2003年,比利时大选计票系统记录到一个异常数据:某位候选人的得票数比实际多了4096票。这个数字恰好是2的12次方——一次比特翻转。调查最终指向了一个令人不安的嫌疑人:来自太空的宇宙射线。这不是科幻小说的情节,而是半导体世界中最真实的物理约束。
你的计算机内存正在被来自太空的粒子"攻击"。这不是比喻——每一秒钟,来自宇宙深处的高能粒子都在穿过地球大气层,其中一部分会击中你的内存芯片,把0变成1,或者把1变成0。在没有ECC保护的系统上,这些翻转可能被永久地写入你的数据文件。
一个比特的价值:从4096票到卡西尼号
比利时大选的案例并非孤例。1997年发射的卡西尼-惠更斯号探测器携带了两台飞行记录器,每台包含2.5Gbit的商用DRAM内存。由于内置了EDAC(错误检测与纠正)功能,探测器的工程遥测数据详细记录了内存错误的发生情况。
发射后前两年半,卡西尼号报告了几乎恒定的单比特错误率——每天约280次。但在1997年11月6日,错误数量突然激增了四倍以上。这一天,太阳粒子事件被GOES-9卫星探测到。宇宙射线与内存错误之间的因果关系,在距离地球数亿公里的太空中得到了最直接的验证。
图片来源: upload.wikimedia.org
{kind=link}
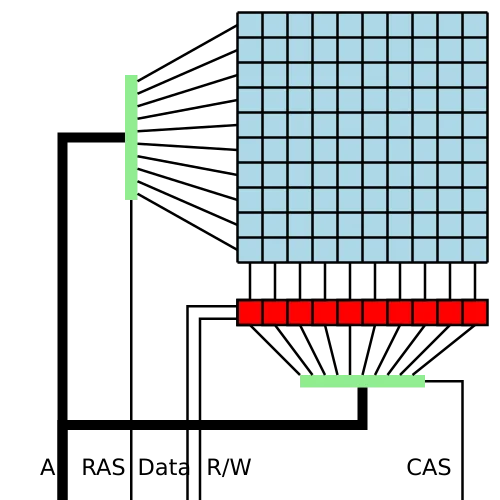
理解内存错误,首先要理解DRAM的工作原理。每个DRAM单元由一个电容和一个晶体管组成。电容充电代表1,放电代表0。这个设计优雅而简单,但有一个致命弱点:电容会自然漏电,必须定期刷新。更重要的是,电容存储的电荷量极小——现代DRAM单元的电容通常只有几个飞法拉(fF),存储的电荷量约为几万个电子。
当一颗来自宇宙射线的高能中子击中硅芯片时,它可能在半导体中产生电离效应,释放出足以改变电容电荷状态的能量。这个过程被称为单粒子翻转(SEU,Single Event Upset),导致的错误被称为软错误——因为它不损坏硬件,只改变数据。
软错误的物理本质:从中子流到临界电荷
IBM的James F. Ziegler在1979年发表了一系列开创性论文,证明宇宙射线是现代电子设备软错误的主要来源。尽管原始的宇宙射线粒子很少直接到达地表,但它们与大气层相互作用产生次级粒子流——其中约95%是高能中子,其余是质子和π介子。
这些中子的特点是:不带电,无法直接干扰电路,但能被原子核俘获并引发核反应,产生带电的次级粒子(如α粒子和氧原子核)。这些带电粒子才是真正翻转内存比特的"凶手"。
中子通量与海拔高度密切相关。以纽约市(北纬40.7°,西经74°,海平面)为参考点,地表的中子通量约为14个中子/cm²/小时。海拔每升高1000米,通量增加约2.2倍。在海拔1.5公里处,中子通量是海平面的3.5倍;在10-12公里的商用飞机巡航高度,通量是海平面的300倍。
一项实验直接测量了海平面和地下深处的软错误率差异。测试装置在海平面测得每个DRAM芯片的软错误率为5950 FIT(Failures In Time,每十亿小时失败次数)。当同一装置被移至地下50英尺的屏蔽室后——那里几乎完全消除了宇宙射线——软错误率降为零。这个实验证明,在消除宇宙射线后,其他来源的软错误微乎其微。
软错误是否发生,取决于一个关键参数:临界电荷(Qcrit)。这是一个电路节点翻转逻辑状态所需的最小电荷扰动量。Qcrit越高,越不容易发生软错误。不幸的是,随着芯片制程缩小和工作电压降低,Qcrit也在不断减小,使得现代芯片更容易受到粒子轰击的影响。
Google的发现:错误率远超预期
2009年,Google发表了一项里程碑式的研究《DRAM Errors in the Wild: A Large-Scale Field Study》,分析了其服务器集群在2.5年内的内存错误数据。这是当时最大规模的内存错误实地研究,结论令人震惊。
研究发现,内存错误率比之前实验室和小规模研究的结果高出数个数量级——每兆比特每十亿小时25000到70000次错误。换算成更直观的单位:大约每1.8小时,每GB内存就会发生一次比特错误。
更重要的是,每年约有8%的DIMM内存模块受到影响。而在整个研究期间,约32%的服务器至少经历过一次内存错误。这个比例远高于之前的预期。
Google的研究还揭示了一个关键洞察:内存错误并非均匀分布。错误数量遵循幂律分布,具体来说是帕累托分布。这意味着少数"问题机器"贡献了绝大多数错误。具体而言,错误最多的前1%服务器贡献了超过97.8%的错误。平均错误率是中位数错误率的55倍——如果只看平均值,会严重高估大多数服务器的错误情况。
Facebook的补充:非DRAM因素不容忽视
2015年,Facebook发布了另一项大规模研究《Revisiting Memory Errors in Large-Scale Production Data Centers》,分析了其整个服务器集群在14个月内的内存错误,数据量达数十亿设备天。
这项研究的一个重要发现是:大多数错误并非源自DRAM芯片本身,而是来自内存控制器和内存通道。在Google的研究中,这类错误可能被归因于DRAM;Facebook的研究通过更精细的分类方法,分离出了这些非DRAM错误。
数据显示,内存控制器(Socket)故障贡献了63.8%的错误,内存通道(Channel)故障贡献了21.2%。这两类故障虽然发生频率低(分别只影响1.34%和1.10%的错误服务器),但一旦发生,会产生大量错误,甚至导致服务器响应中断——本质上是一种拒绝服务攻击。
而传统的DRAM芯片级错误(Bank、Row、Column、Cell和Spurious)只贡献了约15%的错误。其中,“Spurious"错误——随机、不重复的单次错误,通常由宇宙射线等外部事件引起——影响了56.03%的错误服务器,是最常见的错误类型。
Facebook研究还发现了一个令人担忧的趋势:更新的制程节点(以芯片密度为指标)错误率更高。4Gb芯片的错误率是2Gb芯片的1.8倍,而2Gb芯片的错误率是1Gb芯片的2.4倍。这与之前认为"新制程更可靠"的假设相矛盾。
ECC的数学优雅:从汉明码到SEC-DED
面对不可避免的内存错误,工程界早在1950年代就找到了解决方案:纠错码。Richard Hamming在1950年发表的论文中提出了汉明码——一种能够检测并纠正单比特错误的编码方案。
汉明码的核心思想是用校验位来保护数据位。对于64位数据,需要8位校验位(总共72位),形成所谓的(72,64)码。这8位校验位并非随机分布,而是放置在2的幂次位置上(第1、2、4、8、16、32、64位)。
每个校验位负责检查特定位置的奇偶性。例如,第1位校验位检查所有奇数位置;第2位校验位检查第2、3、6、7、10、11…位置。这种设计确保了每个数据位都被多个校验位覆盖,且组合是唯一的。
当发生单比特错误时,会有一组特定的校验位失效。通过检查哪些校验位出错,可以精确定位错误位置并纠正。这就是单错纠正(SEC,Single Error Correction)的原理。
但仅有SEC还不够——如果同时发生两位错误,SEC汉明码会尝试"纠正"到错误的值。为此,业界普遍采用SEC-DED(Single Error Correction, Double Error Detection)方案:在汉明码基础上增加一个整体奇偶校验位。
SEC-DED的工作逻辑是:
- 如果只有一个校验位异常,说明是校验位本身出错,无需纠正数据
- 如果多个校验位异常但整体奇偶校验正确,说明发生了两位错误,无法纠正
- 如果多个校验位异常且整体奇偶校验失败,说明发生了一位错误,可以纠正
这就是为什么ECC DIMM通常有9颗芯片(或18颗)——8颗存储数据,1颗存储8位ECC校验码。

图片来源: upload.wikimedia.org
{kind=link}
超越SEC-DED:Chipkill与SDDC
SEC-DED能纠正单比特错误,检测双比特错误。但如果一颗DRAM芯片完全失效呢?一颗4位宽的DRAM芯片故障会导致同一存储字的4位同时出错——SEC-DED对此无能为力。
这正是IBM在1997年开发Chipkill技术的原因。Chipkill的核心思想是将ECC码字分散到多颗芯片上,使得任何单颗芯片的故障最多只影响每个码字的一两位,落在SEC-DED的可纠正范围内。
具体实现上,Chipkill使用类似RAID的技术:将一个72位ECC字"条带化"分布到多颗芯片。例如,在采用x4位宽DRAM芯片的系统中,一个72位字被分散到18颗芯片,每颗芯片只贡献4位。如果一颗芯片完全失效,每个ECC字最多损失4位,但如果这4位分布在不同的校验组中,仍然可以被纠正。
AMD的类似技术称为SDDC(Single Device Data Correction,单设备数据纠正),Intel也使用这个术语。DDR5标准更进一步,将ECC直接集成到DRAM芯片内部(on-die ECC),在数据传输前就进行错误纠正。
Rowhammer:当软件变身为粒子加速器
宇宙射线导致的比特翻转是物理世界的"天灾”,但2014年的一项研究揭示了一种更可怕的"人祸":攻击者可以通过软件手段,在不需要特殊权限的情况下翻转内存比特。
这就是Rowhammer攻击。其原理利用了DRAM的高密度设计缺陷:当同一行被频繁激活时,相邻行的电容会因电耦合效应而漏电加速。如果激活频率足够高(每秒数十万次),相邻行可能在刷新周期内丢失足够电荷,导致比特翻转。
Rowhammer攻击的核心代码简洁得可怕:
hammer:
mov (X), %eax ; 读取地址X
mov (Y), %ebx ; 读取地址Y
clflush (X) ; 刷新X的缓存
clflush (Y) ; 刷新Y的缓存
jmp hammer ; 循环
这段代码反复访问两个特定地址,同时绕过CPU缓存,迫使内存控制器不断激活相同的DRAM行。攻击者可以精心选择地址,使得X和Y位于同一bank但不同行,而中间的"受害行"则遭受电耦合冲击。
2015年3月,Google Project Zero团队发布了两个基于Rowhammer的权限提升漏洞利用程序。其中一个在未经授权的情况下获得了对全部物理内存的访问权限。测试中,约一半的笔记本电脑在运行攻击代码不到五分钟内就出现了比特翻转。
更令人担忧的是,ECC并不能完全防御Rowhammer。2018年,VU Amsterdam的研究者展示了ECCploit攻击,证明攻击者可以精确控制翻转的比特数量,使ECC无法检测(例如翻转恰好3位,超出了SEC-DED的检测能力)。
Intel的ECC政策争议
如果ECC如此重要,为什么大多数消费级PC都没有配备ECC内存?Linux创始人Linus Torvalds在2021年的一次论坛讨论中,给出了直接的答案:Intel的政策。
“ECC绝对重要。Intel对整个行业和用户都有害,因为他们在ECC方面的政策是错误和误导性的。”
“反对ECC的论点从来都是彻头彻尾的垃圾。现在连内存制造商都开始在内部做ECC了,因为他们终于承认这是绝对必要的。”
Torvalds指出,Intel将ECC支持作为Xeon处理器系列的独占功能,而在消费级的Core系列中不支持。配合Intel自家广告的说法——“每年三分之一的系统会经历可纠正的内存错误…ECC内存可用于服务器,不适用于台式机”——这种市场分割策略实际上阻碍了ECC在消费市场的普及。
这种政策的结果是:消费级主板和内存市场缺乏ECC产品的激励。即使AMD的Ryzen处理器(大多数型号)“非官方"支持ECC,配套主板的支持仍然参差不齐。
值得注意的转折点是,Intel在第12代Alder Lake处理器中开始支持消费级ECC——当然,需要搭配W680芯片组主板。这个变化部分是市场压力的结果,部分是对Rowhammer威胁的回应。
数据中心如何应对
大规模数据中心对待内存错误有一套成熟的策略:
主动监控与预测。通过mcelog等工具持续收集内存错误数据,当某个DIMM的错误率超过阈值时触发预警。Facebook的研究显示,在其修复策略下(每周超过100次可纠正错误即更换),不可纠正错误率比Google研究降低了约2.8倍。
页面离线(Page Offlining)。当操作系统检测到某个物理页发生错误时,可以将其从可用内存池中移除。Facebook实际部署了这一技术,错误率降低了约67%。但这种方法有局限性:约6%的离线尝试会失败(例如页面正在被预取),且当内存控制器或通道故障时,可能导致大量页面被移除。
内存洗涤(Memory Scrubbing)。内存控制器在空闲时主动扫描所有内存地址,检测并纠正潜在错误。这种"巡逻"可以在错误积累到不可纠正之前发现它们。Facebook数据显示,67.6%的错误服务器至少有一个错误是通过scrubbing检测到的。
架构优化。Facebook的研究表明,使用更低密度的DIMM和更少CPU核心的配置可以显著降低错误率。他们的模型显示,使用低密度DIMM可使错误率降低57.7%,使用更少CPU核心可降低34.6%。
给开发者的建议
对于开发者而言,理解内存错误的现实存在有助于设计更健壮的系统:
关键数据使用校验和。即使底层有ECC保护,应用层面的校验和(如CRC、哈希)提供了额外防线。ZFS文件系统就是这一理念的典范——所有数据块都有校验和,可以检测并修复静默数据损坏。
考虑数据冗余。对于关键数据,不要依赖单一存储位置。分布式系统中的复制、本地系统中的备份,都能在内存错误导致数据损坏时提供恢复路径。
关注Rowhammer缓解。如果你的应用运行在不可信代码环境(如浏览器、云平台),考虑使用内存安全隔离技术。现代浏览器已经部署了多种Rowhammer缓解措施,但这是一个持续的攻防博弈。
慎重选择硬件。对于需要高可靠性的场景(如ZFS存储服务器、数据库服务器),选择支持ECC的平台。AMD Ryzen配合兼容主板是一个相对经济的选择;Intel则需要W680芯片组或Xeon平台。
内存错误不是一个"可能发生"的问题,而是一个"必然发生"的问题。宇宙射线、材料缺陷、电耦合效应——这些物理世界的约束决定了,只要你的系统运行足够久、内存足够大,比特翻转就会发生。
ECC并非万灵药,但它将内存错误从一个"可能导致系统崩溃或数据损坏"的问题,转变为一个"可以检测、纠正和监控"的可管理问题。在Google和Facebook的大规模生产环境中,ECC是数据完整性的基石。
Linus Torvalds的愤怒不无道理:如果ECC内存的额外成本只是约12.5%(从8颗芯片增加到9颗),如果这项技术已经存在超过50年,如果每年三分之一的系统都会经历内存错误——那么阻止它普及的不是技术障碍,而是市场分割的商业决策。
你的数据值得被保护。问题是,谁来买单?
参考资料
- Schroeder, B., Pinheiro, E., & Weber, W. D. (2009). DRAM Errors in the Wild: A Large-Scale Field Study. SIGMETRICS/Performance'09.
- Meza, J., Wu, Q., Kumar, S., & Mutlu, O. (2015). Revisiting Memory Errors in Large-Scale Production Data Centers. DSN'15.
- Kim, Y., et al. (2014). Flipping Bits in Memory Without Accessing Them: An Experimental Study of DRAM Disturbance Errors. ISCA'14.
- Ziegler, J. F., & Lanford, W. A. (1979). Effect of Cosmic Rays on Computer Memories. Science, 206(4420), 776-788.
- Hamming, R. W. (1950). Error Detecting and Error Correcting Codes. Bell System Technical Journal, 29(2), 147-160.
- Dell, T. J. (1997). A White Paper on the Benefits of Chipkill-Correct ECC for PC Server Main Memory. IBM Microelectronics Division.
- Seaborn, M., & Dullien, T. (2015). Exploiting the DRAM rowhammer bug to gain kernel privileges. Google Project Zero.
- Cojocar, L., et al. (2019). Exploiting Correcting Codes: On the Effectiveness of ECC Memory Against Rowhammer Attacks. IEEE S&P'19.
- ECC memory - Wikipedia. https://en.wikipedia.org/wiki/ECC_memory
- Soft error - Wikipedia. https://en.wikipedia.org/wiki/Soft_error
- Row hammer - Wikipedia. https://en.wikipedia.org/wiki/Row_hammer
- Linus Torvalds On The Importance Of ECC RAM. Phoronix, 2021.