
2017年,WebAssembly正式成为W3C标准。七年后的今天,它已经从"浏览器的第四种语言"演变为跨平台运行时基础设施的核心。但WebAssembly的真正价值远不止于"比JavaScript快"——它的运行时系统设计蕴含着计算机科学中安全、性能、可移植性之间的精妙权衡。
线性内存:简单设计背后的复杂权衡
WebAssembly的内存模型是理解其运行时的起点。与JVM的托管堆或JavaScript的垃圾回收对象图不同,WebAssembly采用了最简单的线性内存模型:一块连续的、可索引的字节数组。
这种设计并非偶然。当WebAssembly团队在设计内存模型时,他们面临一个根本性的约束:必须高效编译来自C/C++/Rust等手动内存管理语言的代码。这些语言的内存访问模式是任意的,依赖于指针算术。任何复杂的内存模型都会带来不可接受的性能开销。
线性内存的实现非常直观:
;; WebAssembly文本格式 (WAT)
(module
;; 声明一个初始1页(64KB)、最大10页的内存
(memory (export "memory") 1 10)
;; 在内存地址0存储一个32位整数
(func (export "store") (param $val i32)
local.get $val
i32.const 0
i32.store
)
;; 从内存地址0读取一个32位整数
(func (export "load") (result i32)
i32.const 0
i32.load
)
)
但"简单"并不意味着"简陋"。线性内存的设计涉及几个关键的技术决策:
页大小与对齐
WebAssembly内存以页为单位管理,每页固定64KB($2^{16}$字节)。这个数字的选择经过了深思熟虑:太小会导致页表过大,太大会导致内存碎片。64KB在大多数操作系统上是一个合理的折中——足够大以摊薄管理开销,足够小以保持灵活性。
内存地址必须对齐。访问4字节的i32要求地址是4的倍数,访问8字节的i64或f64要求地址是8的倍数。未对齐的访问在某些架构上会导致性能下降甚至硬件异常。WebAssembly规范允许未对齐访问,但运行时可能需要生成额外的代码来处理。
动态增长与代价
memory.grow指令允许运行时扩展线性内存。但这是一个昂贵的操作:
;; 尝试增长1页内存,返回之前的页数(-1表示失败)
memory.grow (i32.const 1)
增长内存可能触发:
- 操作系统内存分配(可能涉及页表修改)
- 内存内容复制(如果无法原地扩展)
- 地址空间重映射
更关键的是,memory.grow是一个同步的、全局可见的操作。在多线程WebAssembly中,这需要所有线程协调。因此,生产环境的最佳实践是:在模块初始化时分配足够的内存,避免运行时增长。
边界检查与安全
线性内存的"沙箱"性质依赖于边界检查。每次内存访问都必须验证地址在有效范围内。但边界检查是性能杀手。
WebAssembly规范要求:越界访问必须触发陷阱,而非未定义行为。这与C/C++的语义形成鲜明对比——在C中,越界访问可能读取任意内存,导致安全漏洞;在WebAssembly中,越界访问被可靠地检测和阻止。
实现边界检查有多种策略:
显式检查:在每次内存访问前插入条件判断
;; 伪代码展示边界检查逻辑
(if (i32.lt_u (i32.add addr size) (memory.size_bytes))
(then (memory_access))
(else (unreachable)) ;; 触发陷阱
)
保护页:在内存末尾预留"禁止区",利用硬件内存保护
V8和Wasmtime默认使用保护页策略。当访问越界地址时,硬件会触发页面错误,运行时将其转换为WebAssembly陷阱。这种方法对于小范围越界访问非常高效,但对于大范围越界(超过保护页大小)仍需显式检查。
研究表明,在最坏情况下,边界检查可能引入高达650% 的性能开销。这是WebAssembly相对于原生代码的主要性能差距来源之一。
表机制:间接调用的秘密
线性内存处理数据,那函数指针呢?WebAssembly的答案是表。
表是一个存储引用的数组。在WebAssembly v1中,表只能存储函数引用;后来的扩展允许存储其他类型的引用。表的存在是为了支持间接调用——函数指针的语言级等价物。
(module
;; 定义函数类型
(type $int2int (func (param i32) (result i32)))
;; 声明一个有32个槽位的表
(table 32 funcref)
;; 定义两个函数
(func $double (type $int2int) (param $x i32) (result i32)
i32.const 2
local.get $x
i32.mul
)
(func $triple (type $int2int) (param $x i32) (result i32)
i32.const 3
local.get $x
i32.mul
)
;; 初始化表:将函数放入槽位16和17
(elem (i32.const 16) $double $triple)
;; 导出一个函数,通过表间接调用
(func (export "apply") (param $idx i32) (param $x i32) (result i32)
local.get $x
local.get $idx
call_indirect (type $int2int)
)
)
间接调用的执行流程:
- 索引解析:从表中读取指定索引的函数引用
- 类型检查:验证函数签名与
call_indirect声明的类型匹配 - 调用执行:跳转到函数入口
类型检查是关键的安全机制。它防止了C/C++世界中常见的函数指针类型混淆漏洞——攻击者无法将一个签名为(i32) -> i32的函数指针重新解释为(i32) -> void来劫持控制流。
但这种保护是粗粒度的。WebAssembly的类型系统只区分参数和返回值的数值类型,不理解语义层面的类型差异。例如,一个接受"文件描述符"的函数和一个接受"数组索引"的函数,在类型层面都是i32,无法区分。
表与虚拟函数表
熟悉C++的读者会注意到表与虚拟函数表的相似性。确实,编译器通常将C++的虚函数映射到WebAssembly表:
// C++ 代码
class Animal {
public:
virtual void speak() = 0;
};
class Dog : public Animal {
public:
void speak() override { /* ... */ }
};
// 编译后,vtable会被放入WebAssembly表中
表的设计允许WebAssembly支持面向对象编程的动态分发机制,同时保持底层实现的简单性。
编译与执行:V8的分层策略
理解了内存和调用机制后,我们来看WebAssembly代码如何被编译和执行。
WebAssembly的设计承诺是"可预测的性能"。这与JavaScript形成对比——JavaScript的JIT编译器依赖运行时类型反馈进行优化,代码执行速度可能在运行过程中发生剧烈变化(从解释执行到高度优化)。WebAssembly避免了这种不确定性:代码在执行前已经编译为机器码。
但"提前编译"带来了新的挑战:编译时间。大型WebAssembly应用(如游戏引擎或CAD软件)的二进制大小可能达到30-50MB。完全优化编译这些代码需要数十秒。
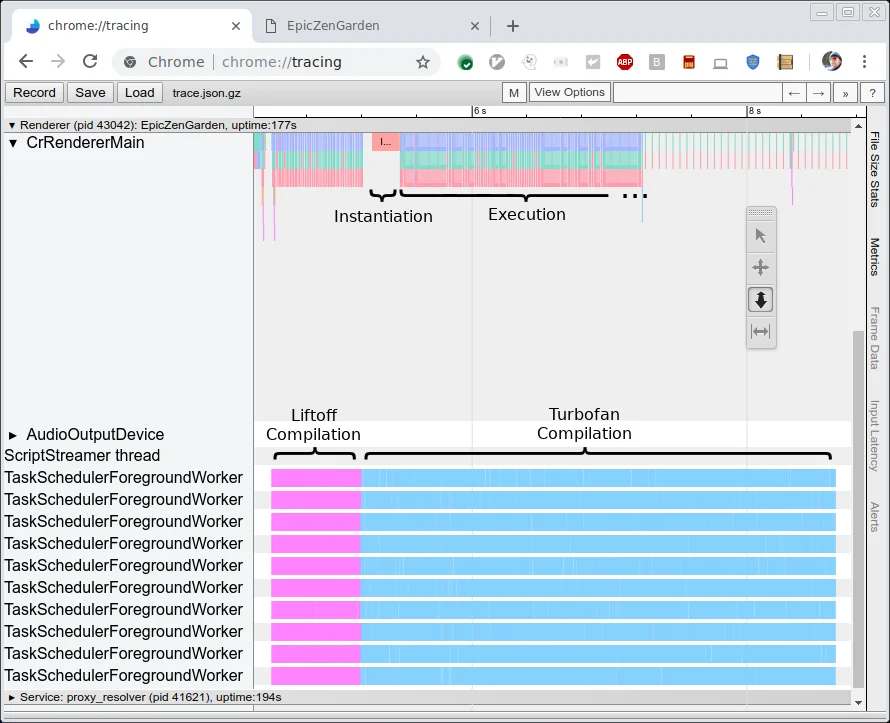
V8的解决方案是分层编译:

图片来源: V8 Blog
Liftoff:基线编译器
Liftoff是V8的WebAssembly基线编译器,设计目标是快速代码生成,而非最优代码质量。它采用单次遍历策略:
- 解析WebAssembly字节码
- 同时验证和生成机器码
- 不构建中间表示(IR),直接输出
Liftoff的关键优化是虚拟栈。编译时,Liftoff维护一个虚拟的栈状态,记录每个值存储的位置(寄存器或栈槽)。由于WebAssembly的结构化控制流,这些位置可以静态确定,不需要运行时的实际栈操作。
对于简单的加法函数:
(func $add (param i32 i32) (result i32)
local.get 0
local.get 1
i32.add
)
Liftoff生成的x86-64机器码类似于:
; 假设参数在rax和rdx中
mov rcx, rax ; 复制第一个参数
add rcx, rdx ; 加上第二个参数
mov rax, rcx ; 结果放入返回寄存器
ret
Liftoff的编译速度比TurboFan快数倍,但生成的代码质量较差——通常比TurboFan慢50-70%。
TurboFan:优化编译器
TurboFan是V8的通用优化编译器,最初为JavaScript设计,后来扩展支持WebAssembly。它采用传统的编译器流水线:
- 构建图:将WebAssembly字节码转换为Sea of Nodes IR
- 优化:执行内联、常量折叠、死代码消除等优化
- 寄存器分配:为变量分配物理寄存器
- 代码生成:输出目标架构的机器码
TurboFan的优势是生成的代码质量高,接近原生性能。劣势是编译慢,内存占用大。
Tier-Up策略
V8采用急切分层策略:
- 模块加载时,Liftoff快速编译所有函数
- 编译完成后,立即在后台线程启动TurboFan编译
- TurboFan编译完成一个函数,就替换对应的Liftoff代码
图片来源: V8 Blog
这种策略确保:
- 用户可以在编译完成后立即开始执行
- 热代码很快被优化版本替换
- 不存在解释执行的慢速阶段
对于AutoDesk这类36.8MB的大型模块,Liftoff将启动时间从30+秒降至几秒,同时TurboFan确保了后续的峰值性能。
模块实例化:从字节码到运行实体
当浏览器加载一个.wasm文件,发生了什么?
解码与验证
WebAssembly二进制格式是紧凑且规范的。解码器逐字节解析:
- 魔数和版本:前4字节是
\0asm,后4字节是版本号 - 段:模块由多个段组成,如类型段、函数段、内存段等
- 条目:每段包含若干条目
验证是单次遍历的——WebAssembly的结构化控制流确保了可以在解析同时完成验证。验证内容包括:
- 类型一致性:所有操作的操作数类型正确
- 控制流完整性:分支目标存在且栈状态匹配
- 资源限制:不超过最大函数数、表大小等限制
验证的复杂度是线性的 $O(n)$,其中 $n$ 是模块大小。
实例化
验证通过后,运行时创建模块实例:
┌─────────────────────────────────────────────────────┐
│ WebAssembly实例 │
├─────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ 线性内存 │ │ 表 │ │ 全局变量 │ │
│ │ (ArrayBuffer)│ │ (函数引用) │ │ (数值) │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ │
├─────────────────────────────────────────────────────┤
│ ┌─────────────────────────────────────────────┐ │
│ │ 导入项 (Imports) │ │
│ │ • 内存导入 │ │
│ │ • 函数导入 │ │
│ │ • 全局变量导入 │ │
│ └─────────────────────────────────────────────┘ │
├─────────────────────────────────────────────────────┤
│ ┌─────────────────────────────────────────────┐ │
│ │ 导出项 (Exports) │ │
│ │ • 函数导出 │ │
│ │ • 内存导出 │ │
│ │ • 表导出 │ │
│ └─────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────┘
实例化过程:
- 解析导入:连接宿主提供的内存、函数、全局变量
- 分配资源:创建线性内存、表、全局变量
- 初始化元素:填充表中的函数引用
- 数据初始化:将数据段写入内存
- 执行start函数:如果模块声明了启动函数
实例化是"昂贵"的——涉及内存分配和符号解析。对于服务器端WebAssembly,运行时通常实现实例池化来复用资源。
Store:全局状态的容器
在WebAssembly规范中,Store是所有WebAssembly实例共享的全局状态容器。它包含:
- 所有函数实例
- 所有表实例
- 所有内存实例
- 所有全局变量实例
Wasmtime等运行时将Store实现为一个显式的上下文对象,所有实例共享同一个Store。这种设计支持:
- 跨实例共享资源(如共享内存)
- 精确的生命周期管理
- 嵌入式场景的资源隔离
安全机制:陷阱与沙箱
WebAssembly的安全性是其设计的核心目标之一。安全模型有两个层次:
用户保护:沙箱隔离
每个WebAssembly模块在沙箱中执行,与宿主运行时隔离。这意味着:
- 内存隔离:模块只能访问自己的线性内存,无法读写宿主或其他模块的内存
- 控制流完整性:模块只能调用明确导入或导出的函数,无法跳转到任意地址
- 无原始系统调用:模块不能直接访问文件系统、网络等资源,必须通过宿主授权
这种隔离是通过能力安全模型实现的:模块只能访问它被明确授予的资源。
开发者保护:安全原语
WebAssembly消除了一些常见的安全漏洞类别:
缓冲区溢出:由于边界检查,越界写入无法破坏相邻内存。但注意,模块内部的逻辑仍然可能被破坏——边界检查在内存区域级别进行,不理解模块内的对象边界。
代码注入:由于代码是不可变的,且内存页面不可执行,攻击者无法注入新代码。
控制流劫持:由于结构化控制流和类型检查的间接调用,攻击者无法构造非法的控制流图。
陷阱:安全违规的信号
当检测到违规操作时,WebAssembly触发陷阱:
// JavaScript中的陷阱表现为异常
try {
instance.exports.someFunction();
} catch (e) {
// RuntimeError: memory access out of bounds
// 或 RuntimeError: divide by zero
// 或 RuntimeError: unreachable executed
}
陷阱触发场景包括:
- 内存访问越界
- 除以零或整数溢出
- 表索引越界
- 间接调用类型不匹配
- 显式的
unreachable指令
陷阱无法被WebAssembly代码捕获。这是有意为之:陷阱代表严重的安全违规,应该终止当前操作,而非被静默处理。
WasmGC:让托管语言入驻
WebAssembly最初是为C/C++/Rust等手动内存管理语言设计的。但许多重要的编程语言——Java、Kotlin、Dart、Python——都依赖垃圾回收。如何将它们移植到WebAssembly?
传统方案的问题
在WasmGC之前,移植GC语言的标准做法是:将语言的整个运行时(包括GC实现)编译为WebAssembly。
这种方法有几个问题:
- 代码膨胀:GC实现增加了二进制大小
- 重复工作:浏览器已经有高性能GC,为何要再实现一个?
- 内存效率低:两套GC互不协调,可能导致内存碎片和泄漏
- 性能损失:无法利用宿主的GC优化
WasmGC的解决方案
WasmGC提案引入了托管对象类型:
;; 定义一个结构体类型
(type $point (struct
(field $x f64)
(field $y f64)
))
;; 定义一个数组类型
(type $int-array (array i32))
;; 创建结构体实例
(struct.new $point
(f64.const 1.0)
(f64.const 2.0)
)
;; 读取字段
(struct.get $point $x
(local.get $point-ref)
)
这些对象由宿主运行时的GC管理,不需要编译器自带GC。这带来了显著的好处:
- 代码体积:Fannkuch基准测试中,Java版本仅2.3KB,而C/Rust版本为6-10KB
- 内存效率:统一管理,无碎片
- 互操作性:与JavaScript对象交互更简单
图片来源: JetBrains Compose Multiplatform - Kotlin/WasmGC 使得移动端UI代码可以直接在浏览器运行
运行时的多样性
WebAssembly运行时不再局限于浏览器:
| 运行时 | 目标环境 | 特点 |
|---|---|---|
| V8 | 浏览器、Node.js | 与JavaScript紧密集成,分层编译 |
| SpiderMonkey | Firefox | 独立的Wasm编译管道 |
| Wasmtime | 服务器 | 安全优先,Cranelift后端 |
| WAMR | 嵌入式 | 低内存占用,AOT编译 |
| Wasmer | 通用 | 多后端支持,跨平台 |
每个运行时都有自己的权衡取舍。V8追求峰值性能,Wasmtime强调安全审计,WAMR专注资源效率。
组件模型:互操作性的未来
当前的WebAssembly模块间互操作需要通过线性内存传递数据,这要求双方约定内存布局,难以实现跨语言复用。
组件模型通过引入接口类型解决这个问题:
// WebAssembly Interface Types
interface database {
resource connection {
query: func(sql: string) -> result-set;
}
resource result-set {
next: func() -> option<row>;
}
}
组件模型允许:
- 跨语言链接:不同语言编写的模块直接组合
- 高级类型:字符串、记录、变体等,无需手动序列化
- 虚拟化:接口可以有不同的实现
这是WebAssembly从"浏览器中的C运行时"进化为"跨语言通用运行时"的关键一步。
性能优化的实践指南
理解运行时后,如何写出高性能的WebAssembly代码?
1. 预分配内存
;; 坏做法:运行时增长
(func $grow-memory
(memory.grow (i32.const 1))
)
;; 好做法:初始化时声明足够大小
(memory 256) ;; 256 * 64KB = 16MB
2. 减少跨边界调用
每次Wasm-JS边界穿越都有开销。批量操作优于频繁小调用:
// 坏做法:频繁调用
for (let i = 0; i < 10000; i++) {
instance.exports.processItem(i);
}
// 好做法:批量传递
const data = new Int32Array(memory.buffer, 0, 10000);
for (let i = 0; i < 10000; i++) data[i] = i;
instance.exports.processBatch(0, 10000);
3. 使用流式编译
// 并行下载和编译
WebAssembly.instantiateStreaming(fetch('module.wasm'), imports);
4. 避免间接调用
间接调用比直接调用慢,因为需要类型检查和表查找。在性能关键路径上,优先使用直接调用。
结语
WebAssembly运行时是一个精心设计的系统,在多个维度上做出权衡:
- 安全与性能:边界检查引入开销,但保护页技术优化常见情况
- 启动速度与峰值性能:分层编译平衡两者
- 隔离与互操作:沙箱保证安全,但边界穿越需要开销
- 通用性与特化:线性内存简单通用,但GC等特性需要特化支持
理解这些权衡,才能在工程实践中做出正确的技术决策。WebAssembly的成功不在于它是"银弹",而在于它在设计之初就明确了要解决的问题,并为未来的扩展留下了空间。
随着WasmGC、组件模型等提案的成熟,WebAssembly运行时正在从"浏览器中的C/C++运行环境"进化为真正的跨平台、跨语言通用运行时。这不是颠覆,而是延续——延续WebAssembly设计哲学中平衡与实用主义的核心价值。
References
- WebAssembly Specification - https://webassembly.github.io/spec/core/
- V8 Blog: Liftoff - https://v8.dev/blog/liftoff
- V8 Blog: WasmGC Porting - https://v8.dev/blog/wasm-gc-porting
- WebAssembly Security Model - https://webassembly.org/docs/security/
- Component Model Design - https://component-model.bytecodealliance.org/design/
- Wasmtime Security Documentation - https://docs.wasmtime.dev/security.html
- WebAssembly Linear Memory Example - https://wasmbyexample.dev/examples/webassembly-linear-memory/
- Indirect Calls in WebAssembly - https://eli.thegreenplace.net/2023/playing-with-indirect-calls-in-webassembly/
- WebAssembly Runtime Survey (arXiv) - https://arxiv.org/html/2404.12621v1
- WASI Design Principles - https://github.com/WebAssembly/WASI/blob/master/docs/DesignPrinciples.md
- WebAssembly Performance Patterns - https://web.dev/articles/webassembly-performance-patterns-for-web-apps
- Chrome Blog: WasmGC - https://developer.chrome.com/blog/wasmgc
- Leaps and Bounds: Bounds Checking Analysis (IISWC 2022) - https://ieeexplore.ieee.org/document/9975418/
- WebAssembly GC Proposal - https://github.com/WebAssembly/gc/blob/main/proposals/gc/Overview.md
- WebAssembly Threads - https://web.dev/articles/webassembly-threads