打开Python解释器,输入一个简单的递归函数:
def count(n):
if n <= 0:
return 0
return 1 + count(n - 1)
print(count(10000))
程序崩溃,抛出 RecursionError: maximum recursion depth exceeded。把同样的逻辑翻译成Scheme,却能轻松处理百万次递归调用。这不是Python的bug,而是两种语言对函数调用栈的根本性设计差异。
要理解这个差异,需要深入到底层:CPU如何执行函数调用,栈帧究竟是什么,以及编译器如何通过尾递归优化让递归"免费"。
栈帧:函数调用的物理实体
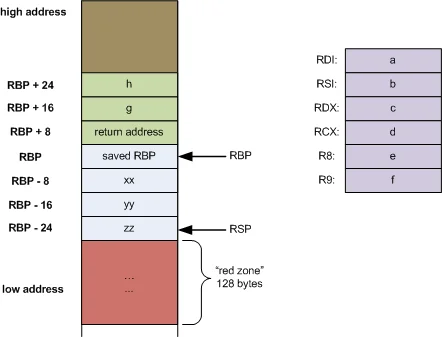
当一个函数调用另一个函数时,CPU需要记录三件事:返回地址(调用完成后从哪里继续执行)、传递给被调用函数的参数、被调用函数的局部变量。这些信息被打包成一个栈帧(stack frame),压入调用栈。
以x86-64架构为例,一个典型的栈帧包含以下内容:
图片来源: eli.thegreenplace.net
{kind=link}
从高地址向低地址依次是:
- 返回地址:
call指令自动将下一条指令的地址压栈 - 保存的基址指针(rbp):指向调用者的栈帧基址
- 局部变量:函数内部声明的变量
- 临时空间:中间计算结果
每次函数调用都会创建一个新的栈帧,每次函数返回都会销毁当前栈帧。这个过程由编译器生成的**函数序言(prologue)和函数尾声(epilogue)**完成:
; 函数序言 - 创建栈帧
push rbp ; 保存旧的基址指针
mov rbp, rsp ; 设置新的基址指针
sub rsp, 32 ; 为局部变量分配空间
; 函数体
; ... 实际代码 ...
; 函数尾声 - 销毁栈帧
mov rsp, rbp ; 恢复栈指针
pop rbp ; 恢复旧的基址指针
ret ; 返回(弹出返回地址并跳转)
栈空间是有限的。Linux默认为每个线程分配8MB栈空间,Windows默认1MB。一个栈帧的大小取决于函数的参数数量和局部变量大小。假设一个简单的递归函数每次调用创建48字节的栈帧,在Linux上大约可以递归17万次,在Windows上只能递归2万次左右。超过这个限制,CPU尝试访问栈边界之外的内存,触发段错误(segmentation fault)。
这就是栈溢出的物理本质:栈帧的累积超出了预分配的栈空间。
尾调用:可以被优化的特殊情况
并非所有函数调用都需要创建新的栈帧。考虑下面的代码:
int add_five(int x) {
return x + 5;
}
int wrapper(int x) {
return add_five(x); // 尾调用
}
wrapper 函数调用 add_five 后立即返回,没有任何后续操作。这种调用称为尾调用(tail call)——函数执行的最后一个动作是调用另一个函数。
尾调用有一个关键特性:调用者的栈帧在尾调用发生后就没有用了。调用者不会再访问任何局部变量,不会再执行任何代码,只需要把被调用者的返回值直接传给自己的调用者。这意味着,尾调用可以复用调用者的栈帧,而不是创建新的。
编译器可以将尾调用实现为跳转指令:
; 未优化:真正的函数调用
wrapper:
sub rsp, 8 ; 对齐栈
call add_five ; 调用函数(会压入返回地址)
add rsp, 8 ; 清理栈
ret ; 返回
; 优化后:直接跳转
wrapper:
jmp add_five ; 直接跳转,复用当前栈帧
这就是尾调用优化(Tail Call Optimization, TCO):将尾调用编译为跳转指令,避免创建新的栈帧。对于递归函数,如果每次递归调用都是尾调用,那么无论递归多少次,栈帧数量始终保持为1——永远不会栈溢出。
尾递归:递归的特殊形式
当尾调用指向函数自身时,称为尾递归(tail recursion)。以阶乘为例:
// 非尾递归版本
int factorial(int n) {
if (n <= 1) return 1;
return n * factorial(n - 1); // 递归调用后还要乘以n
}
// 尾递归版本
int factorial_tail(int n, int acc) {
if (n <= 1) return acc;
return factorial_tail(n - 1, n * acc); // 尾调用
}
非尾递归版本中,factorial(n-1) 返回后还需要乘以 n,所以每次调用都必须保留栈帧。尾递归版本中,factorial_tail(n-1, n*acc) 是函数的最后一个动作,返回后直接把结果传给上层调用者。
GCC和Clang在开启优化(-O2或更高)时会自动进行尾递归优化。查看编译后的汇编代码:
factorial_tail:
test edi, edi
jle .L_return_acc
.L_loop:
imul esi, edi ; acc *= n
dec edi ; n--
test edi, edi
jg .L_loop ; 跳转而非调用
.L_return_acc:
mov eax, esi
ret
递归被转换为循环,没有任何 call 指令。这就是尾递归优化的魔力:将O(n)空间复杂度的递归转换为O(1)的循环。
为什么不是所有语言都支持尾递归优化
既然尾递归优化如此强大,为什么Python默认递归深度只有1000,为什么V8引擎放弃了对TCO的支持?
Python的立场:调试优先
Python的创始人Guido van Rossum在2009年的博客文章《Tail Recursion Elimination》中明确拒绝了尾递归优化。他的理由是:
- 栈追踪变得无意义:当发生错误时,栈追踪只能看到最后一个函数调用,丢失了完整的调用历史,调试变得极其困难。
- 语言分裂风险:如果TCO成为可选特性,依赖TCO的代码在没有TCO的实现上会崩溃,导致语言生态分裂。
- 语义不透明:程序员需要理解TCO才能写出正确的代码,这违背了Python"显式优于隐式"的设计哲学。
Python选择了一个不同的策略:默认限制递归深度为1000,超过就抛出异常。这是一个安全阀,防止无限递归导致C栈溢出进而崩溃整个解释器。程序员可以通过 sys.setrecursionlimit() 调整限制,但官方文档警告这样做"可能安全也可能不安全"。
JavaScript的困境:实现复杂度
ES6标准明确要求实现"proper tail calls",但现实是:只有Safari的JavaScriptCore引擎完整实现了这个特性。V8(Chrome和Node.js)和SpiderMonkey(Firefox)都没有实现。
原因在于TCO与JavaScript的工程实现存在冲突:
- 调试信息丢失:与Python相同,TCO会破坏调试栈追踪。
- 性能权衡:V8团队发现实现TCO需要在每次函数调用时检查是否是尾调用位置,这个检查本身会带来性能开销。
- 兼容性负担:TCO改变函数调用的语义,某些依赖调用栈深度的代码会行为异常。
函数式语言的必然选择
Scheme、Haskell、Erlang等函数式语言则选择了另一条路:将TCO作为语言规范的一部分。
Scheme从1975年诞生起就将"proper tail recursion"写入标准。1998年,William Clinger发表的论文《Proper Tail Recursion and Space Efficiency》正式定义了"proper tail recursion"的含义:一个实现如果支持任意数量的活跃尾调用,就是properly tail recursive的。
这种选择源于函数式编程的范式:递归是主要的迭代手段,没有TCO,任何复杂的递归算法都会栈溢出。
Go和Rust:不同的设计权衡
Go:可增长栈
Go语言没有TCO,但它的goroutine栈可以从2KB动态增长到1GB。当栈空间不足时,Go运行时会分配一个更大的栈,将旧栈的内容复制过去,并更新所有指向栈的指针。这被称为连续栈(contiguous stack),在Go 1.4中取代了早期的分段栈(split stack)。
这种设计让goroutine可以处理深度递归,同时保持极低的初始内存占用。代价是栈增长时需要暂停goroutine进行复制,以及指针更新的复杂性。
Rust:显式尾调用
Rust在很长一段时间内没有TCO,但在2025年,become关键字被引入Nightly版本,提供显式的尾调用语法:
fn factorial_tail(n: u64, acc: u64) -> u64 {
if n <= 1 {
acc
} else {
become factorial_tail(n - 1, n * acc) // 显式尾调用
}
}
become 关键字明确告诉编译器这是一个尾调用,如果编译器无法优化,会报错而非默默回退到普通调用。这种设计借鉴了Clang的 [[musttail]] 属性,让程序员可以确定TCO是否生效。
尾递归优化的限制条件
即使编译器支持TCO,也不是所有尾调用都能被优化。常见的限制条件包括:
1. 调用约定约束
在C语言的调用约定中,调用者负责清理栈上的参数。如果函数A有3个参数,它只能尾调用参数数量≤3的函数,否则栈帧大小不匹配。
2. 逃逸分析
如果被调用函数需要访问调用者栈帧中的数据(比如通过指针),则不能优化:
void escape_example(int *p) {
int local = 42;
p = &local; // local的地址逃逸
escape_example(p); // 无法优化
}
3. 析构函数(C++/Rust)
如果调用者的局部变量有析构函数需要在函数返回前执行,则不能优化:
void cpp_example() {
std::string s = "hello";
cpp_example(); // s的析构函数需要在返回前执行
}
这也是Rust直到最近才引入显式尾调用的原因之一——Rust的所有权系统需要在函数退出时正确处理资源释放。
4. 异常处理
如果调用者有活跃的异常处理帧,尾调用优化可能会破坏异常传播链。
当TCO不可用时:工程解决方案
在Python、Java等不支持TCO的语言中,如何处理深度递归?
方案一:手动栈模拟
将递归转换为显式的栈操作:
def factorial_iterative(n):
stack = [(n, 1)] # (n, accumulator)
while stack:
n, acc = stack.pop()
if n <= 1:
return acc
stack.append((n - 1, n * acc))
return 1
这种方法将栈帧存储在堆上,堆空间远大于栈空间,可以处理任意深度的"递归"。
方案二:蹦床(Trampoline)
对于相互递归的情况,可以使用蹦床模式:
def trampoline(f, *args):
result = f(*args)
while callable(result):
result = result()
return result
def factorial_trampoline(n, acc=1):
if n <= 1:
return acc
return lambda: factorial_trampoline(n - 1, n * acc)
# 使用
result = trampoline(factorial_trampoline, 10000)
每次递归返回一个thunk(延迟计算的函数),由外层的蹦床函数负责调用。由于每次返回都会清理栈帧,栈空间始终保持在O(1)。
方案三:改写为循环
对于简单的尾递归,直接改写为循环是最简单的:
def factorial_loop(n):
acc = 1
while n > 1:
acc *= n
n -= 1
return acc
这本质上就是编译器TCO做的事情——程序员手动完成了编译器的工作。
栈溢出的安全维度
栈溢出不仅是正确性问题,也是安全问题。历史上著名的缓冲区溢出攻击——Morris蠕虫(1988)、Code Red(2001)、SQL Slammer(2003)——都利用了栈溢出漏洞。
攻击原理是:通过向栈上的缓冲区写入超过其大小的数据,覆盖返回地址,使程序跳转到攻击者指定的代码。现代系统通过以下机制防护:
- 栈保护器(Stack Canary):在返回地址前放置一个随机值,函数返回前检查该值是否被修改
- ASLR(地址空间布局随机化):随机化栈的起始地址,使攻击者难以预测目标地址
- DEP/NX(数据执行保护):将栈内存标记为不可执行
这些防护增加了利用难度,但并未解决栈溢出的根本问题——只是把崩溃变成安全终止,而非远程代码执行。
现代编译器的TCO实现细节
Clang的 [[musttail]] 属性和GCC的尾调用优化使用不同的实现策略。
Clang的 musttail 是一个强制约束:如果编译器无法优化该尾调用,会报错而非生成普通调用。这通过以下条件判断:
// 必须满足所有条件才能优化:
// 1. 调用是函数的最后一个动作
// 2. 返回类型与调用者相同
// 3. 调用约定兼容
// 4. 无需执行析构函数
GCC则采用更宽松的策略:在 -O2 及以上优化级别,尽可能进行尾调用优化,但不会强制保证。可以通过 -foptimize-sibling-calls 标志控制。
Python 3.14引入了尾调用解释器,这是一个有趣的折中:解释器内部使用尾调用实现字节码分发,提升解释器性能约3-5%,但这不改变Python语言的语义——用户代码仍然没有TCO。
总结:理解栈,才能理解递归
递归调用的栈溢出不是一个bug,而是计算机体系结构的基本约束。栈帧需要空间,空间是有限的。不同的语言选择了不同的权衡:
- Scheme/Haskell:将TCO作为语言规范,递归成为一等公民
- Go:可增长栈,用内存换简单
- Rust:显式尾调用,将控制权交给程序员
- Python/Java:拒绝TCO,保持调试友好
- JavaScript:标准要求但实现缺失,留下历史债务
没有万能的解法。理解栈帧如何工作、理解TCO的条件和限制、掌握TCO不可用时的替代方案——这些是每个程序员都应该具备的底层知识。当你在白板前写下递归解法时,记得问自己:这个递归有多深?栈空间够用吗?如果不能尾递归优化,我应该怎么改写?
参考资料
- Clinger, W. D. (1998). Proper Tail Recursion and Space Efficiency. ACM SIGPLAN Notices.
- Eli Bendersky. Stack frame layout on x86-64. https://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64/
- Gustavo Duarte. Tail Calls, Optimization, and ES6. https://manybutfinite.com/post/tail-calls-optimization-es6/
- Guido van Rossum. Tail Recursion Elimination. http://neopythonic.blogspot.com/2009/04/tail-recursion-elimination.html
- System V AMD64 ABI. https://gitlab.com/x86-psABIs/x86-64-ABI
- Microsoft x64 calling convention. https://learn.microsoft.com/en-us/cpp/build/x64-calling-convention
- Rust RFC 0601: Replace
bewithbecome. https://rust-lang.github.io/rfcs/0601-replace-be-with-become.html - Go Runtime: Contiguous Stacks. https://docs.google.com/document/d/1wAaf1rYoM4S4gtnPh0zOlGzWtrZFQ5suE8qr2sD8uWQ/
- Python 3.14 Tail-call Interpreter. https://blog.nelhage.com/post/cpython-tail-call/
- The Revised⁷ Report on the Algorithmic Language Scheme. https://standards.scheme.org/official/r7rs.pdf