一个拥有10台服务器的集群,负载均衡器配置为最简单的轮询策略。每台服务器每秒处理100个请求,看起来完美均衡。直到某天凌晨,其中一台服务器因为硬件故障开始变慢——响应时间从10毫秒飙升到2秒。轮询算法依然忠实地将十分之一的流量发送给它。
结果?9%的用户请求超时。而剩下91%的请求中,又有相当一部分因为那台慢服务器的连接池耗尽而排队等待。监控大屏上的错误率曲线开始爬升,值班工程师被电话叫醒。这不是虚构的场景——这是几乎所有大规模系统都经历过的真实问题。
轮询(Round Robin)是最古老的负载均衡算法,也是直觉上最"公平"的策略:每人一个,依次轮转。但这个直觉在分布式系统中往往是错的。问题不在于算法本身,而在于我们对"公平"的定义。轮询公平地分配的是请求数量,而不是负载。
轮询的直觉陷阱:请求数量不等于负载
轮询算法的核心假设是:每个请求的代价相同。这在教科书里是成立的,但在生产环境中几乎从未成立。
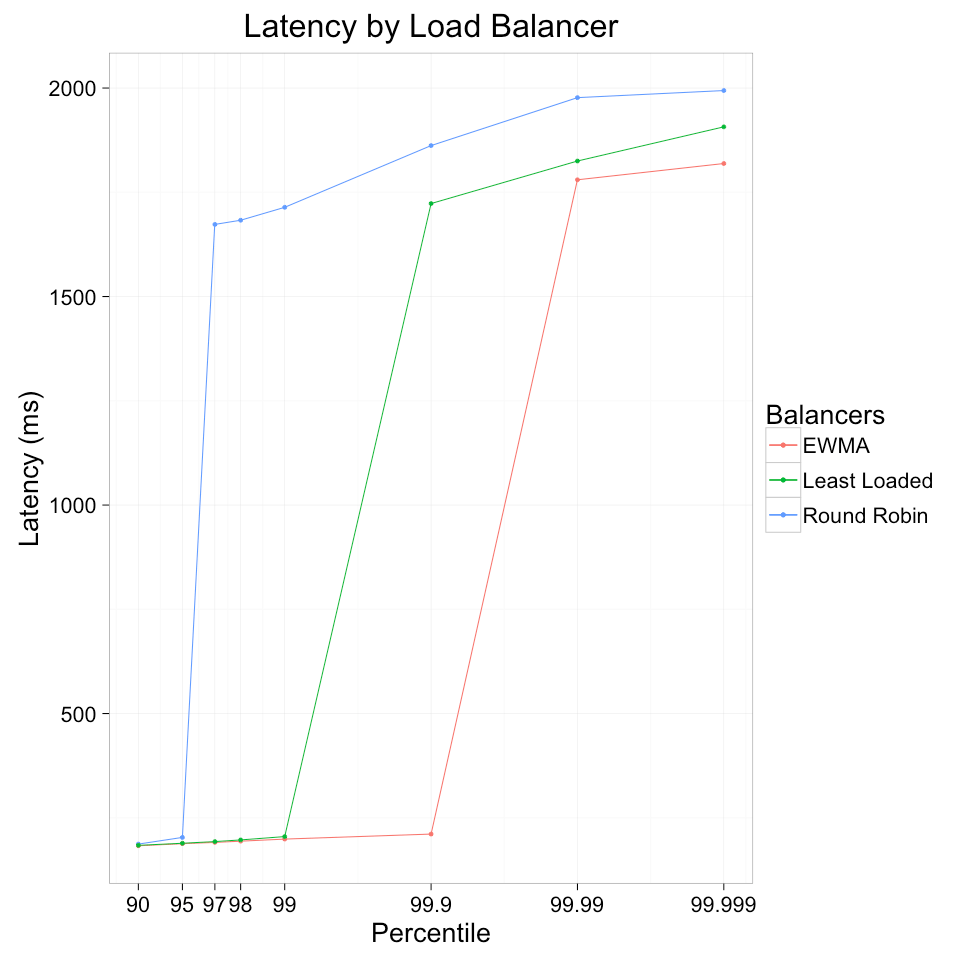
Linkerd团队做过一个经典的实验:11台后端服务器,每台正常运行时延迟中位数为167毫秒。客户端以每秒1000个请求的速率通过负载均衡器访问这些服务器。运行15秒后,其中一台服务器的延迟被人为固定为2秒(模拟GC停顿或硬件故障),持续30秒后恢复正常。
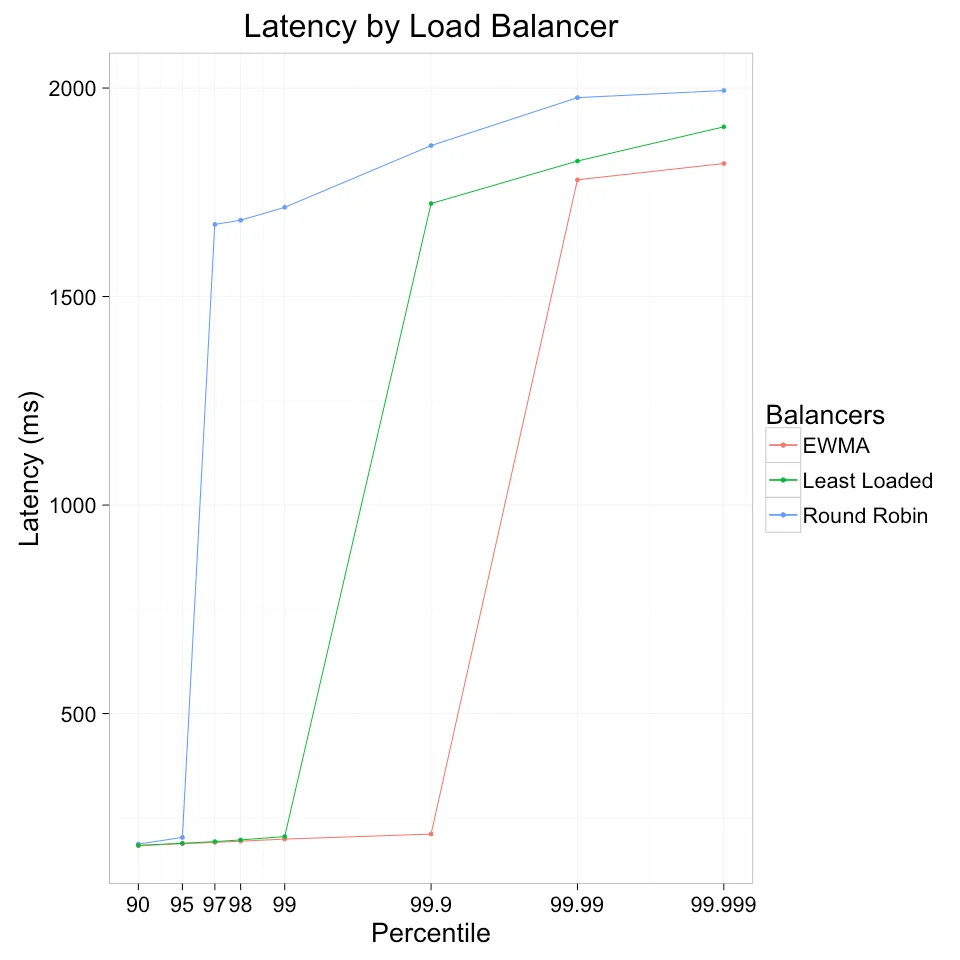
图片来源: linkerd.io
{kind=link}
结果令人震惊。在轮询策略下,当超时阈值设为1秒时,成功率骤降至95%。而使用"最少活跃请求"(Least Loaded)策略时,成功率可达99%。使用"峰值EWMA"策略时,成功率更是达到99.9%。
差异的根源在于信息。轮询算法对服务器状态一无所知,它只知道一个列表和当前索引。当一个服务器变慢时,轮询依然向它发送等量的流量。更糟糕的是,在HTTP/1.1时代,连接复用意味着慢服务器上的连接会积累更多的排队请求,形成正反馈循环。
轮询的另一个隐秘问题是请求突发的处理。假设有3台服务器A、B、C,权重分别为5、1、1。传统加权轮询会连续发送5个请求到A,然后各发送1个到B和C。这意味着A在短时间内承受了5倍的突发压力,而它恰恰是权重最高的服务器——本应有更好的处理能力,却被瞬间的请求堆叠击穿。
加权轮询的改良与局限
Nginx实现了一种"平滑加权轮询"算法来缓解突发问题。算法核心是:每次选择时,将所有服务器的当前权重加上其配置权重,选择当前权重最大的服务器,然后将其当前权重减去所有配置权重之和。
服务器: {A:5, B:1, C:1}
选择过程:
初始: current_weight = {A:0, B:0, C:0}
第1轮: +weight -> {A:5, B:1, C:1}, 选择A, -7 -> {A:-2, B:1, C:1}
第2轮: +weight -> {A:3, B:2, C:2}, 选择A, -7 -> {A:-4, B:2, C:2}
第3轮: +weight -> {A:1, B:3, C:3}, 选择B, -7 -> {A:1, B:-4, C:3}
第4轮: +weight -> {A:6, B:-3, C:4}, 选择A, -7 -> {A:-1, B:-3, C:4}
第5轮: +weight -> {A:4, B:-2, C:5}, 选择C, -7 -> {A:4, B:-2, C:-2}
第6轮: +weight -> {A:9, B:-1, C:-1}, 选择A, -7 -> {A:2, B:-1, C:-1}
第7轮: +weight -> {A:7, B:0, C:0}, 选择A, -7 -> {A:0, B:0, C:0}
最终序列: A, A, B, A, C, A, A
这个算法产生的序列比传统加权轮询更平滑:A, A, B, A, C, A, A。最大连续请求数从5降到了2。
但加权轮询的根本问题依然存在:权重是静态的。配置权重时,我们假设知道每台服务器的相对处理能力。但服务器的性能是动态的——GC停顿、磁盘IO竞争、网络拥塞、甚至是同一物理机上的邻居进程(吵闹的邻居问题),都会导致实际处理能力与配置权重产生偏差。
Uber在2020年的一次内部审计中发现了一个有趣的现象:在一个运行着数百个服务的集群中,虽然每个服务通过负载均衡器接收到的请求数量几乎完全相等(差异小于0.1%),但各容器的CPU利用率却差异巨大。同一服务内,最高利用率的容器和最低利用率的容器之间,CPU差异可达30%以上。
追踪后发现,问题出在硬件异构性。即使是同一代实例类型,不同物理机的性能也可能有显著差异。更不用说跨代硬件混用的场景——Uber测量到的最大性能差异达到2倍。在这种情况下,“等量的请求"意味着"不等量的负载”。
最小连接数的困境:羊群效应的阴影
“最少活跃请求”(Least Connection)算法试图解决这个问题。它的思路很简单:跟踪每个服务器的活跃连接数,新请求发送到当前连接数最少的服务器。
这个算法在单个负载均衡器的场景下表现优异。当一台服务器变慢时,它上面的连接会持续更长时间,导致活跃连接数增加。新请求会被导向其他更快的服务器。这是一个自适应的过程,不需要任何静态配置。
但分布式系统从来不会那么简单。
当有多个独立的负载均衡器实例时,每个实例只能看到自己发送的请求。这就产生了一个有趣的问题:假设有负载均衡器L1、L2、L3,服务器S1、S2、S3。S2突然变慢。L1看到自己对S2的活跃请求增加,于是减少对S2的发送。但L2和L3也看到了同样的情况——它们也减少对S2的发送。
结果是S2瞬间从三个方向同时被抛弃,而S1和S3则同时被三个方向"选中"。这被称为"羊群效应"(Herd Behavior):多个独立决策者基于不完整信息做出相同的选择,导致负载在服务器间剧烈波动。
Netflix在重构其边缘负载均衡器时详细描述了这个问题。他们发现,在使用"最少活跃请求"算法时,请求在服务器间的分布变得异常宽阔——某些服务器接收到的请求数是其他服务器的数倍,而这种不平衡会周期性地在不同服务器间转移。
一致性哈希:另一种不公平
一致性哈希(Consistent Hashing)是另一种常用的负载均衡策略,主要用于需要会话粘性(Session Affinity)的场景。它将服务器和请求键值映射到同一个哈希环上,请求由环上顺时针方向最近的节点处理。
1997年,MIT的David Karger等人在论文《Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web》中提出了这一算法。核心目标是:当服务器数量变化时,最小化数据的迁移量。
但一致性哈希有一个著名的缺陷:数据倾斜。如果哈希函数不够均匀,或者服务器数量较少,某些服务器可能会负责环上大得多的区间。
解决方案是虚拟节点。每个物理服务器映射到多个虚拟节点,均匀分散在哈希环上。虚拟节点越多,分布越均匀。Karger等人在论文中证明,当虚拟节点数为O(log n)时,可以达到理想的负载均衡。
但这带来了另一个问题:热点Key。如果某个Key的访问量异常高,无论虚拟节点如何分布,它都会被路由到同一个服务器。在Redis Cluster等分布式存储系统中,这是常见的性能瓶颈来源。一致性哈希解决的是"服务器变化时的数据迁移"问题,而不是"请求分布不均"的问题。
P2C:两个选择的数学奇迹
1999年,Yossi Azar、Andrei Broder、Anna Karlin和Eli Upfal在一篇论文中提出了一个看似简单的想法:如果每个球(请求)可以随机选择两个桶(服务器),然后放入当前负载较低的那个,会发生什么?
结果出人意料:最大负载从O(log n)下降到O(log log n)。
这是一个指数级的改进。用更直观的语言说:如果有100万台服务器,纯随机选择会导致某些服务器的负载是平均值的14倍。而使用P2C,这个数字下降到大约3倍。
Michael Mitzenmacher在1996年的博士论文《The Power of Two Choices in Randomized Load Balancing》中系统地分析了这一现象。关键洞察是:不需要找到"最好"的服务器,只需要避免"最差"的服务器。
graph LR
subgraph 随机选择
R1[请求] -->|随机| S1[服务器1<br/>负载: 100]
R1 -->|随机| S2[服务器2<br/>负载: 50]
R1 -->|随机| S3[服务器3<br/>负载: 10]
end
subgraph P2C选择
R2[请求] -->|随机选2个| C1{比较负载}
C1 -->|S2: 50| S4[服务器2]
C1 -->|S3: 10| S5[服务器3]
C1 -->|选择较低| S6[最终选择: S3]
end
P2C算法的优雅之处在于它天然避免了羊群效应。每个负载均衡器随机选择两个服务器进行比较,而不是扫描所有服务器找"最优"。这种随机性引入了足够的噪声,使得不同负载均衡器不太可能做出完全相同的选择。
NGINX在1.15.1版本中引入了P2C算法的实现。配置非常简单:
upstream backend {
zone backend 64k;
server 192.168.1.11;
server 192.168.1.12;
server 192.168.1.13;
random two least_time=last_byte;
}
Envoy的"Least Request"负载均衡器也是基于P2C实现的。默认情况下,它会随机选择两个主机,然后选择活跃请求数较少的那个。Envoy的测试表明,即使只有两个选择,也能显著改善负载分布,而且增加更多选择的收益递减。
Netflix的工程实践:组合拳
Netflix在2018年分享了他们重构边缘负载均衡的经验。核心思路是将多个机制组合使用:
Choice-of-2算法:替代轮询,避免羊群效应。
服务端上报利用率:每个后端服务器在响应头中添加当前的利用率信息:
X-Netflix.server.utilization: 75
负载均衡器被动收集这个信息,而不是主动轮询。这避免了额外的健康检查开销,而且利用率信息天然聚合了所有负载均衡器的请求。
多因素评分:选择服务器时,综合考虑三个因素:
- 客户端健康度:该服务器的连接错误率
- 服务端利用率:服务器自报的负载
- 客户端利用率:本负载均衡器到该服务器的活跃请求数
新服务器保护:对于刚启动的服务器,先进入"考察期"(Probation),只允许一个并发请求。同时根据服务器"年龄"逐步增加流量,避免冷启动过载。
Netflix报告称,新负载均衡器实现了"数量级的错误率下降",平均延迟和尾延迟都有显著改善。
Uber的异构硬件处理
Uber面临的是一个更底层的问题:同一个集群内的服务器硬件性能不一致。他们测量发现,即使是"相同"的实例类型,性能差异也可能达到2倍。
解决方案分为两层:
跨集群层面:动态主机感知负载均衡。服务发现系统记录每个主机的性能权重(基于NCU——Normalized Compute Unit),然后根据服务实际部署的主机动态计算每个集群的权重。
集群内部:辅助负载均衡(Assisted Load Balancing)。每个后端服务器在响应中附加当前的并发请求数。负载均衡器使用这个信息进行P2C选择。
关键设计决策是使用"并发请求数"而不是"CPU利用率"作为负载指标。原因很简单:并发请求数是一个明确的整数,而CPU利用率的解读存在争议——是用getrusage还是cgroups?cgroups的布局变化怎么办?每个容器独立读取cgroups的开销如何?
Uber的测试表明,这个简单的方案在实践中表现出乎意料地好。即使某些中间件实现有bug,也没有导致生产事故——P2C的随机性提供了足够的容错空间。
回到原点:什么才是"公平"
负载均衡算法的演进,实际上是对"公平"定义的不断修正。
轮询公平地分配请求数量,但忽视了请求代价的差异。加权轮询试图用静态权重补偿差异,但无法适应动态变化。最少活跃请求算法跟踪实时负载,但在分布式环境下产生羊群效应。一致性哈希解决了数据迁移问题,但引入了新的热点风险。
P2C算法的成功在于一个看似简单的改变:不再追求"最优选择",而是满足于"避免最差选择"。这个哲学的转变——从全局最优到局部满意——恰恰是分布式系统的核心智慧。
在实践中,没有完美的算法。NGINX和Envoy都提供了多种选择,让用户根据场景选择:
| 场景 | 推荐算法 | 原因 |
|---|---|---|
| 同构集群、请求代价均匀 | 轮询 | 简单高效,无状态 |
| 异构集群、静态权重可靠 | 加权轮询 | 考虑性能差异 |
| 多负载均衡器实例 | P2C | 避免羊群效应 |
| 需要会话粘性 | 一致性哈希 | 同一Key路由到同一服务器 |
| 服务器性能波动大 | 最少活跃请求+服务端反馈 | 自适应动态调整 |
选择负载均衡算法时,最重要的不是算法的复杂度,而是对系统特性的理解。知道服务器是否异构、请求代价是否均匀、是否存在多负载均衡器实例——这些信息比算法本身更能决定正确的选择。
负载均衡不是一个数学问题,而是一个工程问题。它的答案不在于找到最优解,而在于理解约束、权衡代价、并做出适合特定场景的选择。正如Netflix工程师所说:避免追逐完美的微小细节,专注于解决实际存在的问题。
参考资料
-
Karger, D., Lehman, E., Leighton, T., Levine, M., Lewin, D., & Panigrahy, R. (1997). Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web. ACM Symposium on Theory of Computing.
-
Mitzenmacher, M. (1996). The Power of Two Choices in Randomized Load Balancing. PhD Thesis, University of California, Berkeley.
-
Azar, Y., Broder, A. Z., Karlin, A. R., & Upfal, E. (1999). Balanced Allocations. SIAM Journal on Computing.
-
F5 Networks. (2018). NGINX and the “Power of Two Choices” Load-Balancing Algorithm. F5 Blog.
-
Allen, T. (2020). Examining Load Balancing Algorithms with Envoy. Envoy Proxy Blog.
-
Smith, M. (2018). Rethinking Netflix’s Edge Load Balancing. Netflix Technology Blog.
-
Uber Engineering. (2024). Load Balancing: Handling Heterogeneous Hardware. Uber Blog.
-
Buoyant. (2016). Beyond Round Robin: Load Balancing for Latency. Linkerd Blog.