title: “内存分配器为何成为高并发服务器的隐形瓶颈:从ptmalloc到mimalloc的四十年技术博弈” date: “2026-03-07T07:47:31+08:00” description: “深入解析内存分配器的演进历程,从dlmalloc的设计原理到ptmalloc的多线程扩展,从jemalloc的arena架构到tcmalloc的per-CPU缓存,再到mimalloc的free list sharding创新。揭示高并发环境下内存分配的性能瓶颈、内存碎片的本质原因,以及如何根据工作负载选择合适的内存分配器。” draft: false categories: [“系统编程”, “性能优化”] tags: [“内存分配器”, “jemalloc”, “tcmalloc”, “mimalloc”, “ptmalloc”, “内存碎片”, “多线程性能”, “系统调优”]
2017年,某支付平台的技术团队发现一个诡异现象:服务器运行一段时间后,RSS(Resident Set Size)持续增长,最终达到堆内存的三倍以上。排查后发现,问题出在glibc的默认内存分配器——即使应用层正确释放了内存,分配器却未能将物理内存归还给操作系统。
这不是个例。在RocksDB的基准测试中,使用默认glibc分配器时,RSS比使用jemalloc高出三倍。Reddit上曾有开发者提问:为什么他的程序在切换到jemalloc后,内存占用从900MB降到了合理水平?
答案指向同一个被忽视的基础设施:内存分配器。
一个被低估的性能瓶颈
内存分配器是操作系统和应用之间的中间层。每当程序调用malloc()或new,分配器需要从操作系统获取内存页,切分成合适大小的块,返回给应用;当调用free()或delete时,分配器回收这些块,决定是缓存起来复用还是归还给操作系统。
这个过程看似简单,但在高并发场景下,分配器的选择可能决定系统的生死。Facebook在2011年的技术博客中透露:其服务器应用通常使用8个以上CPU核心、5到70GB内存。在这个规模下,分配器成为性能瓶颈几乎是必然的。
问题来自三个维度:锁竞争、内存碎片和缓存局部性。
在多线程环境中,如果多个线程同时调用malloc(),而分配器使用全局锁,线程将被串行化。更隐蔽的问题是内存碎片:即使应用正确释放了所有内存,分配器可能因为碎片化而无法合并空闲块归还给操作系统。而缓存局部性问题则更加隐蔽——如果分配器将同一工作集的对象分散到不同的内存页,CPU缓存命中率会急剧下降。
这三个问题的解决方案,构成了现代内存分配器四十年技术演进的核心脉络。
dlmalloc:通用分配器的奠基之作
要理解现代分配器的设计,必须回到1987年。那年,Doug Lea开始开发一个通用目的的内存分配器,后来被称为dlmalloc。
dlmalloc的核心设计延续至今。它使用边界标签(Boundary Tags):每个内存块的前后都存储大小信息,使得相邻的空闲块可以被合并。这解决了碎片问题的最基本形式——当两个相邻的块都被释放时,它们可以合并成一个更大的块,供后续的大内存请求使用。
空闲块被组织在**箱(Bins)**中。dlmalloc维护了128个固定宽度的箱,大小按对数间隔分布。小于512字节的请求每个箱只容纳一个精确大小(间隔8字节),大于此大小的请求使用最佳适配(Best-Fit)策略。

图片来源: gee.cs.oswego.edu
{kind=link}
这个设计有一个关键优势:最佳适配策略在实际工作负载下产生的碎片最少。Wilson和Johnstone在1998年的论文《The Memory Fragmentation Problem: Solved?》中证明,对于真实的工作负载,最佳适配及其近似变体在碎片控制方面优于首次适配等其他策略。
但dlmalloc有一个致命缺陷:单线程设计。整个堆由一个全局锁保护,在多核处理器上,这成为不可接受的性能瓶颈。
ptmalloc:向多线程迈出的第一步
1997年,Wolfram Gloger将dlmalloc扩展为ptmalloc(pthreads malloc),引入了Arena的概念。
Arena是一个独立的内存区域,拥有自己的锁和数据结构。不同线程可以使用不同的Arena,从而减少锁竞争。glibc的malloc实现正是基于ptmalloc(具体是ptmalloc2)。
当线程首次调用malloc()时,它被分配到主Arena。如果主Arena的锁被占用,分配器会尝试使用其他Arena,必要时创建新的。Arena数量上限是CPU核心数的8倍——这是一个经验值,平衡了并行度和碎片化。
这个设计在2000年代初是合理的,但今天看来问题重重。首先,Arena之间的内存无法共享:线程A在Arena 1分配的内存,即使释放后,也只能回到Arena 1,无法被线程B使用。其次,当线程数量远超CPU核心数时(这在现代服务器上很常见),Arena的数量限制仍然会导致锁竞争。
2017年,glibc 2.26引入了Thread Cache(tcache):每个线程拥有一个本地缓存,小对象的分配和释放完全不需要锁。这是一个显著的改进,但tcache有大小限制(默认每个箱最多7个块),且仅适用于小对象。
更重要的是,ptmalloc的设计哲学与今天的工作负载不匹配。它诞生于单核向多核过渡的时代,设计时假设线程数量接近CPU核心数。而现代服务器可能运行数百个线程,这种情况下ptmalloc的扩展性瓶颈暴露无遗。
jemalloc:Facebook的规模化实践
2005年,Jason Evans为FreeBSD开发了jemalloc。2009年,Facebook开始将其用于生产环境,并投入大量工程资源进行优化。
jemalloc的核心创新是Arena分区+ Thread Cache的组合。
与ptmalloc不同,jemalloc的Arena数量是固定的(默认是CPU核心数的4倍),线程以轮询方式分配到Arena。这避免了ptmalloc中Arena数量不受控的问题。
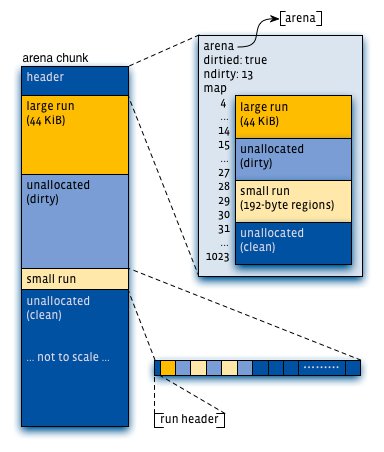
每个Arena内部,内存被组织成Chunk(默认4MB)。Chunk被进一步划分为Page Run,用于分配特定大小类别的对象。jemalloc使用红黑树跟踪非满的Page Run,总是选择地址最低的非满Run进行分配——这是从phkmalloc继承的策略,被证明能有效减少碎片。
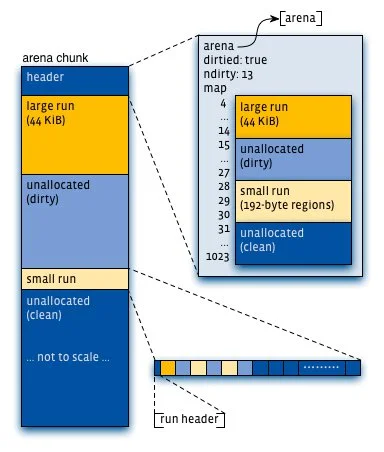
图片来源: engineering.fb.com
{kind=link}
Thread Cache是jemalloc的另一关键设计。每个线程维护一个本地缓存,存储小对象。分配和释放时,首先检查Thread Cache,命中则完全无锁。缓存大小被限制,以平衡性能和内存占用;超过限制的对象会被增量式地刷新回Arena。
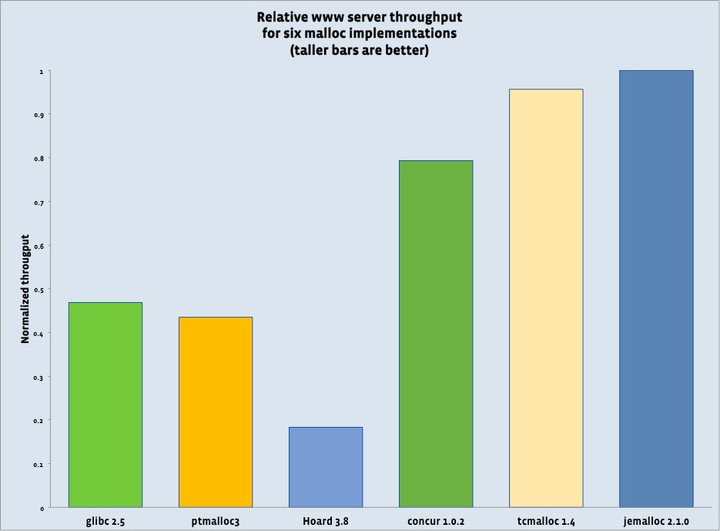
Facebook的基准测试显示了jemalloc的优势:在8核服务器上运行HipHop服务,jemalloc相比glibc malloc有显著的吞吐量提升。更关键的是,随着CPU核心数增加,jemalloc的优势继续扩大。
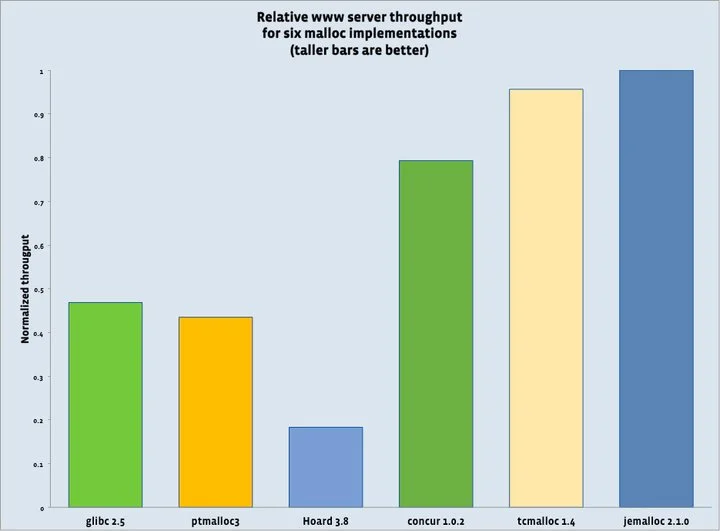
图片来源: engineering.fb.com
{kind=link}
2026年3月,Meta宣布重新投资jemalloc,承认近年来的维护有所松懈,计划清理技术债务、改进Huge Page分配器和ARM64优化。这表明即使在mimalloc等新分配器崛起的今天,jemalloc仍然是大规模生产环境的首选。
tcmalloc:Google的Per-CPU创新
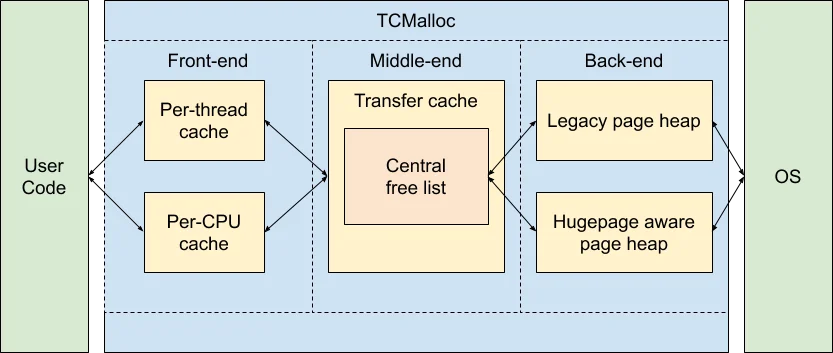
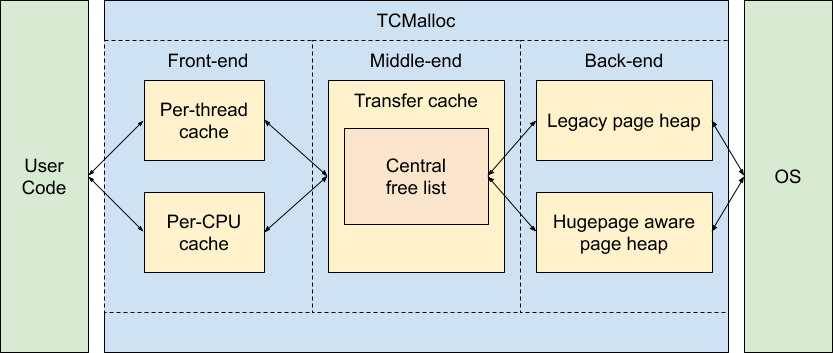
Google的tcmalloc(Thread-Caching Malloc)采用了不同的策略。
tcmalloc的架构分为三层:前端、中端和后端。前端负责服务分配请求,中端(Transfer Cache和Central Free List)负责协调,后端(PageHeap)负责从操作系统获取内存。
早期版本的tcmalloc使用Per-Thread Cache:每个线程有独立的缓存。这与jemalloc的设计类似。但Google发现,随着线程数量增长,Per-Thread Cache的问题日益突出:线程之间无法共享缓存内存,总体内存占用过高。
现代tcmalloc默认使用Per-CPU Cache:每个逻辑CPU核心拥有独立的缓存,同一核心上的所有线程共享这个缓存。这是通过Linux的**Restartable Sequences(rseq)**实现的——一种允许原子操作无需锁的内核机制。
图片来源: google.github.io
{kind=link}
Per-CPU Cache的优势在于:CPU核心数通常远小于线程数,因此缓存总量可控;同时,同一核心上的线程切换不会导致缓存失效。
tcmalloc另一个独特之处是Span的概念。Span是一组连续的TCMalloc Page(可以是4KB、8KB、32KB或256KB),用于管理相同大小类别的对象。通过Pagemap(一个两级或三级基数树),tcmalloc可以快速将任意地址映射到对应的Span。
Google在2024年的ASPLOS论文《Characterizing a Memory Allocator at Warehouse Scale》中详细分析了tcmalloc在Google生产环境中的行为,这是首次对大规模生产环境分配器的系统性研究。
mimalloc:微软的Free List Sharding
2019年,微软研究院发布了mimalloc,声称在广泛基准测试中始终优于其他主流分配器。
mimalloc的核心创新是Free List Sharding。传统分配器为每个大小类别维护一个空闲链表,而mimalloc将每个页的空闲链表进一步切分成三个:一个用于本地线程的释放,一个用于其他线程的释放,一个用于延迟释放。

图片来源: www.microsoft.com
这个设计有几个好处。首先,本地释放可以完全无锁。其次,当需要处理非本地释放时,可以批量处理,而不是每次释放都触发同步。第三,延迟释放链表允许分配器控制何时真正执行释放,避免在关键路径上进行系统调用。
微软的基准测试显示,mimalloc在Redis上的性能比jemalloc和tcmalloc分别高出14%和7%。更重要的是,mimalloc的一致性很好——在各种工作负载下都不会出现性能断崖。
mimalloc还特别关注引用计数语言(如Swift和Python)的需求。这类语言的内存管理高度依赖分配器,mimalloc的设计使其能够高效支持频繁的对象分配和释放。
内存碎片:无法回避的权衡
无论分配器如何设计,内存碎片都是一个无法完全消除的问题。
碎片分为两种:内部碎片和外部碎片。内部碎片是分配的块大于请求的大小时的浪费——例如请求21字节,分配器返回32字节的块,浪费11字节。外部碎片是虽然总空闲空间足够,但由于不连续,无法满足大内存请求。
碎片与分配策略密切相关。Best-Fit策略选择能满足请求的最小块,理论上内部碎片最小;但可能导致外部碎片增加。First-Fit策略选择第一个足够大的块,分配速度快,但可能导致大块被切碎。
现代分配器通常采用Segregated-Fit策略:将内存按大小类别分区,每个区内部使用简单策略。这结合了两种策略的优点。
Wilson和Johnstone的研究表明,碎片程度与工作负载的"热度"密切相关。如果所有对象的寿命相同(同时分配、同时释放),碎片几乎为零。如果长短寿命对象混合,碎片会急剧增加。这被称为寿命混合问题。
这也是为什么分配器调优如此困难:最佳配置取决于具体工作负载,而工作负载往往是动态变化的。
如何选择内存分配器
选择分配器需要考虑多个因素。
工作负载特性是首要因素。如果应用频繁分配和释放小对象(如Web服务器处理请求),Thread Cache或Per-CPU Cache的设计会有显著优势。如果应用主要分配大对象,分配器的选择影响较小。如果应用的内存使用模式高度一致,可以考虑使用Arena或Pool分配器进一步优化。
内存约束也很重要。如果系统内存紧张,需要选择碎片控制更好的分配器。jemalloc的低地址优先策略在这方面表现良好。tcmalloc提供了"small-but-slow"模式,以性能换取更低的内存占用。
调试需求决定了是否需要丰富的工具链。jemalloc和tcmalloc都提供详细的统计信息和堆分析工具。glibc malloc的调试能力相对有限。
平台兼容性需要考虑。mimalloc支持Windows、Linux和macOS。jemalloc和tcmalloc主要针对类Unix系统,但也有Windows移植版本。
一个实用的建议:在生产环境切换分配器之前,务必使用真实工作负载进行基准测试。分配器的性能高度依赖具体场景,别人的基准测试结果未必适用于你的应用。
Redis默认使用jemalloc,这是经过充分测试的选择。但如果你运行的是内存受限的嵌入式系统,可能mimalloc更合适。如果你的应用线程数远超CPU核心数,tcmalloc的Per-CPU模式可能表现更好。
结语:没有万能方案,只有权衡
四十年演进,内存分配器从dlmalloc的单线程设计,进化到ptmalloc的Arena机制,再到jemalloc和tcmalloc的Thread/Per-CPU Cache,以及mimalloc的Free List Sharding。每一次进步都在解决特定的性能瓶颈,但也引入新的权衡。
Arena减少了锁竞争,但增加了内存碎片。Thread Cache提升了分配速度,但增加了内存占用。Per-CPU Cache解决了线程数爆炸的问题,但依赖特定的内核特性。
这正是系统设计的本质:没有完美的方案,只有在特定约束下的最优权衡。理解分配器的设计原理,才能在面对内存问题时做出正确的技术决策。
参考资料
- Doug Lea. “A Memory Allocator.” https://gee.cs.oswego.edu/dl/html/malloc.html
- Jason Evans. “Scalable memory allocation using jemalloc.” Facebook Engineering, 2011. https://engineering.fb.com/2011/01/03/core-infra/scalable-memory-allocation-using-jemalloc/
- Google. “TCMalloc : Thread-Caching Malloc Design.” https://google.github.io/tcmalloc/design.html
- Daan Leijen. “Mimalloc: Free List Sharding in Action.” Microsoft Research, 2019. https://www.microsoft.com/en-us/research/publication/mimalloc-free-list-sharding-in-action/
- Emery D. Berger, Kathryn S. McKinley. “Hoard: A Scalable Memory Allocator for Multithreaded Applications.” ASPLOS 2000.
- Mark S. Johnstone, Paul R. Wilson. “The Memory Fragmentation Problem: Solved?” ISMM 1998.
- glibc wiki. “MallocInternals.” https://sourceware.org/glibc/wiki/MallocInternals
- Meta Engineering. “Investing in Infrastructure: Meta’s Renewed Commitment to jemalloc.” 2026. https://engineering.fb.com/2026/03/02/data-infrastructure/investing-in-infrastructure-metas-renewed-commitment-to-jemalloc/
- MIT/Google. “Characterizing a Memory Allocator at Warehouse Scale.” ASPLOS 2024.