一个看似简单的面试题:在64位系统上,下面的结构体占多少字节?
struct Example {
char a; // 1字节
int b; // 4字节
char c; // 1字节
double d; // 8字节
};
把所有成员的大小加起来:1 + 4 + 1 + 8 = 14字节。但实际答案是24字节——比预期多了71%。
这不是编译器的bug,而是现代计算机体系结构的基本约束。理解内存对齐,就是理解CPU如何访问内存、编译器如何生成代码,以及性能与空间之间的永恒权衡。
从内存条到CPU:一条数据的物理旅程
当CPU需要读取一个32位整数时,它并不是"想读哪就读哪"。内存子系统有着物理层面的访问约束。
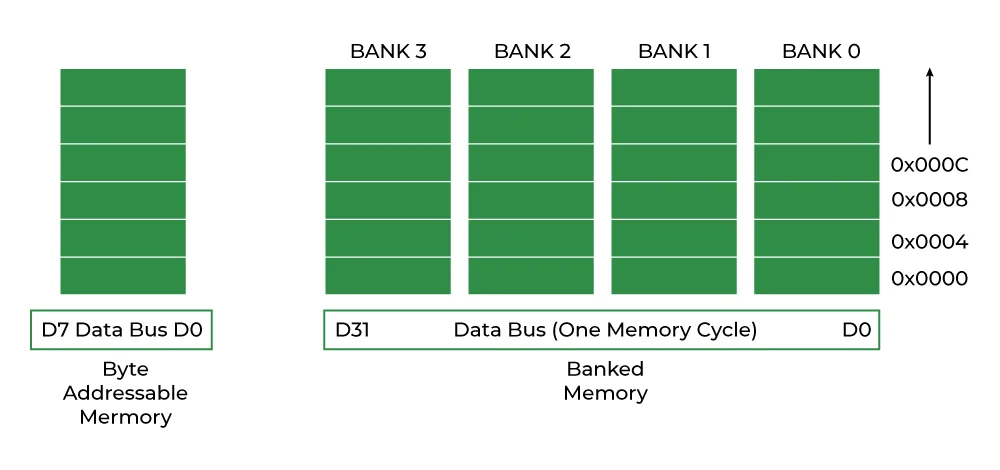
早期的32位处理器通常将内存组织为4个并行存储体(memory bank)。每个存储体宽度为1字节,分别对应地址的最低两位:00、01、10、11。当地址为0x1000(4的倍数)时,4个存储体同时工作,一个时钟周期就能读出完整的4字节数据。
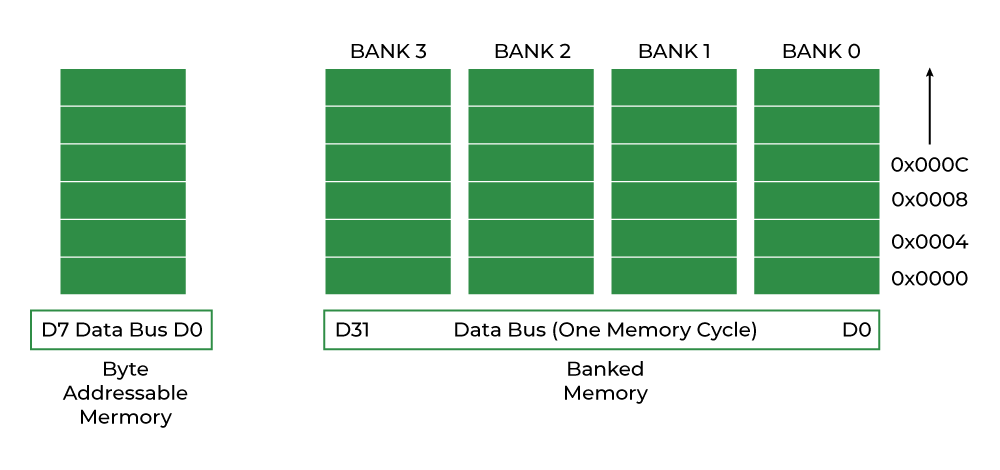
但如果这个整数存储在地址0x1001呢?它跨越了两个"行"——前3个字节在第一行,最后1个字节在第二行。处理器必须发起两次内存访问,然后把结果拼接起来。
图片来源: media.geeksforgeeks.org
{kind=link}
上图展示了对齐访问的理想情况:4字节整数恰好占据一个完整行,单次访问即可完成。
图片来源: media.geeksforgeeks.org
{kind=link}
上图则展示了非对齐访问:数据跨越两行,需要两次内存访问才能完成读取。
这就是"自然对齐"(natural alignment)的概念:N字节数据的起始地址应该是N的倍数。违背这个原则,轻则性能下降,重则程序崩溃。
结构体填充:编译器的暗中操作
回到开头的结构体。编译器看到的不是14字节的紧凑布局,而是这样的内存映像:
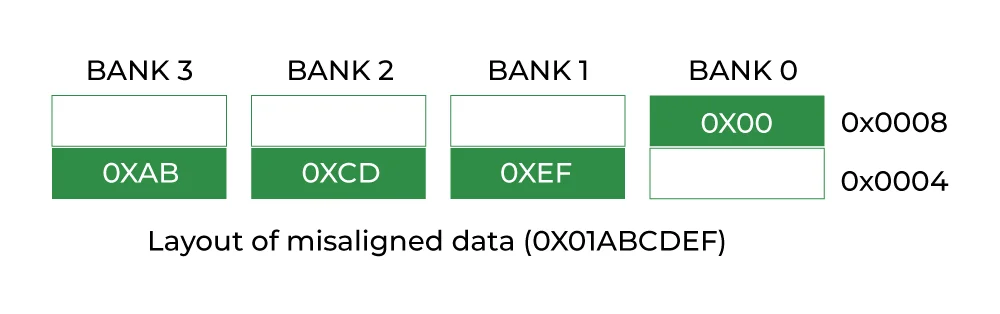
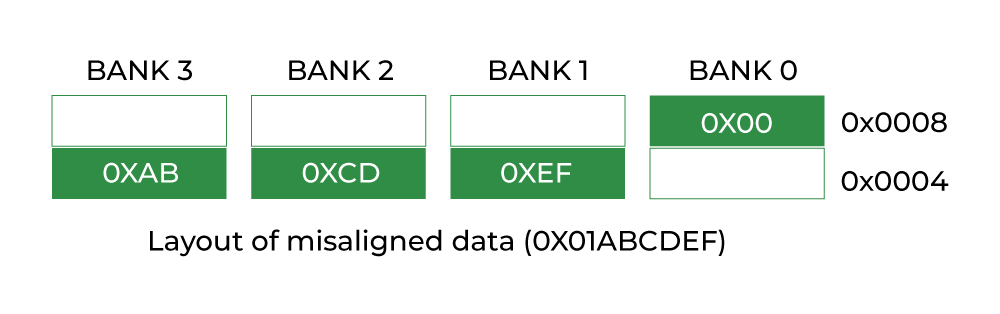
偏移量 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
|a |--|--|--| b (4字节) |c |--|--|--|--|--|--|--| d (8字节) |
+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+--+
填充(3字节) 填充(7字节)
填充字节的出现遵循三条规则:
-
成员对齐:每个成员的起始地址必须是其自身大小的倍数。
int b需要4字节对齐,所以char a后面插入3字节填充。 -
结构体对齐:结构体整体的大小必须是其最严格对齐成员的倍数。
double d要求8字节对齐,所以结构体总大小必须是8的倍数。 -
尾部填充:即使最后一个成员后面没有其他成员,也可能需要填充,以确保结构体数组中每个元素都正确对齐。
这解释了为什么24字节中只有14字节是实际数据。但更关键的问题是:编译器为什么要这样做?
硬件的底线:当非对齐访问引发崩溃
不同的CPU架构对非对齐访问的处理方式截然不同。这是理解内存对齐最重要的一点。
x86/x64:宽容但缓慢
Intel和AMD的处理器以"容错"著称。即使数据跨越缓存行边界、甚至跨越页面边界,硬件也会透明地处理——拆分成多次访问,拼装结果,程序继续执行。
但这并不意味着没有代价。根据Daniel Lemire在2012年的基准测试,非对齐访问的代价因情况而异:
- 缓存内非对齐:可能只有几个周期的额外开销
- 跨缓存行边界:可能增加到10-20个周期
- 跨页面边界(4KB):在Skylake之前的Intel处理器上可能超过100个周期
更严重的是,某些SIMD指令完全不支持非对齐操作。movaps(Move Aligned Packed Single-Precision Floating-Point)要求16字节对齐,违反就会触发通用保护异常(#GP)。即使编译器使用了支持非对齐的movups,性能也可能下降30%以上。
ARM:历史严格,现代宽容
ARM架构的演变清晰地展示了对齐观念的变迁。
ARMv5及更早版本:完全不支持非对齐访问。如果LDR指令尝试从非对齐地址加载32位数据,结果是未定义的——可能旋转数据,可能返回垃圾值,不会报错但数据错误。
ARMv6/ARMv7:开始支持非对齐访问,但需要启用U位。某些指令(如VFP浮点加载存储)仍然要求对齐。
ARM64(AArch64):大部分加载存储指令支持非对齐访问,但LDAPR等原子指令仍然要求自然对齐。
其他架构:不容妥协
某些架构对非对齐访问采取零容忍态度:
- SPARC:非对齐访问触发
SIGBUS信号,程序终止。 - MIPS:早期版本将非对齐地址低位截断,相当于访问了错误的地址。Linux内核文档明确指出:“某些架构会执行与你请求完全不同的内存访问,导致难以检测的隐蔽bug。”
- DEC Alpha:触发异常,由操作系统模拟处理——代价极高。
Linux内核维护着一个HAVE_EFFICIENT_UNALIGNED_ACCESS配置选项,用于在编译时区分架构:
支持高效非对齐访问的架构:x86、x86_64、ARM64
可能有条件支持的架构:ARMv6/v7、RISC-V(可选)
不支持高效非对齐访问的架构:MIPS、SPARC、Alpha
这就是为什么网络协议解析代码通常小心翼翼地使用get_unaligned()宏——同样的代码在x86上正常运行,在MIPS路由器上可能直接崩溃。
False Sharing:多核时代的隐形杀手
内存对齐的影响远不止单个变量访问。在多核系统中,对齐问题会演变为"伪共享"(False Sharing)——一种能让程序性能下降几个数量级的陷阱。
现代CPU的缓存以"缓存行"为单位工作,通常是64字节。当某个核心修改了缓存行中的任何一个字节,整个缓存行在所有其他核心的缓存中都会失效——无论其他核心是否在使用同一缓存行的不同数据。
考虑这个多线程累加的例子:
struct Counter {
long value;
};
struct Counter counters[4]; // 4个线程各自累加一个counter
看起来每个线程操作独立的变量,应该互不干扰。但sizeof(struct Counter) = 8,四个Counter恰好挤在两个缓存行内。当线程0修改counters[0]时,线程1的counters[1]虽然在逻辑上无关,却因为共享同一缓存行而被迫失效。
Hackaday在2026年的一篇文章中演示了这个问题:一个受False Sharing影响的程序比修复后的版本慢了100倍。
解决方案是对齐到缓存行边界:
struct Counter {
long value;
char padding[56]; // 填充到64字节
};
// 或使用C11的alignas
struct alignas(64) Counter {
long value;
};
这会浪费内存——每个Counter从8字节膨胀到64字节——但换来的是多核扩展性的巨大提升。这是典型的空间换时间权衡。
结构体重排序:免费的优化
回到最初的struct Example。只需要调整成员顺序,就能显著减小内存占用:
// 原始版本:24字节
struct Example {
char a; // 1字节 + 3字节填充
int b; // 4字节
char c; // 1字节 + 7字节填充
double d; // 8字节
};
// 重排序版本:16字节
struct Example_Optimized {
double d; // 8字节
int b; // 4字节
char a; // 1字节
char c; // 1字节 + 2字节填充
};
为什么有效?对齐要求遵循一个规律:对齐更严格的成员(更大的数据类型)如果能放在前面,后续对齐要求更低的成员就能"塞进"剩余空间。
Eric S. Raymond在《The Lost Art of Structure Packing》中给出了更极端的例子:
// 24字节,超过50%是填充
struct foo5 {
char c; // 1字节 + 7字节填充
struct {
char *p; // 8字节
short x; // 2字节 + 6字节填充
} inner;
};
// 重排序后16字节
struct foo11 {
char *p; // 8字节
short x; // 2字节
char c; // 1字节 + 5字节填充
};
一个实用技巧:将成员按大小降序排列——指针/double在前,int/float居中,short靠后,char垫底。这个规则简单易记,在大多数情况下能消除大部分填充。
需要注意的是,C和C++标准不允许编译器自动重排序结构体成员——这是为了支持内存映射I/O和网络协议解析等场景,程序员需要精确控制每个字节的布局。Rust选择了不同的路径:默认情况下可以重排序,除非使用#[repr(C)]属性。
packed属性:危险的双刃剑
当必须消除所有填充时,GCC和Clang提供了__attribute__((packed)):
struct __attribute__((packed)) PackedExample {
char a;
int b;
char c;
double d;
};
sizeof(struct PackedExample) == 14 // 没有任何填充
这看起来完美解决了问题——内存占用最小化。但代价是什么?
Stack Overflow上有一个经典警告:packed结构体在ARM上可能导致程序崩溃。当编译器生成访问int b的代码时,它会假设地址是4字节对齐的。但实际上b位于偏移量1,地址可能是0x1001。在ARMv5上,这会返回错误数据;在某些配置下,甚至触发异常。
即使编译器聪明地识别出非对齐访问并生成特殊代码(使用get_unaligned语义),性能也会显著下降。更重要的是,指向packed结构体成员的指针是非对齐指针,将其传递给期望对齐指针的函数是未定义行为——这种bug极其隐蔽,可能只在特定优化级别或特定架构上触发。
packed的唯一正当用途是匹配外部定义的二进制格式——网络协议头、文件格式、硬件寄存器布局。在这些场景中,使用memcpy逐字节复制比直接访问成员更安全。
动态内存的对齐控制
malloc返回的内存保证适合任何内置类型——在32位系统上至少4字节对齐,64位系统上至少8字节(某些实现保证16字节)。但这对于SIMD和缓存行对齐是不够的。
C11引入了aligned_alloc:
// 分配64字节对齐的内存
void *ptr = aligned_alloc(64, 1024);
if (ptr) {
// 使用...
free(ptr);
}
POSIX提供了posix_memalign,Windows有_aligned_malloc。这些函数允许程序员精确控制内存对齐,对于高性能计算、游戏引擎、数据库系统至关重要。
一个更高级的场景:分配恰好对齐到缓存行、且大小为缓存行倍数的内存块,以确保每个线程的私有数据占据独立的缓存行。这在无锁数据结构和高性能计数器实现中是标准做法。
对齐的边界:当规则被打破
某些特殊场景打破了常规对齐规则:
原子操作:C++的std::atomic对对齐有额外要求。在x86上,对齐到缓存行的原子变量可以避免LOCK#信号在总线上的广播,显著提升多核性能。std::atomic_ref<T>::required_alignment给出了平台特定的最小对齐要求。
DMA传输:直接内存访问控制器通常要求缓冲区对齐到特定的边界——可能是字边界(4字节)、缓存行边界(64字节)或页面边界(4KB)。违反这些要求可能导致数据损坏或硬件错误。
虚拟化:在虚拟机中,客户物理地址到宿主物理地址的翻译(通过EPT或NPT)为对齐增加了另一层复杂性。大页面依赖对齐到2MB或1GB边界,否则翻译效率急剧下降。
工具与实践
诊断对齐问题的工具比想象中丰富:
编译器警告:Clang的-Wpadded会报告结构体中的填充。GCC的-Wpadded不太完善,但可以结合pahole工具(DWARF调试信息的分析工具)查看结构体的精确布局。
静态断言:C11的static_assert可以在编译时验证结构体大小:
static_assert(sizeof(struct Example) == 24, "结构体大小不符合预期");
运行时检测:在ARM Linux上,可以通过设置/proc/cpu/alignment让内核捕获非对齐访问并报告:
echo 3 > /proc/cpu/alignment # 启用警告和修复
写在最后
内存对齐不是过早优化,而是理解计算机系统如何工作的基础。一个成员顺序混乱的结构体可能在64位x86上只是浪费几字节内存,在32位ARM上让性能下降20%,在MIPS上直接崩溃。
这不是要程序员对每个结构体斤斤计较。Eric S. Raymond的建议是务实的:先让代码正确运行,再根据实际瓶颈决定是否优化。但当你在处理百万级实例的数据结构、编写跨平台代码、或者设计高性能系统时,对齐知识就是区分"能用"和"好用"的关键。
下一次看到sizeof返回意外的结果时,记住:编译器没有犯错——它在遵守硬件的规则。而理解这些规则,是每个系统程序员的必修课。
参考文献
- Bobrow, D. G., et al. “TENEX, a Paged Time Sharing System for the PDP-10.” Communications of the ACM, 1972.
- “Data structure alignment.” Wikipedia. https://en.wikipedia.org/wiki/Data_structure_alignment
- “Unaligned Memory Accesses.” Linux Kernel Documentation. https://docs.kernel.org/core-api/unaligned-memory-access.html
- Raymond, Eric S. “The Lost Art of Structure Packing.” http://www.catb.org/esr/structure-packing/
- Lemire, Daniel. “Data alignment for speed: myth or reality?” https://lemire.me/blog/2012/05/31/data-alignment-for-speed-myth-or-reality/
- “Structure Member Alignment, Padding and Data Packing.” GeeksforGeeks. https://www.geeksforgeeks.org/c/structure-member-alignment-padding-and-data-packing/
- Vit Labuda. “Unaligned memory access on various CPU architectures.” https://blog.vitlabuda.cz/2025/01/22/unaligned-memory-access-on-various-cpu-architectures.html
- “SSE and AVX behavior with aligned/unaligned instructions.” Intel Community. https://community.intel.com/t5/Intel-ISA-Extensions/SSE-and-AVX-behavior-with-aligned-unaligned-instructions/td-p/1170000
- “Making Code A Hundred Times Slower With False Sharing.” Hackaday, 2026. https://hackaday.com/2026/01/14/making-code-a-hundred-times-slower-with-false-sharing/
- “Data Alignment Across Architectures: The Good, The Bad and The Ugly.” Hackaday, 2022. https://hackaday.com/2022/05/10/data-alignment-across-architectures-the-good-the-bad-and-the-ugly/
- “Memory alignment for speed.” Stack Overflow. https://stackoverflow.com/questions/2006216/why-is-data-structure-alignment-important-for-performance
- “alignas specifier (since C++11).” cppreference. https://en.cppreference.com/w/cpp/language/alignas
- “aligned_alloc.” cppreference. https://en.cppreference.com/w/c/memory/aligned_alloc
- Bryant, Randal E., O’Hallaron, David. “Computer Systems: A Programmer’s Perspective.” Pearson, 2015.