1953年1月,IBM研究员Hans Peter Luhn在一篇内部备忘录中提出了一个看似简单的想法:把数据放进"桶"里以加速查找。他当时的目的是解决一个日益紧迫的问题——科学文献的数量正以指数级增长,人工索引已经跟不上节奏。Luhn可能没想到,这个为了信息检索而设计的"桶"方案,会在七十年后成为计算机科学中最核心的数据结构之一。
今天,哈希表几乎无处不在:从编程语言的字典类型到数据库索引,从编译器的符号表到浏览器的缓存系统。但就在这样一个看似成熟的技术领域,过去十年却发生了一场静悄悄的革命。Google的Swiss Table、Facebook的F14、以及各种改进型开放寻址算法的出现,让哈希表的性能边界被重新定义。
两条分叉的道路:链表法与开放寻址
当两个不同的键被哈希函数映射到同一个位置时,冲突就发生了。这是哈希表设计中最核心的问题。解决冲突的方案经过七十年的演化,形成了两大主要流派。
链表法:简单但不简单
链表法(Chaining)是最直观的方案:每个桶(bucket)存储一个链表,哈希到同一个位置的所有元素都挂在这个链表上。查找时,先定位到桶,再遍历链表找到目标元素。
这个方案的优势显而易见:实现简单,删除操作直接,对哈希函数的质量要求相对宽松。但链表法有一个致命的弱点——缓存不友好。链表节点在内存中分散分布,每次跳转都可能引发缓存未命中。在现代CPU上,一次缓存未命中的代价大约是100-300个CPU周期,而一次成功的L1缓存命中只需要4个周期左右。
Java的HashMap是链表法的典型代表。从Java 8开始,当链表长度超过8时,会将链表转换为红黑树,将最坏情况的查找复杂度从O(n)降低到O(log n)。这是一个经典的工程权衡:用更复杂的数据结构换取更稳定的最坏情况性能。
开放寻址:缓存友好的代价
开放寻址(Open Addressing)采取了完全不同的策略:所有元素都存储在主数组中,冲突时按照某种规则寻找下一个可用位置。这种方案的缓存效率极佳——数据紧密排列在连续内存中,一次缓存行加载(通常64字节)可以同时访问多个元素。
但开放寻址有自己的困境。首先是删除操作的复杂性:删除一个元素后,不能简单地把位置标记为空,因为后续查找可能需要"跨过"这个位置继续探测。传统方案是使用墓碑标记(tombstone),但这会污染表格,降低查找效率。其次是聚类问题:当多个元素哈希到相近位置时,它们会相互"挤压",形成连续的占用区域,进一步增加后续插入的冲突概率。
线性探测:最简单但不完美
开放寻址最基础的形式是线性探测(Linear Probing):当位置i被占用时,依次检查i+1、i+2、i+3…直到找到空位。这个方案有一个令人惊讶的特性——它比更"聪明"的探测策略(如二次探测、双重哈希)在实际中往往更快。
原因仍然是缓存。线性探测沿着内存顺序访问,能够最大化利用缓存预取。而二次探测和双重哈希的跳跃式访问模式,会打乱缓存的预期。Knuth在《计算机程序设计艺术》中早已指出,线性探测的平均探测长度确实比其他方案略长,但每次探测的代价却更低。
但线性探测有一个明显的缺陷:主聚类(Primary Clustering)。当表格变得拥挤时,连续占用的区域会不断扩大,形成"交通堵塞"。想象一个高速公路上的事故现场:最初只有一辆车,但随着时间推移,后面的车越排越多,形成一个不断增长的拥堵区域。
Robin Hood:劫富济贫的探测长度
1986年,滑铁卢大学的Pedro Celis在其博士论文中提出了一种名为Robin Hood Hashing的技术。它的核心思想极其简洁:在探测过程中,如果遇到一个"更幸运"的元素(探测长度更短),就和它交换位置,继续为原元素寻找新家。
这个"劫富济贫"的策略产生了一个奇妙的效果——它极大地降低了探测长度的方差。普通开放寻址中,大多数元素的探测长度很短,但少数不幸的元素可能需要探测几十次。Robin Hood Hashing通过重新分配"运气",让所有元素的探测长度趋于平均。
方差为什么重要?在现代CPU上,探测长度从1增加到3可能只增加几个周期的开销(因为数据仍在同一缓存行中),但探测长度超过缓存行容量后,每次额外探测都可能触发新的缓存未命中。Robin Hood Hashing将最大探测长度控制在约6次左右(负载因子0.9时),这意味着绝大多数查找都能在1-2个缓存行内完成。
Robin Hood Hashing还有一个优雅的特性:查找不存在的元素时,可以提前终止。因为所有元素的探测长度都被"压平",一旦当前探测长度超过了表格中已知的最长探测长度,就可以确定目标不存在。这个特性解决了开放寻址的老大难问题——查找失败时的长探测链。
Cuckoo:最坏情况的保证
2001年,Rasmus Pagh和Flemming Friche Rodler提出了Cuckoo Hashing,它提供了一个传统哈希表难以企及的保证:最坏情况下O(1)的查找时间。
Cuckoo Hashing使用两个独立的哈希函数,每个元素有两个可能的位置。查找时只需检查这两个位置,复杂度严格为O(1)。插入时,如果两个位置都被占用,就"踢出"其中一个元素,让被踢出的元素去自己的另一个候选位置。这个过程可能持续多轮,像布谷鸟把其他鸟蛋推出巢穴一样。
但Cuckoo Hashing的代价在于插入性能和空间效率。为了保证插入成功率,负载因子通常需要控制在50%以下。当插入触发循环时,整个表格需要重新哈希。在实践中,Cuckoo Hashing的查找性能比线性探测慢约20-30%,因为它通常需要两次独立的内存访问(检查两个位置),而线性探测通常只需一次。
尽管如此,Cuckoo Hashing在特定场景下仍有价值。当系统需要严格的实时响应保证时(例如高频交易系统),最坏情况的确定性比平均性能更重要。TikTok的推荐系统就使用Cuckoo Hashing来解决嵌入表冲突问题,保证不同概念不会被映射到相同的向量。
Swiss Table:SIMD的革命
2017年,Google在CppCon上展示了Swiss Table,随后将其开源为Abseil库的一部分。Swiss Table代表了哈希表设计的一次范式转变——从优化探测策略转向优化探测实现。
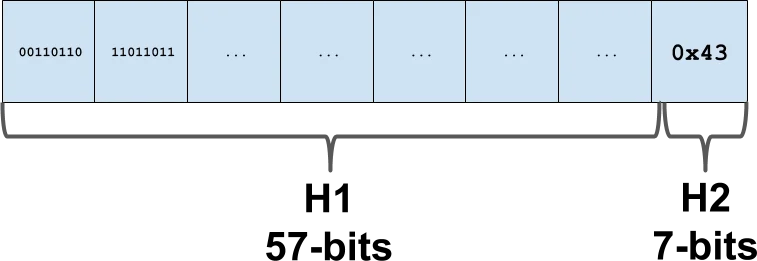
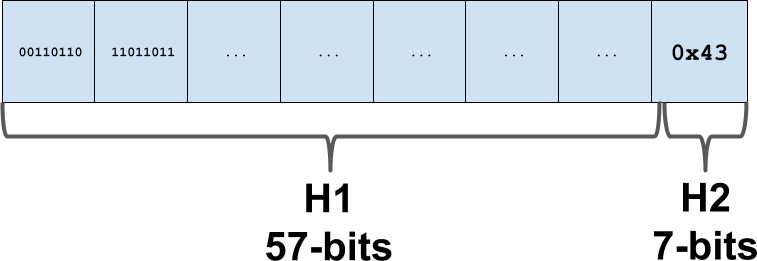
Swiss Table的核心创新是控制字节(Control Bytes)。每个槽位额外存储一个字节的元数据,包含两部分信息:一个控制位表示槽位状态(空、已删除或已占用),以及7位的哈希指纹(H2)。查找时,首先用SIMD指令并行比较16个控制字节,快速筛选出可能匹配的槽位。
图片来源: abseil.io
{kind=link}
Swiss Table将64位哈希值分为两部分:H1(57位)用于定位槽位组,H2(7位)存储在控制字节中用于快速筛选。
这个设计的精妙之处在于:一次SIMD比较可以在几个CPU周期内完成16个位置的初步筛选。即使表格中有大量元素,真正需要进行的完整键值比较也非常少——只有当7位哈希指纹匹配时才需要。由于哈希指纹有128种可能,随机碰撞的概率只有约0.8%。
Swiss Table的另一个重要特性是其探测策略。它使用二次探测的变体,但探测步长以"组"(Group,通常16个槽位)为单位增长:首先检查当前组,然后跳过1个组,再跳过2个组,然后3个组…这个模式与表格的2的幂次大小完美配合,保证每个槽位都会被恰好访问一次。
F14:Facebook的14路探测
2019年,Facebook开源了F14哈希表,作为其Folly库的一部分。F14的名称来源于其核心设计:每个块(Chunk)存储14个键,使用向量化指令(SSE2或NEON)并行过滤。
F14与Swiss Table的设计理念相似——都使用元数据和SIMD来加速查找——但F14采取了不同的权衡。它的负载因子上限是12/14(约85.7%),在这个负载下,平均探测长度仅为1.04。这意味着超过99%的查找能在前3个块内完成。
F14提供了三种存储策略,针对不同的键值大小和使用模式:
- F14ValueMap:值直接存储,适合小对象
- F14NodeMap:单独分配节点,适合大对象,提供引用稳定性
- F14VectorMap:使用紧凑的向量存储,内存效率最高
Facebook的工程团队在生产环境中进行了广泛测试,发现F14在大多数场景下都比他们之前使用的哈希表更快且内存效率更高。
语言的抉择
不同编程语言对哈希表的实现选择,反映了不同的设计哲学和使用场景。
Java:链表法的坚守
Java的HashMap始终坚持链表法。从Java 8开始,当桶内元素超过8个时,链表会转换为红黑树。这个设计体现了Java的一贯哲学:优先考虑最坏情况的稳定性,接受一定的平均情况开销以换取可预测的行为。
这个选择有其合理性。在企业级应用中,可预测的性能往往比极致的速度更重要。红黑树的最坏情况是O(log n),而开放寻址的最坏情况理论上可能退化到O(n)。
Python:开放寻址的探索
Python的dict使用开放寻址,探测策略采用一种伪随机序列。Python 3.3之前,dict在扩容时会重新计算所有键的哈希值;从3.3开始,哈希值被缓存,扩容只需重新分配空间。
Python的选择反映了其动态类型的特性:键的比较操作可能很昂贵(例如比较两个长字符串),因此减少比较次数比减少探测次数更重要。开放寻址让数据紧密排列,内存效率高,缓存友好。
Rust:Swiss Table的拥抱
Rust的HashMap在2019年切换到了基于Swiss Table的hashbrown实现。这是一个相对激进的选择——Swiss Table是一个相当新的设计,而且要求哈希函数具有良好的扩散性。
Rust的选择体现了其对性能的执着。在官方博客中,Rust团队指出hashbrown将HashMap的查找速度提升了约25-40%,内存使用也有所降低。
Go:桶与溢出链的折中
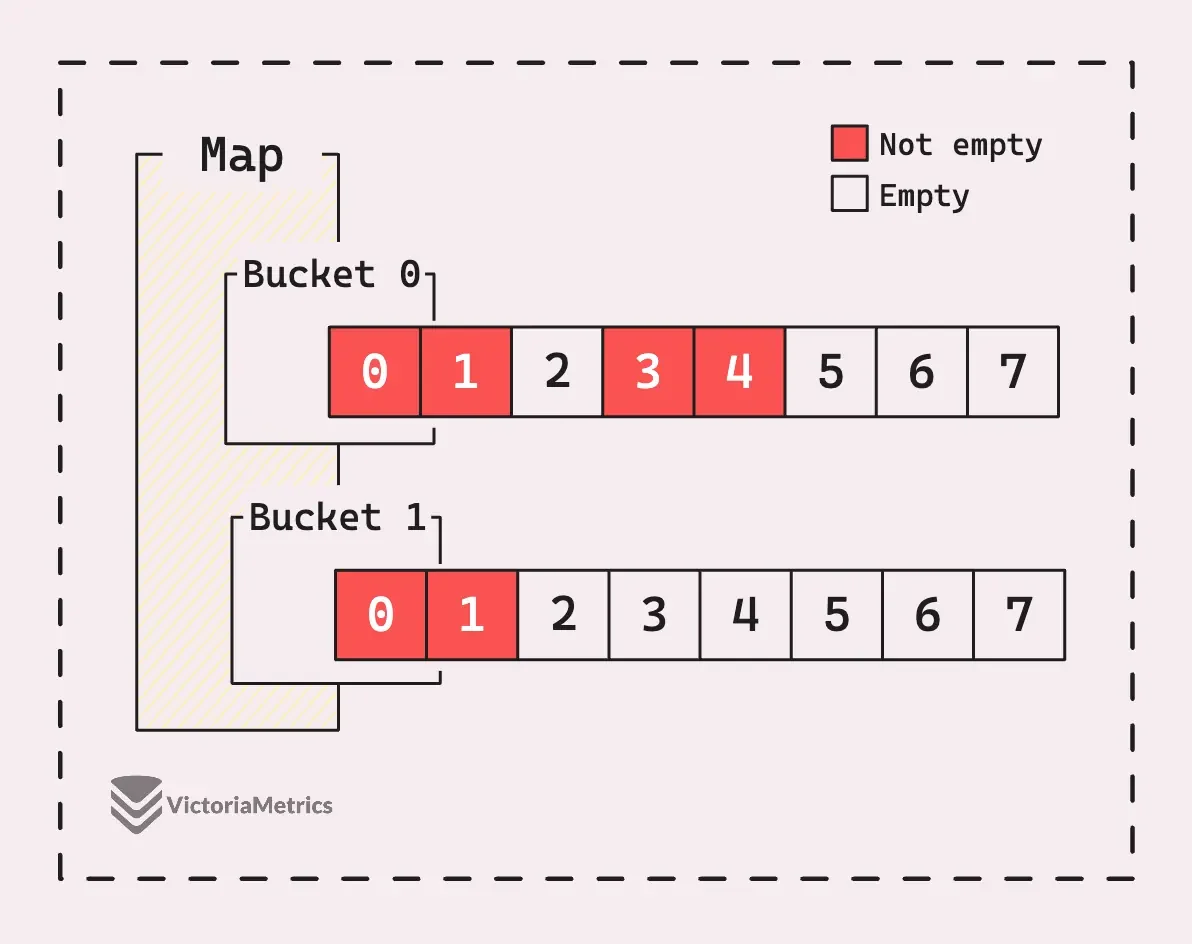
Go语言的map实现了一种混合策略:主数组由固定大小的桶组成(每个桶存储8个键值对),冲突时通过溢出指针链接到额外的桶。这个设计介于链表法和开放寻址之间:桶内使用开放寻址,桶间使用链表。
Go的负载因子阈值是6.5(每个桶平均6.5个元素),这是根据实际基准测试确定的值。Go团队发现,超过这个值后,溢出桶的数量会急剧增加,导致性能下降。
图片来源: victoriametrics.com
{kind=link}
Go语言的map结构:每个桶存储8个键值对,哈希到同一个桶的元素按顺序存储在桶内槽位中。
工程中的权衡
哈希表设计没有银弹。每一种选择都是在不同维度上的权衡。
负载因子:空间与时间的博弈
负载因子是哈希表最基础的设计参数。更高的负载因子意味着更高的空间效率,但也意味着更多的冲突和更长的探测链。
传统开放寻址的负载因子通常不超过70%。但现代设计打破了这一限制:Swiss Table可以安全地运行在87.5%的负载下(7/8),F14可以运行在85.7%(12/14),Robin Hood Hashing甚至可以在90%以上仍保持良好性能。
这背后的原因是这些现代设计极大地降低了探测长度的方差。当最坏情况被控制在可接受范围内时,就可以安全地提高负载因子。
删除操作:墓碑的艺术
删除是开放寻址哈希表中最棘手的操作。最简单的方案是使用墓碑标记:删除元素时不真正清空位置,而是标记为"已删除"。查找时跳过墓碑继续探测。
但墓碑会累积,降低查找效率。当墓碑比例过高时,表格需要重新整理。现代哈希表采用了更聪明的策略:
Swiss Table的删除策略非常优雅:只有当被删除元素位于一个"密集区域"(周围WIDTH个槽位都是FULL或DELETED状态)时,才使用墓碑;否则直接清空。由于密集区域在合理负载因子下很少见,墓碑的使用率极低。
Robin Hood Hashing可以采用后移删除(Backshift Deletion):删除元素后,将后续元素依次前移,填补空缺。由于Robin Hood的特性,这个操作通常只涉及少量元素,且可以完全消除墓碑。
哈希函数:被忽视的关键
哈希表性能的关键往往不是表格结构本身,而是哈希函数的质量。一个糟糕的哈希函数可以把最好的表格设计变成灾难。
Swiss Table对哈希函数有严格要求:需要有良好的雪崩效应(输入的微小变化导致输出的巨大变化),以及均匀的分布。Google专门为Abseil设计了新的哈希框架,确保这些特性。
历史上,哈希函数的设计往往被低估。著名的HashDoS攻击利用弱哈希函数的特性,精心构造输入使哈希表退化为线性查找,导致服务拒绝。从那以后,编程语言普遍加强了对哈希函数安全性的关注。
尾声:持续演进的技术
哈希表的故事远未结束。2022年,一篇题为《Analyzing Vectorized Hash Tables Across CPU Architectures》的论文系统分析了向量化哈希表在不同CPU架构上的表现,发现最优设计因架构而异。ARM的NEON指令集与x86的SSE/AVX有不同的特性,需要不同的优化策略。
GPU上的哈希表是另一个活跃的研究领域。NVIDIA的研究人员开发了专门针对GPU并行特性的哈希表设计,在百万级并发操作下实现了前所未有的吞吐量。
七十年前,Hans Peter Luhn在IBM的实验室里思考如何加速信息检索。今天,他的"桶"思想已经演化为无数种变体,适应着从嵌入式设备到云计算的各种场景。这个演进过程告诉我们:简单的设计往往蕴含着深刻的智慧,但对极致性能的追求会不断推动我们重新审视每一个细节。
哈希表的设计,本质上是空间、时间、实现复杂度这三者之间的永恒权衡。没有完美的解决方案,只有在特定场景下的最优选择。理解这些权衡,才能在面对具体问题时做出明智的决策。
参考来源
- Pagh, R., & Rodler, F. F. (2001). Cuckoo Hashing. European Symposium on Algorithms.
- Abseil. Swiss Tables Design Notes. https://abseil.io/about/design/swisstables
- Facebook Engineering. Open-sourcing F14 for faster, more memory-efficient hash tables. https://engineering.fb.com/2019/04/25/developer-tools/f14/
- Sylvan, S. Robin Hood Hashing should be your default Hash Table implementation. https://www.sebastiansylvan.com/post/robin-hood-hashing-should-be-your-default-hash-table-implementation/
- IEEE Spectrum. Hans Peter Luhn and the Birth of the Hashing Algorithm. https://spectrum.ieee.org/hans-peter-luhn-and-the-birth-of-the-hashing-algorithm
- Go Blog. Faster Go maps with Swiss Tables. https://go.dev/blog/swisstable
- Ankerl, M. Comprehensive C++ Hashmap Benchmarks 2022. https://martin.ankerl.com/2022/08/27/hashmap-bench-01/
- Wikipedia. Cuckoo hashing. https://en.wikipedia.org/wiki/Cuckoo_hashing
- Wikipedia. Hopscotch hashing. https://en.wikipedia.org/wiki/Hopscotch_hashing
- Wikipedia. Hash table. https://en.wikipedia.org/wiki/Hash_table
- Code Capsule. Robin Hood hashing. https://codecapsule.com/2013/11/11/robin-hood-hashing/
- Code Capsule. Hopscotch hashing. https://codecapsule.com/2013/08/11/hopscotch-hashing/
- Faultlore. Swisstable, a Quick and Dirty Description. https://faultlore.com/blah/hashbrown-tldr/
- Ten Thousand Meters. Python behind the scenes #10: how Python dictionaries work. https://tenthousandmeters.com/blog/python-behind-the-scenes-10-how-python-dictionaries-work/
- Stack Overflow. When and how does HashMap convert the bucket from linked list to red-black trees. https://stackoverflow.com/questions/47921663/
- VictoriaMetrics Blog. Go Maps Explained. https://victoriametrics.com/blog/go-map/
- Knuth, D. E. (1973). The Art of Computer Programming, Volume 3: Sorting and Searching.
- Celis, P. (1986). Robin Hood Hashing. University of Waterloo.
- MIT CSAIL. Hopscotch Hashing. https://people.csail.mit.edu/shanir/publications/disc2008_submission_98.pdf
- Stanford CS. An Overview of Cuckoo Hashing. https://cs.stanford.edu/~rishig/courses/ref/l13a.pdf
- GitHub. rust-lang/hashbrown. https://github.com/rust-lang/hashbrown
- GitHub. google/cwisstable DESIGN.md. https://github.com/google/cwisstable/blob/main/DESIGN.md
- Medium. SwissMap: A smaller, faster Golang Hash Table. https://www.dolthub.com/blog/2023-03-28-swiss-map/
- Stack Overflow. How are Python’s Built In Dictionaries Implemented? https://stackoverflow.com/questions/327311/
- Microsoft DevBlogs. Inside STL: The unordered_map. https://devblogs.microsoft.com/oldnewthing/20230808-00/
- Baeldung. Java HashMap Load Factor. https://www.baeldung.com/java-hashmap-load-factor