你打开Chrome的任务管理器,发现一个简单的网页竟然占用了多个进程——浏览器进程、渲染进程、GPU进程、网络服务进程,甚至还有扩展进程。这不是Chrome"吃内存",而是现代浏览器架构的必然结果。
2018年,Chrome团队在Chrome 67中默认启用了Site Isolation(站点隔离)功能,将不同网站的iframe放入独立的渲染进程。这个决策源于Spectre漏洞的发现——攻击者可以通过侧信道攻击读取同一进程内其他网站的数据。进程隔离成为最有效的安全边界。
但要理解为什么浏览器需要如此复杂的架构,我们必须从渲染管道说起。
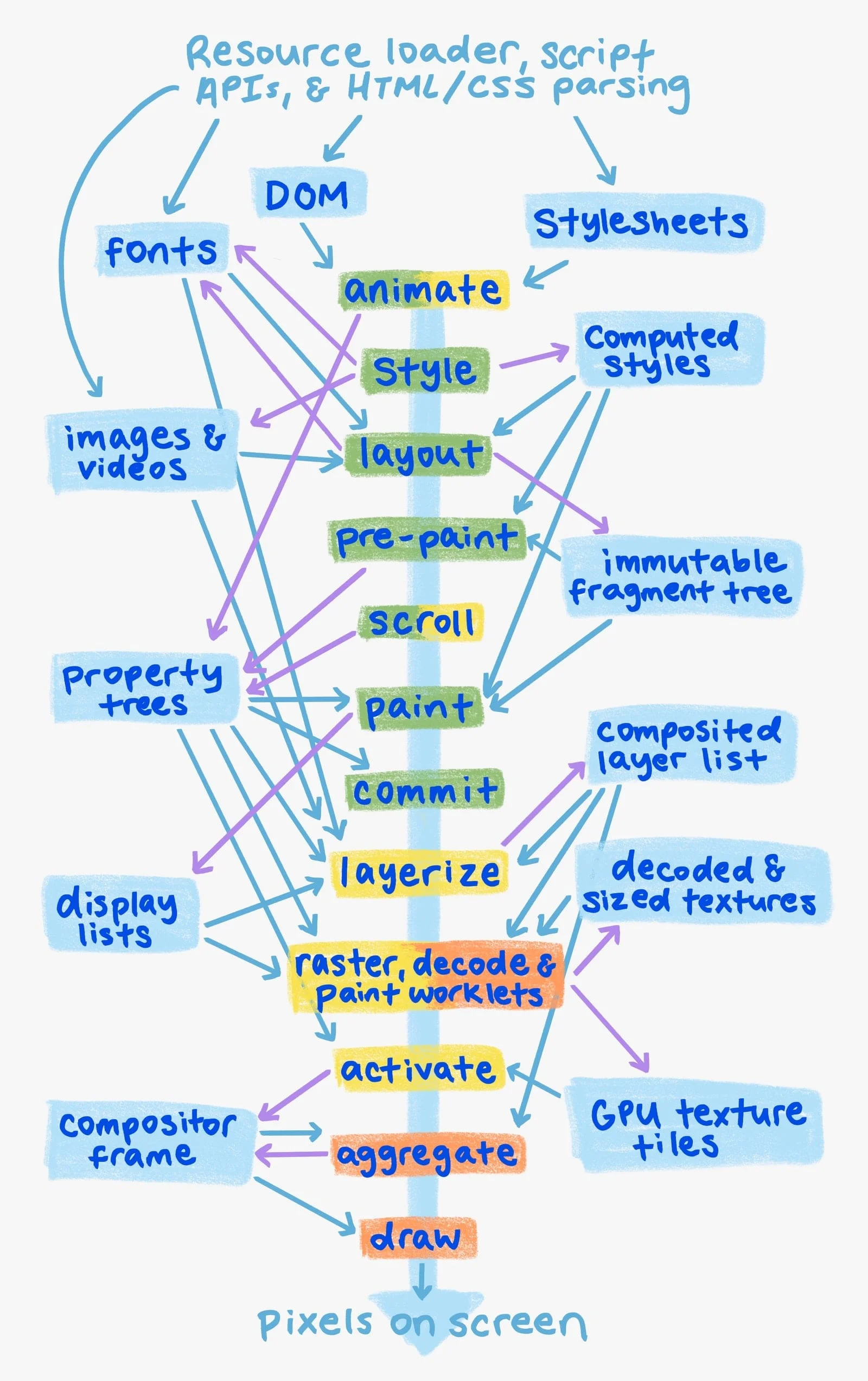
从DOM到像素:渲染管道的完整流程
当你访问一个网页时,浏览器需要完成一系列复杂的步骤才能将代码转换为屏幕上的像素。这个流程被称为渲染管道(Rendering Pipeline)。
图片来源: developer.chrome.com
{kind=link}
Chrome的RenderingNG架构将渲染过程分解为以下关键阶段:
1. 样式计算(Style)
浏览器将CSS规则应用到DOM元素上,计算每个元素的最终样式。这个阶段需要处理CSS选择器匹配、样式继承和层叠规则。CSS选择器的复杂度直接影响这个阶段的性能——后代选择器(div p)比直接子选择器(div > p)更昂贵,因为前者需要遍历整个祖先链。
2. 布局(Layout)
布局阶段计算每个元素的确切位置和大小。这是一个递归过程:父元素的大小可能依赖于子元素,子元素的位置又依赖于父元素。布局的代价与DOM树的复杂度直接相关,更重要的是,布局几乎总是针对整个文档进行的——即使只改变一个元素,浏览器也可能需要重新计算整个页面的布局。
3. 预绘制(Pre-paint)
计算属性树(Property Trees),确定哪些内容需要被重绘。属性树是RenderingNG引入的关键数据结构,它将视觉效果(如transform、opacity、filter)与布局分离,使得动画和滚动可以在合成线程独立处理。
4. 绘制(Paint)
生成显示列表(Display List),记录如何将元素绘制到屏幕上。注意,这个阶段并不实际绘制像素,而是生成一系列绘制指令。这些指令会被发送到GPU进程进行光栅化。
5. 合成(Composite)
将绘制指令分解为多个合成层(Composited Layers),每个层可以独立光栅化和动画。这是GPU加速的关键——浏览器将页面分解为多个"层",每个层作为GPU纹理独立处理。
6. 光栅化(Raster)
将显示列表转换为实际的像素数据。现代Chrome支持两种光栅化方式:软件光栅化(在CPU上完成)和GPU光栅化(直接在GPU上执行Skia指令)。
7. 绘制(Draw)
GPU将所有合成层组合成最终的屏幕图像。这个阶段在GPU进程的viz组件中完成。
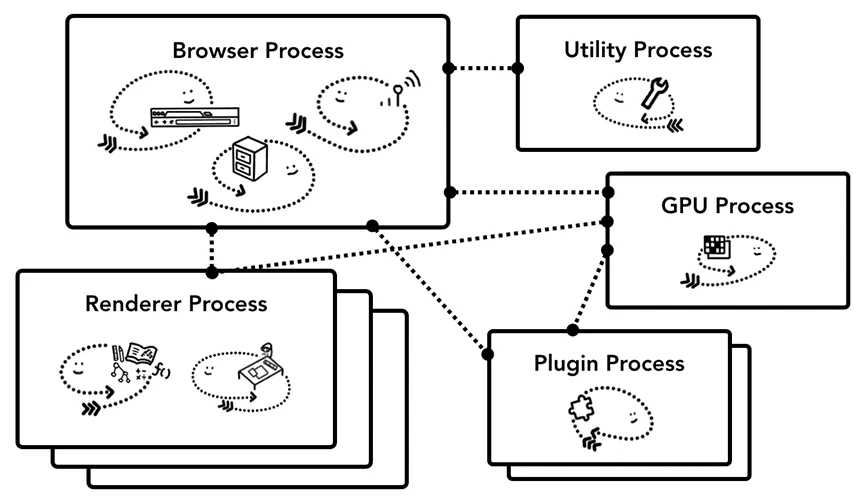
多进程架构:为什么一个页面需要这么多进程?
打开Chrome的任务管理器,你会看到多个进程。这不是设计缺陷,而是精心设计的安全和性能架构。
图片来源: developer.chrome.com
{kind=link}
浏览器进程(Browser Process):控制浏览器的"chrome"部分——地址栏、书签、前进后退按钮。更重要的是,它处理网络请求和文件访问,这些是特权操作。
渲染进程(Renderer Process):负责网页内容的渲染、动画、滚动和输入路由。这是最不信任的部分,运行在沙箱中,被剥夺了访问文件系统和网络的权限。
GPU进程(GPU Process):处理所有GPU操作。独立的GPU进程有两个关键原因:一是GPU驱动崩溃不会导致整个浏览器崩溃;二是安全隔离,GPU API(如Vulkan)需要更宽松的沙箱。
Viz进程:负责聚合来自多个渲染进程的合成器帧。在Site Isolation之前,一个页面只有一个渲染进程,合成可以在渲染进程内完成。现在,一个页面可能有多个跨站iframe运行在不同的渲染进程中,需要一个中央协调者。
Site Isolation的安全边界
2018年,Chrome 67在桌面平台(Windows、Mac、Linux、Chrome OS)默认启用了Site Isolation。这是一个多年的工程努力,改变了iframe之间的通信方式,甚至影响了DevTools和页面内搜索的实现。
Site Isolation的核心思想是:每个站点(site)运行在独立的渲染进程中。站点定义为eTLD+1(有效顶级域名+一级子域名)。例如,a.example.com和b.example.com属于同一站点,而example.com和attacker.com属于不同站点。
这种隔离提供了强安全保证:
- 同源策略在进程边界强制执行
- Spectre攻击无法读取跨进程内存
- 渲染进程被攻陷不会影响其他站点
代价是内存消耗增加约10-13%——每个渲染进程都有独立的V8引擎实例和Blink渲染引擎副本。Chrome通过动态调整进程数量来平衡安全性和资源消耗。
重排与重绘:性能优化的核心战场
理解渲染管道后,重排(Reflow/Layout)和重绘(Repaint)的概念就清晰了。
重排发生在元素的几何属性变化时:width、height、padding、margin、left、top等。重排是昂贵的,因为它需要重新计算整个文档的布局。
重绘发生在元素的视觉样式变化但不影响布局时:color、background-color、visibility等。重绘比重排便宜,但仍需要重新生成显示列表。
布局抖动(Layout Thrashing)
更危险的是强制同步布局(Forced Synchronous Layout),也称布局抖动。
// 危险:在循环中交替读写布局属性
for (let i = 0; i < paragraphs.length; i++) {
paragraphs[i].style.width = box.offsetWidth + 'px';
}
这段代码的问题在于:每次迭代,JavaScript先读取offsetWidth(触发布局),然后写入style.width(标记布局脏位)。下一次迭代再次读取offsetWidth时,浏览器必须先完成布局才能返回正确的值。
正确的做法是先批量读取,再批量写入:
// 先读取
const width = box.offsetWidth;
// 再写入
for (let i = 0; i < paragraphs.length; i++) {
paragraphs[i].style.width = width + 'px';
}
浏览器的事件循环设计使得布局延迟计算成为可能:JavaScript执行时不进行渲染,DOM变化在任务完成后统一处理。但某些属性和方法会强制浏览器立即执行布局:
| 触发布局的属性/方法 | 说明 |
|---|---|
offsetTop, offsetLeft, offsetWidth, offsetHeight |
返回元素的布局位置/尺寸 |
scrollTop, scrollLeft, scrollWidth, scrollHeight |
滚动相关 |
clientTop, clientLeft, clientWidth, clientHeight |
元素内容区域 |
getBoundingClientRect() |
返回布局矩形 |
getComputedStyle() |
返回计算样式(某些情况) |
scrollIntoView() |
滚动元素到视口 |
GPU加速合成:为什么transform动画如此流畅?
你可能注意到,使用transform: translateX()做动画比改变left属性流畅得多。这涉及渲染管道中的一个关键优化:合成层(Compositing Layer)。
当元素满足以下条件之一时,浏览器会为其创建独立的合成层:
- 拥有3D或透视CSS变换
- 使用
<video>或<canvas>(WebGL/加速2D上下文) - CSS动画或过渡中使用
opacity或transform - 使用
will-change属性 position: fixed(某些情况)- 拥有合成层的后代元素
合成层的优势在于:动画可以完全在合成线程完成,不需要主线程参与。
合成线程的工作
Chrome的线程架构将渲染工作分为两个关键线程:
主线程(Main Thread):运行JavaScript、处理DOM、执行布局和绘制。这是最繁忙的线程,也是性能瓶颈的常见来源。
合成线程(Compositor Thread):处理输入事件、滚动、CSS动画,协调光栅化和绘制任务。
当用户滚动页面时,合成线程可以独立处理滚动,更新属性树中的滚动偏移,生成新的合成器帧——完全不需要主线程参与。这就是为什么即使主线程被阻塞,页面仍然可以流畅滚动。
但有一个例外:触摸事件监听器。如果页面注册了touchstart或touchmove事件监听器,合成线程必须将事件发送到主线程,等待JavaScript处理完毕后才能决定是否滚动。这就是为什么Chrome建议使用passive: true选项:
document.addEventListener('touchmove', handler, { passive: true });
这告诉浏览器:监听器不会调用preventDefault(),合成线程可以立即开始滚动。
will-change的双刃剑
will-change属性可以提前告知浏览器元素将发生变化,触发合成层创建:
.animated-element {
will-change: transform, opacity;
}
但这不是性能万灵药。每个合成层都需要独立的GPU纹理,消耗显存。过多的合成层会导致:
- GPU内存压力增大
- 合成阶段开销增加(需要遍历更多层)
- 在低端设备上可能导致崩溃
Chrome的Layer Squashing机制会尝试将重叠的非直接合成原因的层合并到单个纹理中,但手动创建过多合成层仍会绕过这个优化。
事件循环:JavaScript执行的隐秘规则
渲染发生在事件循环的特定时机。理解事件循环对于性能优化至关重要。
sequenceDiagram
participant MT as 主线程
participant MQ as 宏任务队列
participant mQ as 微任务队列
participant R as 渲染
MT->>MQ: 从宏任务队列取一个任务
MT->>MT: 执行同步代码
MT->>mQ: 执行所有微任务
MT->>R: 更新渲染(如果需要)
MT->>MQ: 等待下一个宏任务
宏任务(Macrotask):包括script整体代码、setTimeout、setInterval、setImmediate(Node.js)、I/O、UI渲染。
微任务(Microtask):包括Promise.then/catch/finally、queueMicrotask()、MutationObserver。
关键规则:每个宏任务之后,渲染之前,执行所有微任务。这意味着微任务可以在当前帧渲染前执行,而setTimeout(..., 0)的回调要等到下一个宏任务。
console.log('script start');
setTimeout(() => console.log('timeout'), 0);
Promise.resolve().then(() => console.log('promise'));
console.log('script end');
// 输出顺序:
// script start
// script end
// promise
// timeout
requestAnimationFrame的回调在渲染前、微任务之后执行。这使得它成为动画更新的最佳时机:
function animate() {
// 更新动画状态
element.style.transform = `translateX(${x}px)`;
requestAnimationFrame(animate);
}
requestAnimationFrame(animate);
V8引擎:JavaScript的执行管道
渲染管道之外,V8引擎的执行管道同样复杂。V8使用多层JIT编译策略来平衡启动速度和峰值性能。

图片来源: v8.dev
{kind=link}
1. 解释器(Ignition)
所有JavaScript代码首先被编译为字节码,由Ignition解释执行。这是最快的启动方式,但执行速度最慢。
2. 基线编译器(Sparkplug)
2021年引入,快速将字节码编译为机器码,几乎不进行优化。编译速度极快(亚毫秒级),生成的代码比解释器快约40%。
3. 中级优化编译器(Maglev)
2023年在Chrome 117引入,填补了Sparkplug和TurboFan之间的空白。Maglev使用SSA(静态单赋值)中间表示,根据运行时类型反馈生成专门化代码。
编译时间约为Sparkplug的10倍,但只有TurboFan的1/10。在Speedometer基准测试中,添加Maglev带来了约10%的性能提升。
4. 顶级优化编译器(TurboFan)
基于"海节点"(Sea of Nodes)IR的优化编译器,执行激进的优化:逃逸分析、循环不变量外提、内联缓存等。编译时间最长,但生成最高质量的代码。
类型反馈与去优化
JIT编译的关键是投机优化。编译器假设变量类型不变,生成专门化代码:
function add(a, b) {
return a + b;
}
// 如果a和b总是整数
for (let i = 0; i < 10000; i++) {
add(i, i + 1); // 编译器假设add总是处理整数
}
// 突然传入字符串
add('hello', 'world'); // 去优化!回退到解释器或重新编译
类型改变触发去优化,这是JIT性能不稳定的主要来源。保持类型稳定是编写高性能JavaScript的关键。
Orinoco:并行与并发垃圾回收
V8的垃圾回收器代号Orinoco,实现了三种关键技术的组合:

图片来源: v8.dev
{kind=link}
并行GC(Parallel):主线程和辅助线程同时工作,缩短暂停时间。仍是"Stop-the-World",但工作被分摊。
增量GC(Incremental):将GC工作分成小段,穿插在主线程任务之间。不减少总工作量,但让主线程保持响应。
并发GC(Concurrent):辅助线程完全在后台执行GC工作,主线程自由执行JavaScript。这是最难实现的,因为JavaScript执行期间对象图可能随时变化。
现代V8在Scavenger(新生代GC)中使用并行技术,在Major GC(老生代GC)中使用并发标记和并行压缩。结果是:主线程暂停时间大幅缩短,Gmail在空闲时可以减少45%的JavaScript堆内存。
关键渲染路径优化实践
理解渲染管道后,优化策略就清晰了。
减少渲染阻塞资源
CSS默认是渲染阻塞的:浏览器必须等待所有CSS下载和解析完成才能渲染。JavaScript默认是解析阻塞的:脚本执行会阻止HTML解析。
优化策略:
<!-- 异步加载非关键JavaScript -->
<script src="analytics.js" async></script>
<!-- 延迟执行非关键JavaScript -->
<script src="app.js" defer></script>
<!-- 预加载关键资源 -->
<link rel="preload" href="critical-font.woff2" as="font" crossorigin>
<!-- 预连接到关键域名 -->
<link rel="preconnect" href="https://cdn.example.com">
async脚本在下载完成后立即执行,不保证顺序。defer脚本在DOM解析完成后、DOMContentLoaded事件前按顺序执行。
优化关键渲染路径
关键渲染路径(Critical Rendering Path)是从收到HTML到首次渲染的路径。目标是最小化首次渲染时间:
- 最小化关键资源:内联关键CSS,延迟加载非关键CSS
- 最小化关键字节数:压缩、最小化CSS和JavaScript
- 最小化关键路径长度:减少往返次数
诊断工具
Chrome DevTools的Performance面板可以完整记录渲染管道的每个阶段:
- Recalculate Style:样式计算时间
- Layout:布局时间
- Paint:绘制时间
- Composite:合成时间
更重要的是,DevTools可以识别强制同步布局,标记为"Layout Shift"或"Forced Reflow"。
写在最后
浏览器的渲染管道是一个精妙的工程设计,每个阶段都经过深思熟虑的优化:
- 多进程架构提供安全隔离,代价是内存开销
- 合成线程独立于主线程,保证滚动和动画的流畅性
- 多层JIT编译平衡启动速度和峰值性能
- 并发垃圾回收最小化主线程暂停
理解这些原理,才能写出真正高性能的Web应用。性能优化不是魔法,而是对系统行为的深刻理解和对权衡的明智选择。
参考资料
- RenderingNG architecture - Chrome for Developers
- Inside look at modern web browser - Chrome for Developers
- Avoid large, complex layouts and layout thrashing - web.dev
- Maglev - V8’s Fastest Optimizing JIT - V8.dev
- Trash talk: the Orinoco garbage collector - V8.dev
- Event loop: microtasks and macrotasks - JavaScript.info
- GPU Accelerated Compositing in Chrome - Chromium.org
- Site Isolation Design Document - Chromium.org
- Mitigating Spectre with Site Isolation in Chrome - Google Security Blog
- Critical rendering path - MDN
- Assist the browser with resource hints - web.dev