1978年7月,Leslie Lamport在《Communications of the ACM》上发表了一篇论文,标题是《Time, Clocks, and the Ordering of Events in a Distributed System》。论文开篇就抛出了一个反直觉的论断:分布式系统中,事件的"先后顺序"本质上是一个相对概念。
这篇论文后来成为分布式系统领域引用率最高的文献之一,Lamport也因此获得了2013年的图灵奖。但四十五年过去了,时间问题依然是分布式系统设计中最棘手的挑战之一。从数据库事务到分布式锁,从消息队列到共识协议,几乎每一个分布式原语都在与时间问题纠缠。
理解分布式系统的时间问题,是理解现代分布式架构的钥匙。
一个不可能完成的任务
假设你正在设计一个全球部署的银行系统。用户A在东京向用户B转账100元,用户B在纽约几乎同时查询余额。系统需要回答一个看似简单的问题:B看到的余额是否包含A的转账?
在单机系统中,这个问题根本不存在——所有事件都由同一个处理器顺序执行,操作系统维护着唯一的时间线。但在分布式系统中,这个问题变成了一个哲学困境。
物理时钟不可靠
每台机器都有自己的硬件时钟,基于石英晶体的振荡频率。这些晶体在生产时就有微小的精度差异,温度变化还会进一步影响振荡频率。结果是:即使两台机器同时启动,它们的时钟也会逐渐"漂移"——一天漂移几秒钟完全正常。
网络时间协议(NTP)试图解决这个问题。它通过分层的时间服务器架构,将机器时钟同步到协调世界时(UTC)。但NTP的精度受限于网络延迟:在局域网内可能达到毫秒级,跨洲际网络则可能漂移到数百毫秒。
更糟糕的是,NTP调整时钟的方式会引入新的问题。如果检测到时钟偏差较大,NTP可能选择"跳变"——直接将时钟向前或向后拨动。这会导致一个诡异的现象:某个时间点的日志可能突然出现在"过去",而某些代码检查时间是否单调递增时会直接崩溃。
2012年6月30日,一个闰秒的加入让Linux内核的高精度定时器(hrtimer)陷入混乱。Reddit、Gawker、Mozilla等网站的Java进程在CPU上疯狂空转,服务中断了数十分钟。Linus Torvalds后来评论道:“每次遇到闰秒,我们总能发现点什么。”
因果关系才是核心
Lamport的关键洞察是:分布式系统真正需要的不是物理时间的精确同步,而是因果关系的正确建立。
如果事件A导致了事件B的发生(比如A是发送消息,B是接收这条消息),那么在任何观察者眼中,A都必须发生在B之前。但如果两个事件之间没有任何因果联系——比如两个用户同时在不同节点上执行独立的操作——那么谁先谁后实际上并不重要。
这个洞察引出了"发生先于"(happened-before)关系的形式化定义,通常用箭头符号→表示:
- 如果事件a和事件b发生在同一个进程内,且a在b之前执行,则
a → b - 如果事件a是发送消息,事件b是接收这条消息,则
a → b - 如果
a → b且b → c,则a → c(传递性)
如果既没有a → b也没有b → a,则称a和b是并发的——它们之间没有因果联系,顺序可以任意。
Lamport时钟:用一个计数器捕获偏序
Lamport提出了一种极其优雅的机制来实现这个理论:逻辑时钟。
每个进程维护一个本地计数器C,遵循三条简单规则:
- 每次发生本地事件前,计数器加1
- 发送消息时,将当前计数器值随消息一起发送
- 接收消息时,将本地计数器更新为
max(本地计数器, 消息携带的计数器) + 1
这个机制保证了一个关键性质:如果a → b,则C(a) < C(b)。
进程P1: C=1 → C=2(发送m1) → C=3 → C=4
↓
进程P2: C=1 → C=2 → C=3(接收m1, C=max(2,2)+1=3) → C=4
但注意反向命题不成立:C(a) < C(b)并不意味着a → b。两个并发事件可能恰好有不同的时钟值。这就是逻辑时钟的局限性:它只能建立偏序(partial order),而非全序。
从偏序到全序
Lamport论文的另一个贡献是展示了如何将偏序扩展为全序。方法是附加进程标识符:将事件表示为(C, P)对,其中C是逻辑时钟值,P是进程ID。比较规则是先比较C,若相等则比较P。
这确保了任意两个事件都能比较先后,但这种全序是人为的——并发事件的顺序依赖于进程ID的分配,本质上是一种"打破平局"的策略。
向量时钟:捕获完整的因果历史
Lamport时钟的局限性在1988年被Mattern和Fidge独立解决。他们提出的向量时钟(Vector Clock)能够精确识别并发关系。
向量时钟将每个进程的计数器扩展为一个向量,向量的长度等于进程总数。进程i维护的向量记为VC[i],规则如下:
- 本地事件:
VC[i]++ - 发送消息:将整个向量随消息发送
- 接收消息:对向量的每个分量j,
VC[j] = max(VC[j], 消息向量[j]),然后VC[i]++
比较规则变得更加精细:
VC(a) < VC(b)当且仅当所有分量VC(a)[j] ≤ VC(b)[j]且至少有一个分量严格小于VC(a) = VC(b)当且仅当所有分量相等- 如果既不小于也不等于,则a和b并发
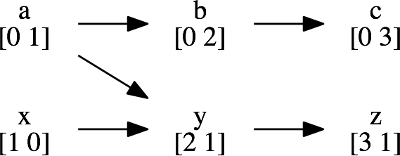
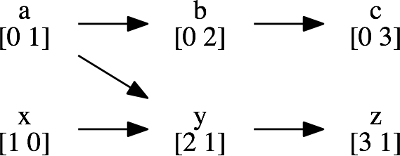
图片来源: www.evanjones.ca
{kind=link}
上图展示了两个线程的事件顺序。蓝色箭头表示消息传递建立的因果依赖,绿色箭头表示同一进程内的顺序。向量时钟能够精确捕获这种因果关系。
向量时钟的代价是空间开销——每个事件需要存储O(n)个整数,n是进程数。在大规模系统中,这成为显著的负担。各种优化方案应运而生,如编码向量时钟(Encoded Vector Clock)试图压缩存储开销。
物理时钟的回归:TrueTime
逻辑时钟解决了因果关系问题,但它有一个根本限制:无法与真实世界的时间对应。数据库管理员想查询"下午3点到4点之间的事务",逻辑时钟对此无能为力。
2012年,Google公开了Spanner数据库的设计,引入了TrueTime API,开创了一条新路径。
时间作为区间
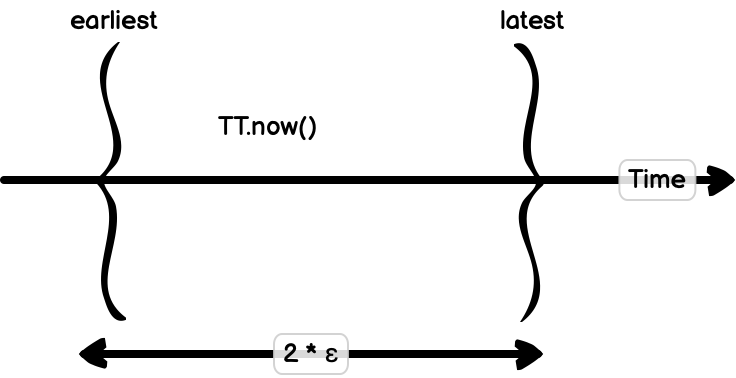
TrueTime的核心创新是承认并量化时钟不确定性。它不返回一个时间戳,而是返回一个区间[earliest, latest],保证真实时间必然落在这个区间内。
| 方法 | 返回值 |
|---|---|
TT.now() |
TTinterval: [earliest, latest] |
TT.after(t) |
时间t是否"确定已过去" |
TT.before(t) |
时间t是否"确定未到达" |
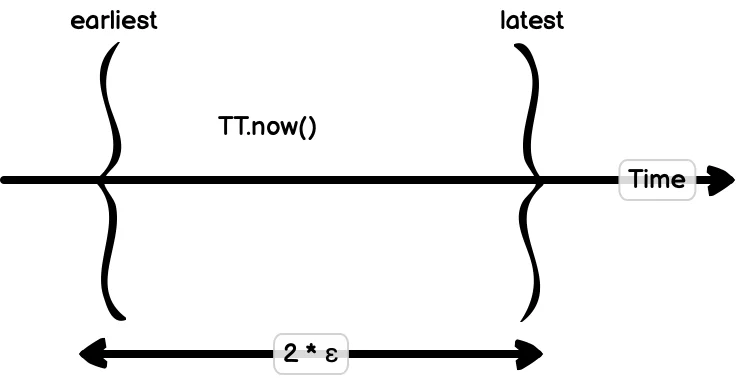
图片来源: sookocheff.com
{kind=link}
区间的宽度反映了时钟不确定性。在Google的数据中心中,这个不确定性通常在1-7毫秒之间。
GPS与原子钟的冗余架构
TrueTime的高精度来自于硬件投入。每个数据中心部署两类时间服务器:
GPS主时钟:配备GPS接收器,从卫星信号中提取精确时间。GPS信号本身携带原子钟级别的时间信息。
末日主时钟(Armageddon Master):配备本地原子钟,作为GPS的备份。当GPS信号受干扰(如太阳风暴、恶意干扰)时接管时间服务。
所有主时钟互相校验,发现异常的节点会自动下线。每台机器运行的timeslave守护进程从多个主时钟(包括远程数据中心)采样,使用Marzullo算法剔除异常值,将本地时钟同步到多数派。
等待不确定性
TrueTime如何实现外部一致性?答案是等待。
考虑一个事务提交场景:协调者选择一个时间戳s,必须确保所有其他节点在看到这个事务之前,其时钟都已经超过了s。由于时钟不确定性最多是ε,协调者只需等待2ε时间——这恰好是不确定性区间的宽度。
实际实现中,这个等待通常与Paxos通信重叠,减少了实际延迟。Spanner的基准测试显示,这个等待通常在4-10毫秒之间,对大多数应用是可接受的。
混合逻辑时钟:开源世界的答案
Google有GPS和原子钟,普通云用户怎么办?
混合逻辑时钟(Hybrid Logical Clock, HLC)提供了一个优雅的折中方案。它结合了物理时钟的可读性和逻辑时钟的单调性,被CockroachDB、MongoDB等系统广泛采用。
HLC的时间戳结构是(物理时间, 逻辑计数器):
class HybridTimestamp:
wallClockTime: long // 物理时间(毫秒)
ticks: int // 逻辑计数器
规则如下:
- 本地事件:如果物理时钟大于当前HLC的物理部分,更新物理部分并重置计数器;否则只增加计数器
- 接收消息:取物理时钟、本地HLC物理部分、消息HLC物理部分三者的最大值;如果最大值等于本地或消息的物理部分,计数器取两边的最大值加1
这确保了:
- HLC的时间戳始终接近物理时钟(误差通常在毫秒级)
- HLC是单调递增的,不受时钟跳变影响
- 因果相关的事件有正确的时间戳顺序
CockroachDB使用NTP同步时钟(在AWS上使用Amazon Time Sync Service),时钟误差通常在250毫秒以内。为了实现线性一致性,CockroachDB在事务提交时需要等待这个不确定性窗口——虽然比Spanner的等待时间长,但无需专用硬件。
实际案例:当时间出错时
闰秒灾难
2012年6月30日23:59:60 UTC,一个闰秒被插入。Linux内核的hrtimer子系统因为时间"倒退"而进入异常状态,触发了大量CPU空转。
受影响的不只是Reddit。澳大利亚航空公司的预订系统Amadeus瘫痪,导致400多个航班延误。Gawker、Mozilla、LinkedIn等服务相继出现问题。
Google的应对方案是"闰秒涂抹"(leap smear):在24小时内逐渐调整时钟,而不是一次性跳变。这个做法后来被其他云服务商采纳,包括AWS和Microsoft Azure。
时钟漂移与日志谎言
在分布式追踪场景中,时钟偏差会导致"负延迟"——响应时间戳竟然早于请求时间戳。这不仅是显示问题,更会破坏性能分析和告警逻辑。
一个真实的案例:某公司的监控告警迟迟没有触发,事后分析发现,问题节点的时钟落后了2.3秒。关键事件在日志中"出现"得太晚,被排除在告警窗口之外。
解决方案包括:
- 使用Chrony替代传统ntpd,提供更快的收敛和更好的漂移修正
- 监控时钟偏差本身作为一项指标
- 在关键系统中使用PTP(Precision Time Protocol)替代NTP,精度可达亚微秒级
时间问题的本质权衡
回顾四十五年的技术演进,分布式系统的时间问题实际上是一系列权衡:
精度 vs 成本
TrueTime用GPS和原子钟实现了毫秒级的时钟确定性,但代价是专用硬件和基础设施投入。对于大多数系统,NTP + HLC的方案足够实用。
一致性 vs 可用性
CAP定理告诉我们,在网络分区时必须在一致性和可用性之间选择。时间问题同理:严格的时间排序需要等待和协调,这会牺牲延迟和可用性。
简单 vs 正确
Lamport时钟只有三条规则,向量时钟稍复杂但能识别并发,TrueTime需要整个基础设施支撑。选择哪种方案,取决于系统对正确性的要求。
结语:时间是分布式系统的幽灵
Leslie Lamport在2018年的一次演讲中说道:“分布式系统之所以难,是因为我们习惯了顺序计算的世界。在顺序世界里,时间是一条线;在分布式世界里,时间是网。”
这张网上的每个节点都有自己的时间线,它们通过消息传递编织在一起。逻辑时钟教我们如何在这张网上追踪因果关系,TrueTime教我们如何用工程手段收紧这张网的缝隙。
无论选择哪种方案,理解时间问题的本质是关键:在分布式系统中,时间不是背景,而是需要主动管理的核心资源。
参考文献
- Lamport, L. (1978). “Time, Clocks, and the Ordering of Events in a Distributed System”. Communications of the ACM, 21(7), 558-565.
- Corbett, J. C., et al. (2012). “Spanner: Google’s Globally-Distributed Database”. OSDI 2012.
- Mattern, F. (1989). “Virtual Time and Global States of Distributed Systems”. Parallel and Distributed Algorithms.
- Kulkarni, S., et al. (2014). “Logical Physical Clocks and Consistent Snapshots in Globally Distributed Databases”. PODC 2014.
- “Network Time Protocol”. RFC 5905, IETF.
- “Precision Time Protocol”. IEEE 1588-2008.
- AWS Documentation. “Amazon Time Sync Service”. docs.aws.amazon.com.
- Fowler, M. (2023). “Patterns of Distributed Systems: Clock-Bound Wait”. martinfowler.com.
- “The Inside Story of the Extra Second That Crashed the Web”. Wired, July 2012.
- CockroachDB Documentation. “Hybrid Logical Clock Timestamps”. cockroachlabs.com.