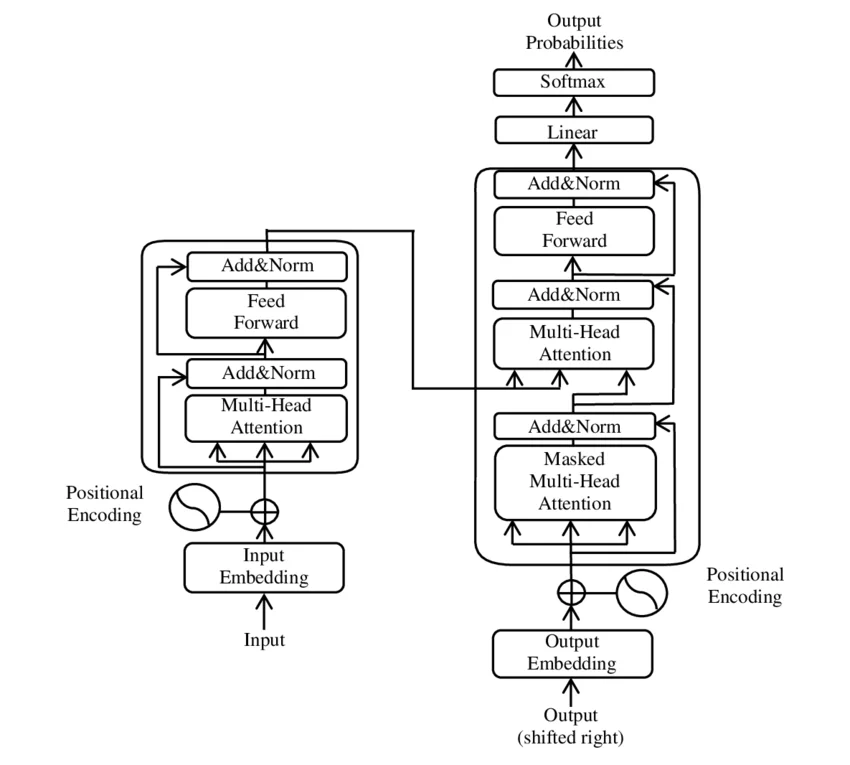
Layer Normalization的可学习参数:为什么gamma和beta正在从大模型中消失
Layer Normalization的可学习参数:为什么gamma和beta正在从大模型中消失 2016年,Jimmy Lei Ba、Jamie Ryan Kiros和Geoffrey Hinton在论文《Layer Normalization》中提出了一个看似简单的设计:在归一化操作后添加两个可学习参数gamma和beta。九年后的今天,LLaMA、Mistral、Gemma等主流大模型都在悄悄移除这些参数——或者至少移除其中一部分。这个趋势背后隐藏着怎样的技术逻辑? ...