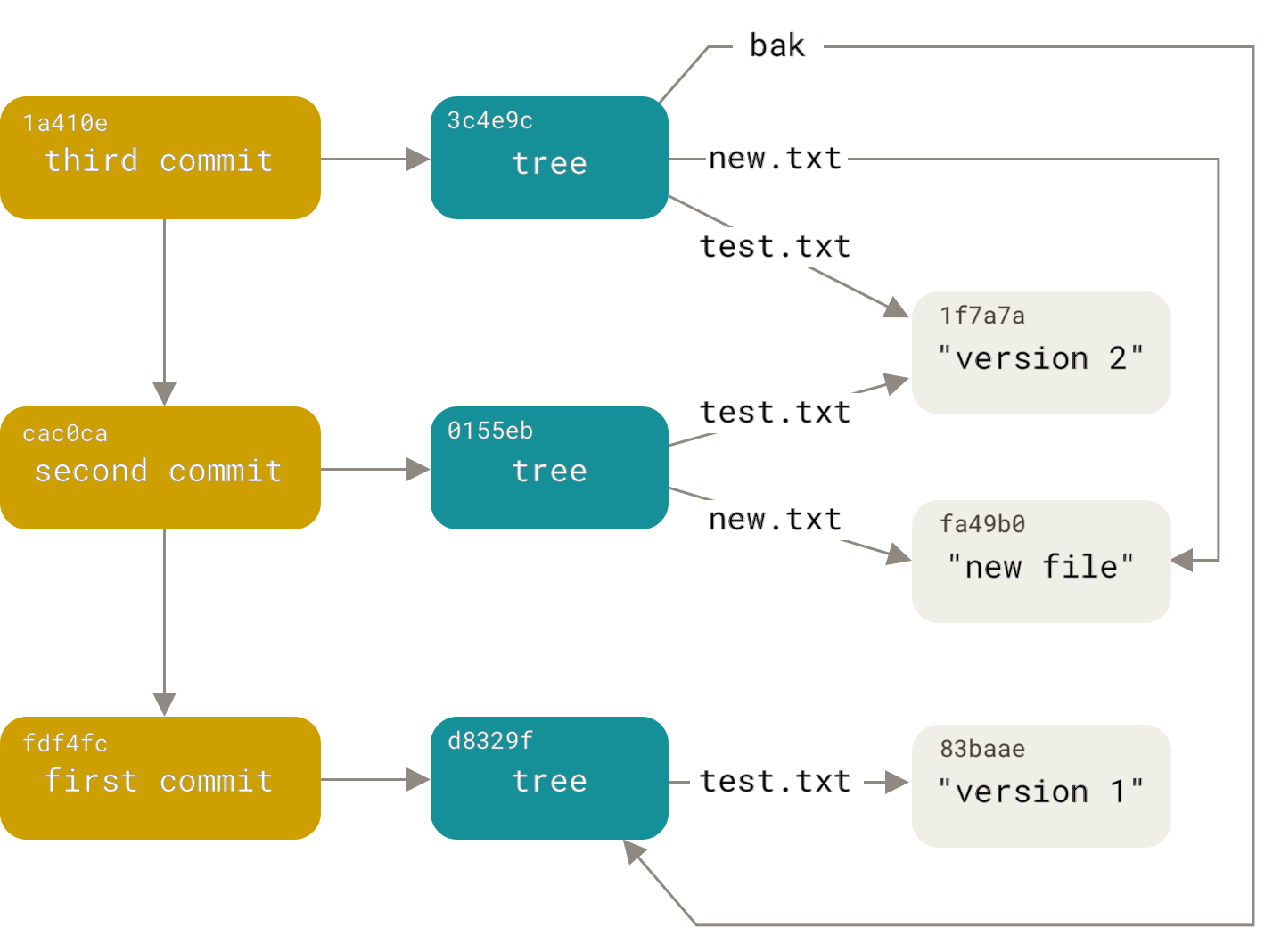
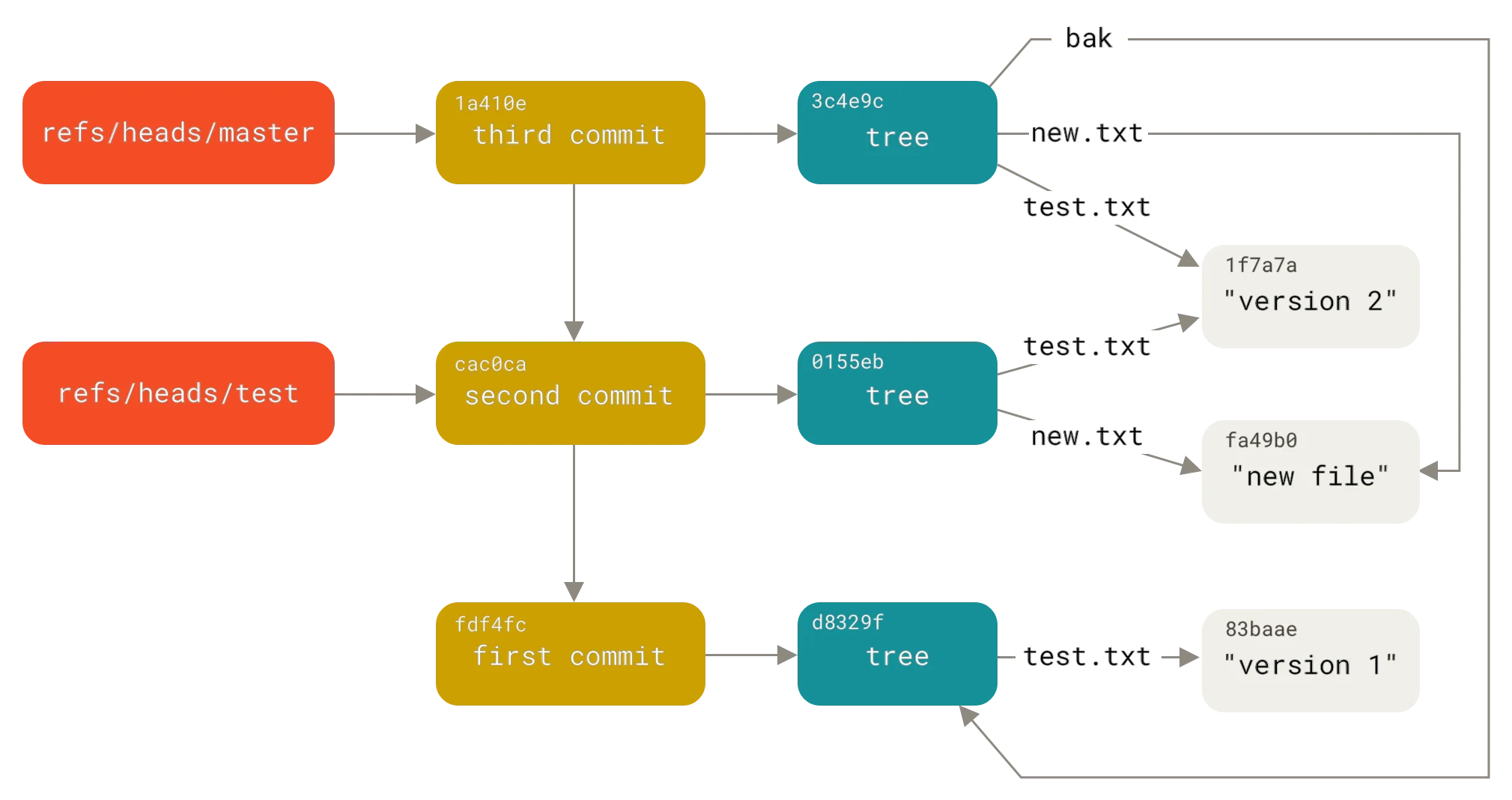
引用:分支只是41字节
Git的分支模型可能是它最被低估的设计。
在Subversion中,创建分支意味着在仓库中复制整个目录树——可能需要几分钟。在Git中,创建分支是瞬时完成的。为什么?
引用的本质
Git的引用(reference或ref)只是包含40字符SHA-1哈希的文本文件。
创建一个分支:
git branch feature
这个命令做的事仅仅是:
echo "a1b2c3d4..." > .git/refs/heads/feature
文件内容是当前提交的哈希值,总共41字节(40个十六进制字符加换行符)。
删除分支:
git branch -d feature
这只是删除一个文件:
rm .git/refs/heads/feature
图片来源: git-scm.com
{kind=link}
HEAD:特殊的引用
.git/HEAD是一个特殊的引用——它通常不直接指向提交,而是「符号引用」(symbolic reference),指向另一个引用:
$ cat .git/HEAD
ref: refs/heads/master
当你执行git checkout feature时,Git只是修改HEAD文件的内容:
$ cat .git/HEAD
ref: refs/heads/feature
这种设计的优雅之处:分支只是指针,不涉及任何数据复制。
Detached HEAD状态
当HEAD直接指向一个提交(而非分支引用)时,Git处于「detached HEAD」状态:
$ git checkout a1b2c3d
$ cat .git/HEAD
a1b2c3d4e5f6...
这种状态下,新提交不属于任何分支,可能被垃圾回收。理解这个机制对于使用git rebase和git bisect非常重要。
快照 vs 差异:一场哲学辩论
Git与其他版本控制系统最根本的区别在于它如何存储历史。
两种历史模型
Delta-based(CVS、SVN):每次提交存储与前一个版本的差异。要重建某个版本,需要从初始版本开始应用所有差异。
Snapshot-based(Git):每次提交存储完整的目录树快照。未改变的文件通过引用现有blob来避免重复存储。
快照模型的优势
Linus在设计Git时坚持快照模型,原因如下:
完整性:每个提交是一个独立的、自包含的快照。要验证某个版本,不需要检查整个历史链。
性能:检出任意版本不需要应用漫长的差异序列——直接从快照恢复。
分支理解:合并历史是DAG而非线性序列,能准确表示「哪些变更已包含在哪些分支中」。
一个误解
很多人认为Git「存储快照」意味着浪费空间。实际上:
- 松散对象阶段:每次提交创建新blob,但未改变的文件复用现有blob。
- 打包阶段:Packfile使用delta压缩,最终存储空间与delta-based系统相当。
Julia Evans在一篇博文中做了一个有趣的调查:开发者如何看待Git提交?是快照?差异?还是历史列表?答案反映了这个模型的微妙之处——概念上是快照,但实现上使用了delta压缩。
三路合并:DAG的威力
Git的合并能力源于它的DAG历史模型。
什么是三路合并?
当合并两个分支时,Git需要找到它们的「共同祖先」(merge base),然后执行三路合并:
- Base:共同祖先版本
- Ours:当前分支版本
- Theirs:要合并的分支版本
对于每个文件区域,Git应用以下规则:
- Base和Ours相同,Theirs不同 → 采用Theirs
- Base和Theirs相同,Ours不同 → 采用Ours
- Base、Ours、Theirs都不同 → 冲突
- 三者都相同 → 无变化
Recursive策略
当存在多个共同祖先时(criss-cross merge场景),Git的recursive策略会先合并这些祖先,创建一个虚拟的共同祖先,然后再进行三路合并。
这种策略比简单的「选一个祖先」更健壮,能正确处理复杂的历史拓扑。
为什么SVN做不到?
Subversion使用线性历史模型——每个文件有一个版本序列,更高的版本号覆盖更低的。虽然可以通过目录结构模拟分支,但系统无法真正理解「分支」概念。
当你在SVN中合并分支时,系统不知道哪些变更已经被合并过。你必须手动记录,或依赖容易出错的合并跟踪属性。
Git的DAG模型天然解决了这个问题:每个合并提交记录了它的所有父提交。要判断某个提交是否在当前分支中,只需要图遍历——从分支尖端回溯到所有祖先。
分布式架构:没有中央权威
Git的分布式设计可能是它最具革命性的特点。
每个仓库都是完整的
克隆一个Git仓库,你得到的是完整的历史——所有提交、所有分支、所有标签。你可以完全离线工作:提交、分支、合并、查看历史。
这不仅仅是「离线工作」的便利,它改变了协作模型:
没有单点故障:任何仓库都可以作为「真理来源」。
灵活的工作流:你可以先提交到本地,等准备好再推送到共享仓库;可以在多个远程仓库之间同步;可以创建只用于实验的本地分支。
更好的性能:大多数操作完全本地化——查看历史、比较版本、搜索代码都不需要网络请求。
传输协议
Git支持两种传输协议:
Dumb Protocol:简单的HTTP文件访问。客户端通过一系列GET请求获取对象文件。效率低但兼容性好。
Smart Protocol:客户端和服务器协商传输内容。客户端发送「我有这些对象」,服务器返回「你需要这些对象」,然后发送一个定制的packfile。
Smart Protocol的核心是pack negotiation——双方交换对象列表,服务器生成包含最小必要数据的packfile。这避免了传输客户端已有的对象。
浅克隆和部分克隆
对于大型仓库,Git提供了几种减少克隆大小的方法:
浅克隆(--depth):只获取最近的N次提交。历史被截断,某些操作受限。
部分克隆(--filter):不立即获取所有对象。可以按blob大小过滤,或使用tree-less克隆只获取提交和tree。
稀疏检出:只检出特定目录到工作区。
这些技术使得处理超大型仓库(如Windows代码库,据报道超过300GB)成为可能。
SHA-256迁移:一个痛苦但必要的决定
2017年2月,Google和CWI研究所宣布成功实施SHA-1碰撞攻击(SHAttered)。他们生成了两个内容不同但SHA-1哈希相同的PDF文件。
这对Git意味着什么?
SHA-1在Git中的角色
Git使用SHA-1作为对象标识符。如果两个不同的内容产生相同的哈希,攻击者可能创建恶意提交,其哈希与合法提交相同。
但是,这种攻击的实际风险很低:
- 攻击成本:SHAttered需要约6500年的CPU时间和110年的GPU时间。
- Git的结构限制:碰撞文件必须是有效的Git对象格式。
- 开发者的审查:恶意代码仍然会被人工审查发现。
迁移到SHA-256
尽管风险有限,Git社区决定迁移到SHA-256。这是一项巨大的工程:
兼容性挑战:SHA-1和SHA-256对象ID不兼容,需要同时支持两种格式。
协议更新:传输协议需要识别对象的哈希类型。
工具生态:所有依赖Git的工具都需要更新。
Git 2.29(2020年10月)引入了实验性的SHA-256支持。迁移计划允许每个仓库独立迁移,无需全局协调。
Linus对此评论道:「这造成了很多无意义的混乱……我认为大多数人不需要它,但人们担心,所以就做了。」尽管如此,他承认这是一个合理的安全预防措施。
为什么Git如此成功?
回顾Git二十年的发展,几个关键因素解释了它的成功:
设计的简洁性
Git的底层概念很少:四种对象类型、引用、索引。高级命令(porcelain)是这些底层概念(plumbing)的组合。这种「正交设计」使得系统既简单又强大——新的工作流可以从现有原语组合出来。
分布式优先
Git从一开始就设计为分布式。这使得它天然适合开源协作——任何人都可以克隆仓库、创建分支、发送补丁。GitHub的成功证明了这种模型的价值。
性能
Linus对性能的执着深刻影响了Git的设计。对象数据库用哈希索引、Packfile用delta压缩、操作本地化——所有这些决策都服务于「快速」这个目标。
社区
Junio Hamano从2005年8月开始维护Git,已经坚持了20年。Linus评价道:「他在项目中几乎每一部分都有惊人的了解。」稳定的核心维护为社区发展提供了坚实基础。
一个「意外」的成功
在20周年访谈中,Linus提到一个有趣的细节:他的女儿上大学后告诉他,在计算机科学实验室里,他因Git而闻名——而不是Linux。
「这很荒谬,」Linus说,「我只用了四个月的时间维护Git……它从来不是我真正关心的事情。」
Git的成功也许正是因为它的创造者不试图让它成为一切——他只是想解决自己的问题,然后把解决方案交给社区。这种务实的态度渗透在Git的设计中:简单、快速、可靠。
有时候,最好的工具不是那些被设计为「完美」的工具,而是那些诚实地面对问题、清晰地定义边界、然后优雅地解决问题的工具。Git就是这样一种工具——它不完美,但它二十年来一直「够用」,而且持续演进。
参考资料
- Torvalds, L. (2005). Git Initial Commit. https://github.com/git/git/commit/e83c5163316f89bfbde7
- Chacon, S. & Straub, B. (2014). Pro Git, 2nd Edition. Apress.
- The Architecture of Open Source Applications (Volume 2). “Git.” https://aosabook.org/en/v2/git.html
- GitHub Blog. (2022). “Git’s database internals I: packed object store.” https://github.blog/open-source/git/gits-database-internals-i-packed-object-store/
- GitHub Blog. (2025). “Git turns 20: A Q&A with Linus Torvalds.” https://github.blog/open-source/git/git-turns-20-a-qa-with-linus-torvalds/
- Git Documentation. “Git Objects.” https://git-scm.com/book/en/v2/Git-Internals-Git-Objects
- Git Documentation. “Git References.” https://git-scm.com/book/en/v2/Git-Internals-Git-References
- Git Documentation. “Transfer Protocols.” https://git-scm.com/book/en/v2/Git-Internals-Transfer-Protocols
- Git Documentation. “pack-format.” https://git-scm.com/docs/pack-format
- Git Documentation. “hash-function-transition.” https://git-scm.com/docs/hash-function-transition
- Stevens, M. et al. (2017). “The First Collision for Full SHA-1.” CWI Amsterdam & Google.
- Google Security Blog. (2017). “Announcing the first SHA1 collision.” https://security.googleblog.com/2017/02/announcing-first-sha1-collision.html
- LWN.net. (2017). “Moving Git past SHA-1.” https://lwn.net/Articles/715716/
- LWN.net. (2022). “Whatever happened to SHA-256 support in Git?” https://lwn.net/Articles/898522/
- LWN.net. (2005). “The kernel and BitKeeper part ways.” https://lwn.net/Articles/130746/
- Evans, J. (2024). “Do we think of git commits as diffs, snapshots, and/or histories?” https://jvns.ca/blog/2024/01/05/do-we-think-of-git-commits-as-diffs--snapshots--or-histories/
- Wikipedia. “Distributed version control.” https://en.wikipedia.org/wiki/Distributed_version_control
- Atlassian Git Tutorial. “Git Merge Strategies.” https://www.atlassian.com/git/tutorials/using-branches/merge-strategy
- Atlassian Git Tutorial. “Git Hooks.” https://www.atlassian.com/git/tutorials/git-hooks
- Git Documentation. “git-bisect.” https://git-scm.com/docs/git-bisect
- GitButler Blog. (2025). “20 years of Git.” https://blog.gitbutler.com/20-years-of-git