2016年3月22日,一个名为Azer Koçulu的程序员删除了他在npm上发布的273个包。其中一个叫left-pad的包只有11行代码,功能简单到令人发指——在字符串左侧填充空格。然而,这个微不足道的包被Babel、React、Webpack等数千个项目依赖。几小时内,全球JavaScript开发者的构建流水线开始大规模崩溃,Facebook、PayPal、Netflix、Spotify等公司的开发团队陷入混乱。
npm公司最终手动恢复了left-pad包,并修改了政策:发布超过24小时且被其他项目依赖的包不能再被删除。但这场灾难揭示了一个更深层的问题:现代软件系统建立在一张极其脆弱的依赖网络上,而这张网络的稳定性依赖于一个在理论上无解的问题。
这个问题的核心,叫做依赖解析。它看起来很简单:给定一组包及其版本约束,找到一组满足所有约束的版本组合。但计算机科学家已经证明,这个问题是NP完全的——意味着在最坏情况下,没有任何已知算法能在多项式时间内解决它。
钻石依赖:简单问题变得无解的起点
理解依赖解析为何困难,需要从一个经典场景说起。
假设你的项目依赖两个库A和B。A需要lodash版本3.x,B需要lodash版本4.x。如果lodash 3.x和4.x的API不兼容,你就遇到了钻石依赖问题。

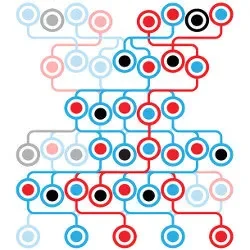
图片来源: research.swtch.com
{kind=link}
这个图示来自Russ Cox 2016年的经典文章。菱形的顶部是你的项目,它依赖B和C两个包。B需要D的1.x版本,C需要D的2.x版本。如果D的两个版本不兼容,整个依赖图就无法满足。
这只是最简单的情况。现实中的依赖图可能涉及数百个包,每个包有数十个版本,每个版本又有复杂的约束条件。这种组合爆炸让问题迅速变得不可收拾。
NP完全性的数学证明
2005年,Roberto Di Cosmo等人在EDOS项目的报告中首次证明:包安装问题是NP完全的。Russ Cox在2016年给出了一个更优雅的证明,核心思想是将3-SAT问题归约到版本选择问题。
3-SAT是布尔可满足性问题的特例,给定一个由若干子句组成的布尔公式,每个子句是三个文字的析取(OR),问是否存在一种变量赋值使得整个公式为真。3-SAT是最早被证明为NP完全的问题之一。
Cox的归约构造如下:
对于3-SAT中的每个变量x,创建一个包X,有两个版本:X:1表示x为真,X:0表示x为假。同一包的不同版本互斥,不能同时安装。
对于3-SAT中的每个子句,例如(x1 ∨ ¬x2 ∨ x3),创建一个包C,有三个版本。C:0依赖X1:1,C:1依赖X2:0,C:2依赖X3:1。这意味着选择C的某个版本,等同于选择使该子句为真的一个文字。
最后,创建一个顶层包F,依赖于所有子句包。如果能找到一组兼容的包版本,就对应3-SAT的一个满足解;反之亦然。
这个证明的精妙之处在于:它只需要包管理器的四个基本假设——包可以有依赖、依赖必须安装、不同版本可以有不同依赖、同一包的不同版本互斥。这些假设几乎是任何有用包管理器的"最低配置"。
SAT求解器:从理论绝望到工程奇迹
NP完全性听起来令人绝望。但Donald Knuth在《计算机程序设计艺术》中写道:“可满足性问题的故事是软件工程的胜利,融合了大量优美的数学。”
现代SAT求解器使用一种叫冲突驱动子句学习(CDCL)的技术,虽然理论上是指数时间,但在实践中表现出惊人的效率。
DPLL:回溯搜索的起点
1961年,Martin Davis、George Logemann和Donald Loveland提出了DPLL算法。这是一种深度优先搜索,核心操作是单元传播:如果一个子句中只有一个文字未被赋值,其余文字都被赋值为假,那么这个文字必须为真。
DPLL(公式F):
while 存在单元子句:
单元传播
if 所有子句满足: return true
if 存在不满足的子句: return false
选择一个未赋值变量x
return DPLL(F ∧ x) or DPLL(F ∧ ¬x)
DPLL的时间复杂度在最坏情况下是O(2^n),这在理论上没有任何改进。但它引入的单元传播和纯文字消除等技术,成为后续所有改进的基础。
CDCL:从失败中学习
CDCL的关键洞察是:当搜索遇到冲突时,不要简单地回溯,而是从冲突中学到一条新规则(子句),避免未来重复同样的错误。
图片来源: cacm.acm.org
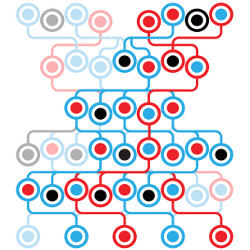{kind=link}
这个图示来自ACM通讯2023年的文章,展示了CDCL的核心机制:构建一个蕴涵图来追踪变量之间的因果关系,当检测到冲突时,通过解析推导出一条新的学习子句,然后执行非时序回溯——直接跳到导致冲突的决策点,而不是按时间顺序逐层返回。
GRASP(1996年)和Chaff(2001年)是CDCL发展史上的里程碑。Chaff引入了VSIDS决策启发式和监视文字数据结构,将SAT求解器的性能提升了几个数量级。这些技术让现代SAT求解器能够处理包含数百万变量的问题。
包管理器的策略分野
面对NP完全问题,不同的包管理系统选择了不同的策略。这些策略代表了工程实践中的不同权衡。
完整求解器:SAT与PubGrub
最直接的方案是将依赖问题编码为SAT问题,调用现有求解器。
0install是早期采用SAT求解器的包管理器。Debian的apt-get默认使用启发式方法,但可以调用外部SAT求解器。Eclipse使用sat4j管理插件依赖。Fedora的DNF和openSUSE的Zypper使用libsolv库,这是一个专门为包管理优化的SAT求解器。
2018年,Dart包管理器的开发者Natalie Weizenbaum提出了PubGrub算法。它的核心思想是借鉴CDCL的技术,但专门针对版本约束问题进行优化。
PubGrub维护一组"不相容性"(incompatibilities),表示哪些版本组合不能共存。当遇到冲突时,它通过逻辑推理推导出新的不相容性,同时记录推导路径用于生成错误信息。
PubGrub的冲突解决示例:
冲突发现:dropdown >=2.0.0 与 icons <2.0.0 不兼容
推导:因为 dropdown >=2.0.0 需要 icons >=2.0.0
记录不相容性:{dropdown >=2.0.0, icons <2.0.0}
继续推导:因为 menu >=1.1.0 需要 dropdown >=2.0.0
记录不相容性:{menu >=1.1.0, icons <2.0.0}
PubGrub的优势不仅在于求解效率,更在于错误信息的质量。当求解失败时,它能生成人类可读的解释:
Because dropdown >=2.0.0 depends on icons >=2.0.0
and root depends on icons <2.0.0,
dropdown >=2.0.0 is forbidden.
And because menu >=1.1.0 depends on dropdown >=2.0.0,
menu >=1.1.0 is forbidden.
So, because root depends on both menu >=1.0.0 and intl >=5.0.0,
version solving failed.
这种清晰的错误归因,让开发者能快速定位问题所在。目前,Poetry、uv、Swift Package Manager、Hex、Bundler都已采用PubGrub。
回溯求解器:简单但有效
最简单的策略是回溯:按优先级(通常是最新的优先)尝试版本,遇到冲突就回退。
pip在2020年发布的20.3版本中引入了新的回溯解析器。在此之前,pip使用的是一种不完整的贪婪算法,可能给出错误的"无解"结论,或者更糟糕地安装不兼容的版本。
新解析器基于resolvelib库,实现了完整的回溯搜索。但回溯有一个致命问题:在最坏情况下,它的时间复杂度是指数级的。
回溯的指数爆炸示例:
假设有n个包,每个包有m个版本。
最坏情况下需要尝试 O(m^n) 种组合。
当n=100, m=10时,这是10^100次尝试。
这就是为什么pip有时候会"卡住"很久——它在探索一个巨大的搜索空间。Cargo(Rust)和早期版本的Bundler也使用回溯算法。
Cargo的特殊之处在于它允许同一包的不同主版本共存。如果一个项目依赖foo 1.x和foo 2.x,Cargo可以同时安装这两个版本,把它们视为不同的包。这大大减少了冲突的可能性,但也带来了一些微妙的问题:如果两个版本的foo共享全局状态,运行时行为可能难以预测。
最小版本选择:回避问题的艺术
Go modules采用了一种截然不同的策略:最小版本选择(MVS)。由Russ Cox设计,MVS的核心规则是:总是选择满足约束的最小版本。
这听起来反直觉——为什么要选择旧版本?但Cox有一个深刻的洞察:如果每个依赖声明都只指定最小版本,那么版本选择就不再是搜索问题,而是一个确定性的图遍历。
MVS算法:
构建依赖列表(包M):
列表 = [M]
for M的每个依赖R:
列表 += 构建依赖列表(R)
return 列表中每个包的最新版本
示例:
A requires B >= 1.2, C >= 1.2
B 1.2 requires D >= 1.3
C 1.2 requires D >= 1.4
最终列表:A, B 1.2, C 1.2, D 1.4
MVS的优雅之处在于它将一个NP完全问题转化为了NL完全问题。NL完全问题的难度远低于NP完全,可以在多项式时间内解决。
但MVS有代价。它不会自动获取最新的bug修复——你需要显式更新依赖约束。Cox认为这是一种特性而非bug:可预测性比自动更新更重要。他在《软件依赖问题》一文中详细阐述了这一设计哲学。
版本调解:速度优先,正确性次要
Maven采用了一种更激进的简化策略:当出现版本冲突时,选择"最近定义"的版本——在依赖树中离根节点最近的那个。
Maven的最近定义规则:
A -> B -> C 1.0
A -> D -> C 2.0
假设B在依赖声明中先于D,则选择C 1.0。
这种策略速度极快——不需要任何搜索,只需要遍历依赖树一次。但代价是正确性:如果一个传递依赖实际需要C 2.0,却被迫使用C 1.0,运行时可能抛出NoSuchMethodError。
Gradle采用"最高版本优先"策略,听起来更安全,但同样可能引入不兼容的版本。如果某个传递依赖明确要求C 1.0(因为C 2.0有breaking change),Gradle会强制使用C 2.0,然后运行时崩溃。
这些策略的共同特点是:快,但可能在运行时爆炸。这在Java生态系统中导致了无数的"依赖地狱"问题。
多版本共存:通过冗余解决问题
npm和Yarn采用了一种独特的策略:允许多个版本共存。
如果包A需要lodash 3.x,包B需要lodash 4.x,npm会在A的node_modules目录下放lodash 3.x,在B的node_modules目录下放lodash 4.x。这样每个包都能得到它需要的版本。
npm的node_modules结构:
node_modules/
├── [email protected]
├── package-a/
│ └── node_modules/
│ └── [email protected]
└── package-b/
└── node_modules/
└── [email protected] (或指向根目录的符号链接)
npm v3引入了"扁平化"(hoisting)优化:如果多个包依赖同一个兼容版本,就把它提升到根目录共享。这减少了磁盘占用,但也带来了新的问题:如果一个包能够访问到它并未声明的依赖(因为被提升到了祖先目录),就可能导致意外行为。
pnpm采用了更严格的方法。它使用内容寻址存储和符号链接,确保每个包只能访问它明确声明的依赖。
pnpm的node_modules结构:
node_modules/
├── .pnpm/
│ ├── [email protected]/node_modules/lodash -> [store]
│ ├── [email protected]/node_modules/lodash -> [store]
│ ├── [email protected]/node_modules/
│ │ ├── package-a -> [store]
│ │ └── lodash -> ../../[email protected]/node_modules/lodash
│ └── [email protected]/node_modules/
│ ├── package-b -> [store]
│ └── lodash -> ../../[email protected]/node_modules/lodash
├── package-a -> .pnpm/[email protected]/node_modules/package-a
└── package-b -> .pnpm/[email protected]/node_modules/package-b
这种结构避免了npm的"幽灵依赖"问题,但代价是更复杂的文件系统布局。
锁文件:冻结时间的艺术
无论采用哪种解析策略,最终结果都需要被记录下来,这就是锁文件的作用。
package-lock.json、yarn.lock、poetry.lock、Cargo.lock——这些文件本质上做同一件事:记录依赖解析的确切结果,包括每个包的精确版本、来源和校验和。
锁文件解决的是可重复性问题。没有锁文件,今天和明天运行npm install可能得到不同的依赖树,因为包作者可能发布了新版本。有了锁文件,只要锁文件存在且完整,构建就是确定性的。
但锁文件本身也有争议。当你更新依赖时,是只更新直接依赖的版本,还是顺带更新所有传递依赖到最新兼容版本?npm默认采用后一种策略(但受semver约束),而Go modules的MVS只更新到必需的最低版本。
性能瓶颈:元数据才是真正的敌人
理论上的时间复杂度固然重要,但在实践中,依赖解析的性能瓶颈往往不在算法本身,而在元数据获取。
pip的新解析器在2020年发布后,许多用户抱怨解析时间过长。问题出在pip需要下载每个候选包的元数据来获取其依赖信息。对于有数千个版本的热门包,这可能意味着数千次网络请求。
uv,一个用Rust编写的Python包管理器,通过几种技术解决了这个问题:
- 并行元数据获取:在解析过程中预先获取可能需要的元数据
- 高效的缓存机制:避免重复的网络请求
- PubGrub算法:相比简单回溯,更少的回溯次数
结果显示,uv比pip快10-100倍,这主要归功于工程优化而非算法改进。
没有万能方案:理解权衡的本质
依赖解析领域不存在完美的解决方案。每一种策略都代表了特定的权衡:
| 策略 | 代表工具 | 优点 | 缺点 |
|---|---|---|---|
| SAT求解 | apt, DNF, libsolv | 完整性保证 | 可能慢;错误信息难懂 |
| PubGrub | Dart pub, uv, Poetry | 完整性保证;清晰错误信息 | 实现复杂 |
| 回溯 | pip, Cargo | 简单;灵活性高 | 可能很慢;最坏情况指数时间 |
| 最小版本选择 | Go modules | 确定性;高效 | 不自动获取最新修复 |
| 版本调解 | Maven, Gradle | 极快 | 可能引入不兼容版本 |
| 多版本共存 | npm, pnpm | 减少冲突 | 磁盘占用;可能的运行时问题 |
理解这些权衡,能帮助你在选择工具和设计依赖策略时做出更明智的决策。
对于应用开发者,关键建议是:
- 始终提交锁文件
- 谨慎使用宽泛的版本范围(如
*或^) - 定期审计依赖,移除不再需要的包
- 理解你的包管理器的默认行为
对于库开发者:
- 遵循语义化版本控制
- 尽量减少依赖
- 当需要breaking change时,考虑提供迁移指南
- 避免在patch版本中添加新依赖
依赖解析问题困扰了我们二十年,从DPLL到CDCL,从简单的回溯到PubGrub,每一步进展都是工程实践与理论研究的结合。NP完全性告诉我们,完美的算法不存在;但工程实践告诉我们,足够好的解决方案一直都在。
下一次当你看到npm install卡在解析依赖时,不妨想想:你的包管理器正在努力解决一个在理论上无解的问题。它能在几秒内给出答案,本身就是一个工程奇迹。
参考文献
- Di Cosmo, R., et al. (2005). “EDOS Deliverable WP2-D2.1: Report on Formal Management of Software Dependencies”
- Cox, R. (2016). “Version SAT” - research.swtch.com/version-sat
- Cox, R. (2018). “Minimal Version Selection” - research.swtch.com/vgo-mvs
- Weizenbaum, N. (2018). “PubGrub: Next-Generation Version Solving”
- Abate, P., et al. (2020). “Dependency Solving Is Still Hard, but We Are Getting Better at It”
- The Silent (R)evolution of SAT - Communications of the ACM, 2023
- Tucker, et al. (2007). “OPIUM: Optimal Package Install/Uninstall Manager”
- npm left-pad incident - Wikipedia