三个工人、三份工作,每个人只能胜任其中几份。如何安排才能让最多的人找到工作?这个问题看似简单,却隐藏着图论中最优雅的算法之一——二分图匹配。它不仅能解决工作分配问题,还能处理从课程排期到广告投放的各类实际场景。
什么是二分图匹配
二分图(Bipartite Graph)是一种特殊的图结构:顶点可以被分成两个不相交的集合,所有边都只连接两个集合之间的顶点,集合内部没有任何边。想象一下,如果把男性和女性分别放在图的两侧,每条边代表"可以配对",那么这就是一个典型的二分图。
匹配(Matching)是图中一组互不相交的边的集合——也就是说,没有任何两条边共享同一个顶点。如果一条边属于匹配,它的两个端点就被称为"已匹配";否则就是"未匹配"或"自由"的。
最大匹配是指边数最多的匹配。当匹配的边数等于较小顶点集的大小时,称为完美匹配——此时较小集合中的每个顶点都被匹配了。
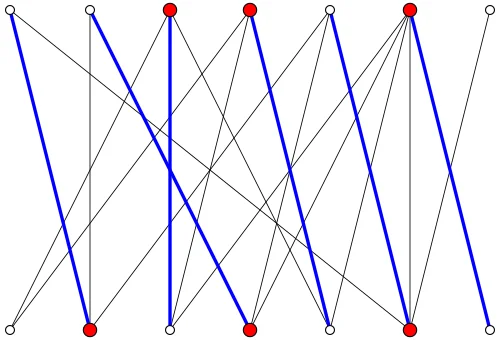
增广路:匹配扩充的核心机制
理解二分图匹配的关键在于增广路(Augmenting Path)这个概念。
增广路是一条特殊的路径:它从一个未匹配顶点出发,交替经过非匹配边和匹配边,最终到达另一个未匹配顶点。由于路径的首尾都是非匹配边,所以增广路中非匹配边的数量恰好比匹配边多一条。
这意味着什么?如果我们把增广路上的匹配边和非匹配边"翻转"——原来的匹配边变成非匹配边,原来的非匹配边变成匹配边——匹配的边数就会增加一条!
1957年,法国数学家Claude Berge提出了著名的Berge定理:
一个匹配是最大匹配,当且仅当图中不存在增广路。
这一定理的直接推论是:只要还能找到增广路,当前的匹配就不是最大的。这构成了匈牙利算法的理论基础。
匈牙利算法的实现原理
匈牙利算法由Harold Kuhn于1955年提出,他将其命名为"匈牙利方法",以致敬两位匈牙利数学家Dénes Kőnig和Jenő Egerváry的早期工作。有趣的是,2006年人们发现Carl Gustav Jacobi早在19世纪就解决了这个问题,并于1890年以拉丁文发表。
算法的核心思想非常直接:对于左侧集合中的每个顶点,尝试找到一条增广路。如果找到了,就沿着这条路翻转边,匹配数加一。
public class HungarianAlgorithm {
private int[][] graph; // 邻接矩阵表示二分图
private int[] matchRight; // 右侧顶点匹配的左侧顶点
private boolean[] visited; // DFS访问标记
private int n, m; // 左右两侧顶点数
public int maxMatching(int[][] graph, int n, int m) {
this.graph = graph;
this.n = n;
this.m = m;
matchRight = new int[m];
Arrays.fill(matchRight, -1);
int result = 0;
for (int u = 0; u < n; u++) {
visited = new boolean[m];
if (findAugmentingPath(u)) {
result++;
}
}
return result;
}
// DFS寻找从顶点u出发的增广路
private boolean findAugmentingPath(int u) {
for (int v = 0; v < m; v++) {
// 存在边且未被访问
if (graph[u][v] == 1 && !visited[v]) {
visited[v] = true;
// v未匹配,或v的匹配点可以找到新的匹配
if (matchRight[v] == -1 || findAugmentingPath(matchRight[v])) {
matchRight[v] = u;
return true;
}
}
}
return false;
}
}
算法的时间复杂度是 $O(V \times E)$,其中 $V$ 是顶点数,$E$ 是边数。每个左侧顶点最多尝试一次,每次尝试最多遍历所有边。
König定理:最大匹配与最小顶点覆盖的对偶关系
1931年,Dénes Kőnig证明了二分图上一个优美的性质:
在任意二分图中,最大匹配的边数等于最小顶点覆盖的顶点数。
顶点覆盖是指一组顶点,使得图中的每条边至少有一个端点在这组顶点中。最小顶点覆盖就是顶点数最少的覆盖。
这个定理的意义在于:它建立了两个看似无关的问题之间的等价关系。通过找到最大匹配,我们同时也就找到了最小顶点覆盖——这在NP难的一般图中是不可能的,但在二分图中却是多项式可解的。
从算法角度看,给定一个最大匹配,可以这样构造最小顶点覆盖:
- 找出所有左侧未匹配的顶点
- 从这些顶点出发,沿交替路径标记可达的顶点
- 最小顶点覆盖 = (左侧未被标记的顶点)∪(右侧被标记的顶点)
Hopcroft-Karp算法:复杂度的优化
匈牙利算法虽然正确,但在稠密图上可能较慢。1973年,John Hopcroft和Richard Karp提出了一个改进算法,将时间复杂度优化到 $O(E\sqrt{V})$。
核心优化思想是:不要每次只找一条增广路,而是同时找多条最短的、互不相交的增广路,然后一次性全部翻转。这减少了迭代次数:从原来的 $O(V)$ 次降到 $O(\sqrt{V})$ 次。
public class HopcroftKarp {
private List<List<Integer>> adj;
private int[] pairU, pairV, dist;
private int n, m;
private static final int INF = Integer.MAX_VALUE;
public int maxMatching(List<List<Integer>> adj, int n, int m) {
this.adj = adj;
this.n = n;
this.m = m;
pairU = new int[n];
pairV = new int[m];
dist = new int[n];
Arrays.fill(pairU, -1);
Arrays.fill(pairV, -1);
int result = 0;
while (bfs()) {
for (int u = 0; u < n; u++) {
if (pairU[u] == -1 && dfs(u)) {
result++;
}
}
}
return result;
}
// BFS构建层次图,寻找最短增广路
private boolean bfs() {
Queue<Integer> queue = new LinkedList<>();
for (int u = 0; u < n; u++) {
if (pairU[u] == -1) {
dist[u] = 0;
queue.add(u);
} else {
dist[u] = INF;
}
}
boolean found = false;
while (!queue.isEmpty()) {
int u = queue.poll();
for (int v : adj.get(u)) {
int nextU = pairV[v];
if (nextU != -1 && dist[nextU] == INF) {
dist[nextU] = dist[u] + 1;
queue.add(nextU);
} else if (nextU == -1) {
found = true; // 找到增广路终点
}
}
}
return found;
}
// DFS沿层次图寻找增广路
private boolean dfs(int u) {
for (int v : adj.get(u)) {
int nextU = pairV[v];
if (nextU == -1 || (dist[nextU] == dist[u] + 1 && dfs(nextU))) {
pairU[u] = v;
pairV[v] = u;
return true;
}
}
dist[u] = INF;
return false;
}
}
LeetCode经典题目详解
LeetCode 785. 判断二分图
判断一个图是否是二分图,最直接的方法是染色法:尝试用两种颜色给顶点染色,如果存在相邻顶点颜色相同,则不是二分图。
class Solution {
public boolean isBipartite(int[][] graph) {
int n = graph.length;
int[] color = new int[n]; // 0: 未染色, 1: 颜色A, -1: 颜色B
for (int i = 0; i < n; i++) {
if (color[i] == 0) {
if (!dfs(graph, color, i, 1)) {
return false;
}
}
}
return true;
}
private boolean dfs(int[][] graph, int[] color, int node, int c) {
color[node] = c;
for (int neighbor : graph[node]) {
if (color[neighbor] == c) {
return false; // 相邻节点同色
}
if (color[neighbor] == 0 && !dfs(graph, color, neighbor, -c)) {
return false;
}
}
return true;
}
}
LeetCode 1820. 最多接受邀请数
这道题是经典的最大二分图匹配问题:n个男生和n个女生,每个男生可以邀请部分女生,求最多能成功邀请多少对。
class Solution {
public int maximumInvitations(int[][] grid) {
int m = grid.length; // 男生数
int n = grid[0].length; // 女生数
int[] matchGirl = new int[n];
Arrays.fill(matchGirl, -1);
int result = 0;
for (int boy = 0; boy < m; boy++) {
boolean[] visited = new boolean[n];
if (canMatch(grid, boy, visited, matchGirl)) {
result++;
}
}
return result;
}
private boolean canMatch(int[][] grid, int boy, boolean[] visited, int[] matchGirl) {
int n = grid[0].length;
for (int girl = 0; girl < n; girl++) {
if (grid[boy][girl] == 1 && !visited[girl]) {
visited[girl] = true;
// 女生未匹配,或该女生当前匹配的男生能找到其他女生
if (matchGirl[girl] == -1 ||
canMatch(grid, matchGirl[girl], visited, matchGirl)) {
matchGirl[girl] = boy;
return true;
}
}
}
return false;
}
}
LeetCode 1349. 参加考试的最大学生数
这道题需要将座位问题转化为二分图匹配。关键观察是:可以把座位分成两类(类似棋盘的黑白格),同类的座位不会相邻,因此可以把问题建模为二分图的最大独立集问题。
由于最大独立集 = 总顶点数 - 最小顶点覆盖 = 总顶点数 - 最大匹配,问题转化为求最大匹配。
class Solution {
public int maxStudents(char[][] seats) {
int m = seats.length, n = seats[0].length;
// 将有效座位编号,分为奇数位和偶数位两类
int[][] seatId = new int[m][n];
List<int[]> oddSeats = new ArrayList<>();
List<int[]> evenSeats = new ArrayList<>();
for (int i = 0; i < m; i++) {
for (int j = 0; j < n; j++) {
if (seats[i][j] == '.') {
if ((i + j) % 2 == 1) {
seatId[i][j] = oddSeats.size();
oddSeats.add(new int[]{i, j});
} else {
seatId[i][j] = evenSeats.size();
evenSeats.add(new int[]{i, j});
}
}
}
}
// 构建二分图的邻接表
int[][] dirs = {{-1, -1}, {-1, 1}, {0, -1}, {0, 1}, {1, -1}, {1, 1}};
List<List<Integer>> adj = new ArrayList<>();
for (int i = 0; i < oddSeats.size(); i++) {
adj.add(new ArrayList<>());
}
for (int[] seat : oddSeats) {
int r = seat[0], c = seat[1];
int id = seatId[r][c];
for (int[] d : dirs) {
int nr = r + d[0], nc = c + d[1];
if (nr >= 0 && nr < m && nc >= 0 && nc < n && seats[nr][nc] == '.') {
adj.get(id).add(seatId[nr][nc]);
}
}
}
// 匈牙利算法求最大匹配
int[] match = new int[evenSeats.size()];
Arrays.fill(match, -1);
int maxMatch = 0;
for (int u = 0; u < oddSeats.size(); u++) {
boolean[] visited = new boolean[evenSeats.size()];
if (findMatch(u, adj, match, visited)) {
maxMatch++;
}
}
return oddSeats.size() + evenSeats.size() - maxMatch;
}
private boolean findMatch(int u, List<List<Integer>> adj, int[] match, boolean[] visited) {
for (int v : adj.get(u)) {
if (!visited[v]) {
visited[v] = true;
if (match[v] == -1 || findMatch(match[v], adj, match, visited)) {
match[v] = u;
return true;
}
}
}
return false;
}
}
LeetCode 2410. 运动员与教练的最大匹配
这道题可以转化为贪心问题或二分图匹配。由于只需要统计最大匹配数而不需要具体的匹配方案,排序后使用双指针或贪心会更高效。但如果需要具体匹配方案,匈牙利算法是正确的选择。
class Solution {
public int matchPlayersAndTrainers(int[] players, int[] trainers) {
Arrays.sort(players);
Arrays.sort(trainers);
int i = 0, j = 0, matches = 0;
while (i < players.length && j < trainers.length) {
if (trainers[j] >= players[i]) {
matches++;
i++;
}
j++;
}
return matches;
}
}
算法选择指南
| 算法 | 时间复杂度 | 适用场景 |
|---|---|---|
| 匈牙利算法(DFS) | $O(VE)$ | 简单实现、稀疏图 |
| 匈牙利算法(BFS) | $O(VE)$ | 避免递归栈溢出 |
| Hopcroft-Karp | $O(E\sqrt{V})$ | 大规模数据、稠密图 |
| 网络流(Dinic) | $O(E\sqrt{V})$ | 需要处理带权或容量约束 |
实际应用场景
二分图匹配在现实中有着广泛的应用:
任务调度与资源分配:将任务分配给工人、课程分配给教室、航班分配给登机口。每个任务有特定的约束条件,目标是最大化资源利用率。
广告推荐系统:用户与广告构成二分图,边代表用户可能对广告感兴趣。最大匹配帮助平台在满足用户体验的前提下最大化广告曝光。
目标跟踪:在视频中跟踪多个目标时,相邻帧之间的检测框需要关联。二分图匹配帮助确定哪个框属于哪个目标。
编译器寄存器分配:将变量分配到有限的寄存器中,变量和寄存器构成二分图,冲突变量不能共享寄存器。
从网络流视角理解
二分图最大匹配可以转化为网络流问题:
- 添加源点 $s$ 和汇点 $t$
- 从 $s$ 向左侧每个顶点连一条容量为1的边
- 从右侧每个顶点向 $t$ 连一条容量为1的边
- 将原图的边改为从左向右、容量为1的边
此时,最大流量等于最大匹配数。这种转换让我们可以利用成熟的网络流算法来解决匹配问题。
总结
二分图匹配问题的美妙之处在于:一个看似简单的"配对"问题,背后蕴含着深刻的数学结构。从Berge定理的增广路条件,到König定理的对偶关系,再到Hopcroft-Karp的复杂度优化,这些理论不仅相互支撑,还为实际问题的解决提供了清晰的思路。
掌握二分图匹配,不仅是学习一个算法,更是理解图论中"匹配"、“覆盖”、“独立集"这三个核心概念如何相互作用的过程。当遇到资源分配、任务调度、目标跟踪等问题时,二分图匹配往往是第一个值得尝试的模型。