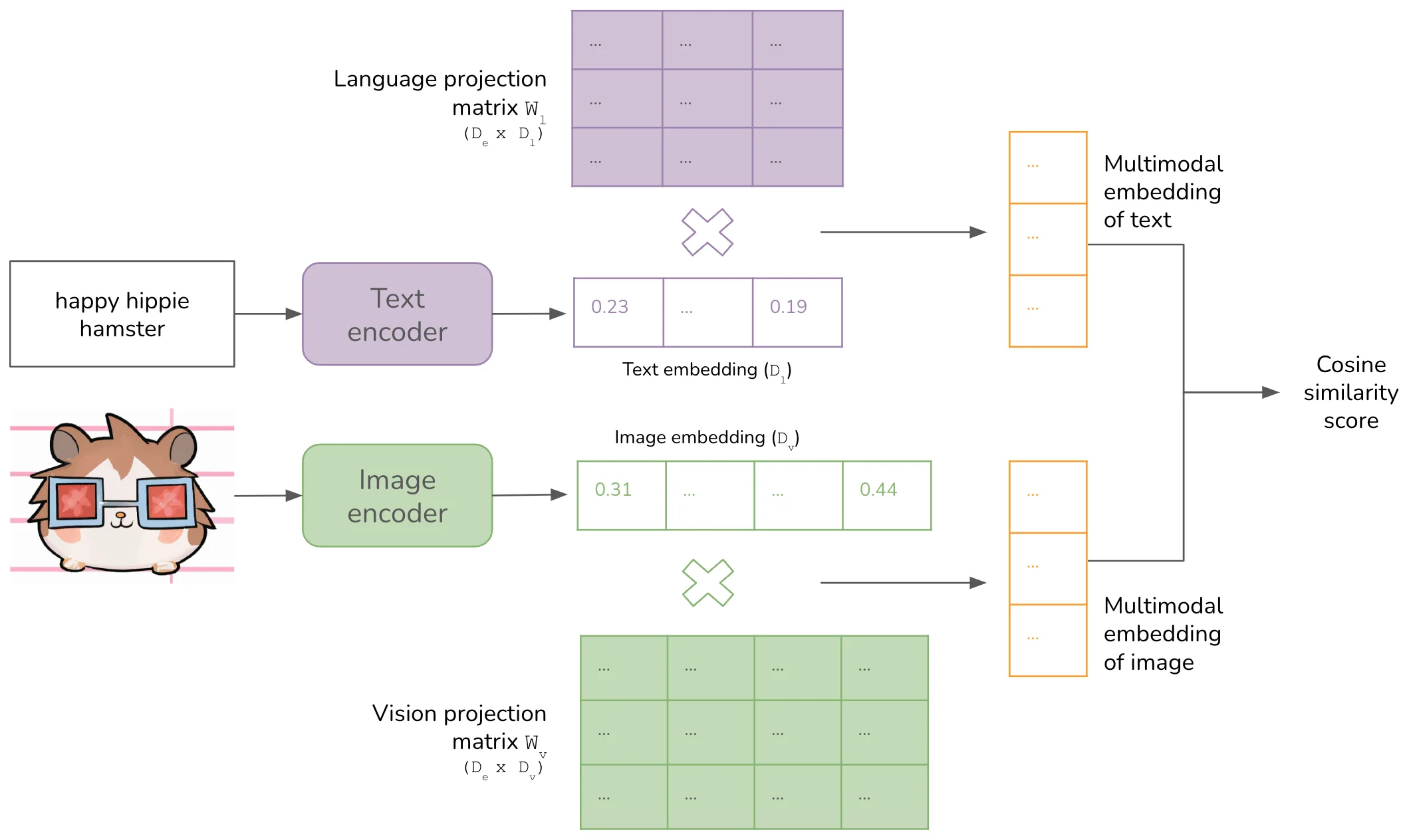
大模型如何"看"图像:从CLIP对比学习到视觉语言模型的跨模态融合之路
2024年5月,OpenAI发布GPT-4o,这个模型能实时"看"你手机屏幕上的内容并回答问题。对着一张复杂的电路图问"这个电阻的阻值是多少",它能准确定位并读出数值;给它一张手绘的流程图,它能理解逻辑关系并生成代码实现。 ...
2024年5月,OpenAI发布GPT-4o,这个模型能实时"看"你手机屏幕上的内容并回答问题。对着一张复杂的电路图问"这个电阻的阻值是多少",它能准确定位并读出数值;给它一张手绘的流程图,它能理解逻辑关系并生成代码实现。 ...
搜索"如何学习编程"和"编程入门方法",传统关键词匹配系统会认为这两个查询毫无关系——它们没有共享任何关键词。但人类一眼就能看出这是同一类问题。这个鸿沟困扰了信息检索领域数十年,直到向量嵌入技术给出了一个优雅的数学答案:把文字映射到连续向量空间,让语义相似的文本在几何空间中靠近。 ...
2015年,何凯明团队在ImageNet竞赛中提交了一个152层的神经网络模型。这个深度是当时主流模型的8倍,但训练误差却更低——这在当时简直是不可思议的事情。因为在那之前,人们普遍认为网络越深,训练越困难。实际上,研究者们观察到一个反直觉的现象:增加层数反而会让模型性能下降。 ...
当你向一个大语言模型发送请求时,可能会注意到一个有趣的现象:第一个字蹦出来总是慢半拍,但随后的字却如流水般涌出。这种"先慢后快"的节奏并非偶然,而是大模型推理机制的根本特性。 ...
当GPT-3在2020年问世时,其1750亿参数的规模震惊了整个AI界。三年后,LLaMA-70B用更少的参数达到了更好的效果。到了2024年,DeepSeek-V3以6710亿总参数但仅激活370亿参数的MoE架构重新定义了效率边界。这些数字背后隐藏着一套精确的数学逻辑——参数量如何决定计算量,计算量如何影响训练成本,以及如何在有限的算力预算下设计最优模型。 ...

每个使用过大语言模型 API 的人都会遇到一个名为 Temperature 的参数。大多数时候,我们要么忽略它,要么随意调一下。但这个看似简单的数字,实际上决定了模型是"一本正经"还是"天马行空"。 ...
2023年6月,微软研究院发布了一篇标题充满争议性的论文:《Textbooks Are All You Need》。论文介绍了phi-1模型——一个仅有13亿参数的语言模型,在HumanEval代码基准测试上达到了50.6%的pass@1准确率,超越了拥有超过100倍参数的模型。秘密在于它的训练数据:70亿token的网页数据和10亿token由GPT-3.5生成的合成教科书数据。 ...