2011年,LMAX交易平台的工程师们遇到一个奇怪的问题:他们的高性能消息队列在生产环境中表现不佳,但代码逻辑完全正确,线程安全措施也到位。经过深入排查,问题竟出在两个相邻的变量上——它们恰好落在同一个缓存行中。
这个被称为"伪共享"(False Sharing)的问题,让代码性能下降了整整一个数量级。更可怕的是,它没有任何代码层面的问题表现:没有死锁,没有竞态条件,没有内存泄漏。程序只是变慢了,而且随着核心数增加,慢得越来越离谱。
缓存行:问题的物理基础
要理解伪共享,必须先理解现代CPU缓存的工作方式。
CPU缓存以"缓存行"(Cache Line)为单位管理数据,而非单个字节。这是基于空间局部性原理:程序访问某个内存地址时,很可能很快会访问附近的地址。因此,当CPU读取一个字节时,它会顺带把相邻的数据一起加载到缓存中。
不同架构的缓存行大小不同:
| 处理器架构 | 缓存行大小 |
|---|---|
| Intel/AMD x86-64 | 64字节 |
| Apple M1/M2 (ARM) | 128字节 |
| 大多数ARM Cortex | 64字节 |
| 部分MIPS | 32字节 |
x86架构的64字节缓存行意味着:即使你只修改一个8字节的long变量,CPU也会以64字节为单位进行缓存操作。这本来是性能优化,却在多核场景下变成了隐形杀手。
MESI协议:一致性的代价
多核处理器中,每个核心都有自己的L1和L2缓存。当多个核心缓存同一内存地址的数据时,如何保证数据一致性?
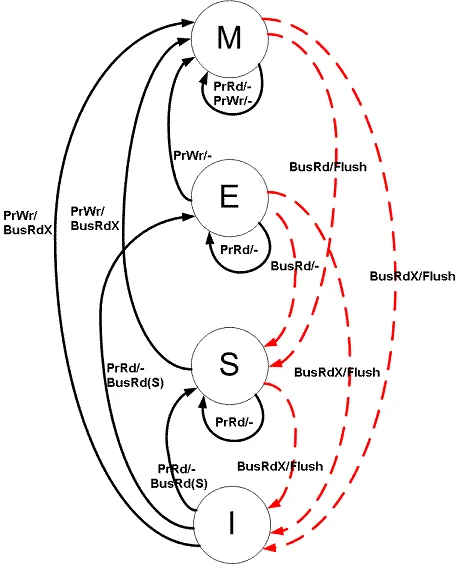
MESI协议是最广泛使用的缓存一致性协议,它为每个缓存行定义四种状态:
- Modified (M):该缓存行已被修改,与主存不一致,只存在于当前缓存
- Exclusive (E):该缓存行只存在于当前缓存,且与主存一致
- Shared (S):该缓存行可能存在于多个缓存中,与主存一致
- Invalid (I):该缓存行无效
当核心A修改某个缓存行中的数据时,必须先通过总线广播"请求所有权"(RFO, Request For Ownership),让其他核心将该缓存行标记为Invalid。其他核心下次访问这个地址时,必须从主存或拥有最新数据的核心重新加载。
图片来源: upload.wikimedia.org
{kind=link}
这个机制保证了数据一致性,但也带来了性能开销:每次缓存行状态变更都涉及总线通信,可能需要数百个时钟周期。
伪共享:没有共享的"共享"
真正的共享是多个线程访问同一变量,这是显式的、容易识别的。伪共享则不同:多个线程访问的是不同的变量,但这些变量恰好位于同一缓存行中。
考虑这个简单的例子:
public class Counter {
volatile long count1; // 线程1独占写入
volatile long count2; // 线程2独占写入
}
两个线程各自更新自己的计数器,逻辑上完全独立。但由于count1和count2相邻,它们可能落在同一个64字节的缓存行中。当线程1写入count1时:
- CPU核心1将包含
count1和count2的缓存行标记为Modified - 总线广播使核心2的该缓存行失效
- 线程2下次读取或写入
count2时,必须重新加载整个缓存行 - 线程2的写入又使核心1的缓存行失效……
这就是"乒乓效应"(Ping-Pong):两个核心为了一块实际上不需要共享的数据,反复进行缓存一致性通信。每次通信可能耗时100-300个时钟周期,相当于执行数百条指令的时间。
Martin Thompson(LMAX Disruptor作者)的基准测试清晰地展示了这个问题:在4核Nehalem处理器上,未加缓存行填充的计数器随着线程数增加,执行时间呈指数增长;而加入填充后,实现了近乎线性的扩展。
性能影响:从慢到"崩溃"
伪共享的性能影响是灾难性的。圣何塞州立大学的研究显示:在4核系统上,伪共享可导致20倍性能下降;在8核系统上,这个数字达到100倍。
维基百科上的示例代码展示了这个问题:
线程数 每次操作耗时(纳秒)
1 1
2 4
4 9
8 17
16 41
32 94
随着线程数从1增加到32,单次操作耗时从1纳秒飙升到94纳秒——接近100倍的性能损失。更可怕的是,这不是代码bug,不是算法问题,而是纯粹的内存布局问题。
另一个极端案例来自ClickHouse团队:在Intel高核心数处理器上,某些查询在核心数从80增加到112时性能反而下降。排查后发现是伪共享问题:一个结构体中的两个字段被不同核心频繁访问,导致大量缓存一致性流量。
检测:沉默的性能杀手
伪共享之所以危险,在于它"沉默"。不会抛出异常,不会导致错误结果,只会让性能悄悄下降。更糟糕的是,传统性能分析工具往往无法直接定位问题。
硬件性能计数器
Intel VTune Profiler和Linux perf工具可以通过监控特定硬件事件来间接检测伪共享:
perf stat -e cycles,instructions,L1-dcache-load-misses ./program
关键指标:
- L1-dcache-load-misses:L1数据缓存未命中次数。伪共享会导致这个数字异常高。
- CPI (Cycles Per Instruction):每指令周期数。伪共享会导致CPU频繁等待内存,CPI升高。
Herb Sutter在2009年的经典文章中指出:CPU活动监视器帮助有限,但CPI和缓存未命中率结合源代码定位是有效的方法。
Intel VTune的Memory Access分析
VTune提供了专门的Memory Access分析类型,可以识别缓存行争用:
- 运行Memory Access分析
- 查看"Contended Access"指标
- 定位高争用的内存地址
代码层面检测
某些工具可以自动检测伪共享。SHERIFF是马里兰大学开发的研究工具,能在运行时精确检测并自动修复伪共享问题。Huron则是一种混合检测/修复系统,可以在生产环境中使用。
解决方案:缓存行填充
解决伪共享的核心思想很简单:确保频繁更新的变量不共享缓存行。具体方法因语言而异。
Java:@Contended注解
Java 8引入了@Contended注解(位于jdk.internal.vm.annotation包),可以让JVM在字段周围添加填充:
public class Counter {
@jdk.internal.vm.annotation.Contended
volatile long count1;
@jdk.internal.vm.annotation.Contended
volatile long count2;
}
JDK内部大量使用了这个注解。java.util.concurrent.atomic.LongAdder的Cell类就是典型例子:
@jdk.internal.vm.annotation.Contended
static final class Cell {
volatile long value;
}
重要:@Contended默认只对JDK内部类生效。用户代码需要添加JVM参数:-XX:-RestrictContended。
填充大小默认128字节(可通过-XX:ContendedPaddingWidth调整),覆盖大多数架构的缓存行大小。
Go:CacheLinePad
Go的golang.org/x/sys/cpu包提供了CacheLinePad类型:
import "golang.org/x/sys/cpu"
type Counter struct {
count1 uint64
_ cpu.CacheLinePad
count2 uint64
_ cpu.CacheLinePad
}
Go运行时内部广泛使用这个技术。runtime/mheap.go、runtime/sema.go等源文件都能找到缓存行填充的痕迹。
CacheLinePad会根据目标架构自动选择正确的大小:
// x86/amd64
const CacheLinePadSize = 64
// arm64 (如Apple M系列)
const CacheLinePadSize = 128
C++:alignas和padding
C++17引入了std::hardware_destructive_interference_size,表示可能导致伪共享的最小对齐值:
struct alignas(std::hardware_destructive_interference_size) Counter {
std::atomic<uint64_t> count1;
};
struct Counters {
Counter c1;
Counter c2;
};
传统方法是手动添加填充字段:
struct Counter {
std::atomic<uint64_t> count1;
char padding[64 - sizeof(std::atomic<uint64_t>)];
};
Rust:内存对齐
Rust通过#[repr(align(n))]属性实现缓存行对齐:
#[repr(align(64))]
struct CacheAligned<T>(T);
struct Counters {
count1: CacheAligned<AtomicU64>,
count2: CacheAligned<AtomicU64>,
}
手动填充的局限性
手动填充存在几个问题:
- 可移植性差:不同架构缓存行大小不同
- 编译器优化:编译器可能重新排列字段,或优化掉未使用的padding字段
- 内存浪费:填充会显著增加内存占用
因此,优先使用语言/运行时提供的官方机制。
LMAX Disruptor:工业级最佳实践
LMAX的Disruptor是高性能队列的标杆实现,它的核心设计原则之一就是消除伪共享。
Ring Buffer的cursor字段
Ring Buffer的游标(cursor)是最频繁更新的字段之一。Disruptor在cursor前后各添加了7个long字段作为填充:
abstract class RingBufferPad {
protected long p1, p2, p3, p4, p5, p6, p7;
}
abstract class RingBufferFields<E> extends RingBufferPad {
// ... cursor和其他字段
}
7个long = 56字节,加上对象头的8-16字节,确保cursor独占一个缓存行。
Sequence类
Disruptor的Sequence类用于追踪进度,被多个线程频繁访问:
class LhsPadding {
volatile long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding {
volatile long value;
}
class RhsPadding extends Value {
volatile long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding {
// ...
}
前后都填充,确保value字段完全独占缓存行。
这种设计的效果是显著的:Disruptor实现了每秒数百万消息的吞吐量,远超传统阻塞队列。
NUMA架构:问题放大器
在NUMA(Non-Uniform Memory Access)架构下,伪共享问题更加严重。
NUMA系统中,每个CPU socket有自己的本地内存,访问本地内存快,访问远程内存慢。当伪共享涉及跨socket的核心时,缓存一致性流量需要经过QPI或UPI等互连链路,延迟比socket内部高一个数量级。
基准测试数据显示:在多socket系统上,伪共享导致的性能损失比单socket系统更大。某些情况下,添加缓存行填充后的性能提升可达数倍。
这解释了为什么服务器端应用(通常运行在多socket系统)比客户端应用更需要关注伪共享问题。
设计原则:预防胜于治疗
哪些场景需要警惕
伪共享不是到处都存在的问题,它只在特定场景下出现:
- 高频率写入:变量被频繁修改(如计数器、指针)
- 多线程访问:不同线程访问不同但相邻的变量
- 长时间运行:短生命周期程序可能看不出影响
设计决策
何时添加填充:
- 高性能库和数据结构的核心字段
- 多线程频繁更新的共享状态
- 已通过profiling确认的性能热点
何时不需要:
- 单线程或低并发场景
- 变量很少被更新
- 内存受限环境(填充会增加内存占用)
替代方案:
- Thread-Local Storage:每个线程有自己的副本,避免共享
- 批量操作:减少访问频率
- 无锁算法:某些场景下可避免频繁的缓存一致性通信
不要过度优化
伪共享优化是"最后一公里"的性能调优。在优化之前,应该先:
- 确保算法和数据结构最优
- 减少不必要的共享和同步
- 使用profiling确认瓶颈
过早添加缓存行填充会增加代码复杂度和内存占用,可能得不偿失。
深层理解:为什么硬件无法自动解决
一个常见的问题是:为什么CPU不能自动检测并避免伪共享?
答案在于信息的缺失。CPU知道缓存行的状态,但不知道:
- 这个缓存行中的哪些字节属于哪个变量
- 程序的意图是什么
- 哪些访问模式会导致性能问题
缓存一致性协议是保守的:只要缓存行中有任何字节被修改,整个缓存行都需要同步。这是正确性的要求,但牺牲了性能。
编译器理论上可以进行数据布局优化来避免伪共享,但这需要:
- 分析程序的并发访问模式
- 了解目标硬件的缓存行大小
- 权衡内存占用和性能
目前,这方面还主要依赖程序员的手动干预。
未来:自动检测与修复
研究界正在探索自动化解决方案:
静态分析:通过编译时分析识别潜在的伪共享模式,给出警告或自动重排字段。
动态检测:运行时监控缓存行为,发现热点后自动调整内存布局。
硬件支持:未来的CPU可能提供更细粒度的缓存一致性控制,允许软件指定缓存行的部分更新不需要全局同步。
但这些技术尚未成熟,目前仍需要程序员手动识别和修复。
结语:性能优化的最后一公里
伪共享是一个"隐形"的性能问题。它不会导致程序错误,只会让程序变慢——而且是在你添加更多核心时变得更慢。
理解伪共享,需要理解现代CPU缓存架构的深层原理:缓存行、MESI协议、缓存一致性流量。解决伪共享,需要在内存布局层面进行调整:缓存行填充、字段对齐、数据结构重组。
这不是一个"一劳永逸"的问题——不是所有代码都需要处理伪共享。但在高性能、高并发场景下,它可能是性能突破的关键。
记住LMAX工程师的教训:两行代码的改动(添加缓存行填充),可能带来十倍的性能提升。这就是深入理解底层原理的价值。
参考资料
-
Papamarcos, M. S., & Patel, J. H. (1984). A low-overhead coherence solution for multiprocessors with private cache memories. ISCA ‘84.
-
Sutter, H. (2009). Effective Concurrency: Eliminate False Sharing. Dr. Dobb’s Journal.
-
Thompson, M. (2011). False Sharing. Mechanical Sympathy Blog.
-
Liu, T., & Berger, E. D. (2011). SHERIFF: Precise detection and automatic mitigation of false sharing. OOPSLA ‘11.
-
Intel Corporation. Intel VTune Profiler Performance Analysis Cookbook: False Sharing.
-
Bolosky, W. J., & Scott, M. L. (1993). False sharing and its effect on shared memory performance. USENIX.
-
Wikipedia. MESI protocol. https://en.wikipedia.org/wiki/MESI_protocol
-
Wikipedia. False sharing. https://en.wikipedia.org/wiki/False_sharing
-
Baeldung. A Guide to False Sharing and @Contended. https://www.baeldung.com/java-false-sharing-contended
-
Hennessy, J. L., & Patterson, D. A. (2011). Computer Architecture: A Quantitative Approach. Morgan Kaufmann.
-
Sorin, D. J., Hill, M. D., & Wood, D. A. (2011). A Primer on Memory Consistency and Cache Coherence. Morgan & Claypool.
-
ClickHouse Blog. Optimizing ClickHouse for Intel’s ultra-high core count processors.
-
LMAX Disruptor Source Code. https://github.com/LMAX-Exchange/disruptor
-
Go Source Code. internal/cpu package. https://golang.org/x/sys/cpu