
1999年,当InfiniBand Trade Association成立时,很少有人预料到这项技术会在二十年后成为人工智能训练网络的核心基础设施。RDMA(Remote Direct Memory Access,远程直接内存访问)从一个旨在替代PCI总线的技术愿景,演变成了现代数据中心不可或缺的性能加速器。
传统网络的瓶颈在哪里
在理解RDMA之前,需要先看清传统网络传输的代价。当一台服务器通过TCP/IP向另一台服务器发送数据时,数据要经历漫长的旅程:
应用程序将数据写入用户空间缓冲区 → 系统调用将数据复制到内核空间 → TCP协议栈处理(分段、校验和计算、流量控制)→ 数据再次复制到socket缓冲区 → DMA引擎将数据搬运到网卡 → 网络传输 → 接收端反向重复这个过程。
每一步都有代价。一次标准的数据传输涉及至少四次内存拷贝:用户空间到内核空间、内核空间到socket缓冲区、DMA到网卡发送缓冲区、网卡接收缓冲区到目标内存。每次拷贝都需要CPU参与,每次上下文切换都会刷新TLB和缓存。
当网络带宽达到100Gbps甚至更高时,这些开销变得无法忽视。在高速网络环境下,CPU处理网络协议栈的时间可能比实际数据传输时间还长。研究表明,在100Gbps网络环境下,传统TCP/IP协议栈可能消耗高达30-40%的CPU资源,仅仅用于搬运数据。
更致命的是延迟。传统TCP/IP通信的往返延迟通常在几十微秒到几百微秒量级,其中相当一部分消耗在内核协议栈处理上。对于高频交易、分布式数据库、AI训练等对延迟极其敏感的场景,这个开销是难以接受的。
RDMA的核心突破:绕过一切中间层
RDMA的核心理念极其简单:让网卡直接读写远程服务器的内存,绕过CPU和操作系统内核。这个"绕过"不是比喻,而是物理层面的事实。
当应用程序发起一次RDMA读操作时,本地网卡(RNIC)直接从应用程序注册的内存区域读取数据,封装成网络包发送出去。远程网卡收到包后,直接将数据写入目标内存区域——整个过程不需要远程服务器的CPU参与,操作系统内核甚至不知道发生了什么。
这种设计带来三个直接收益:
零拷贝(Zero-Copy):数据直接从发送端应用程序内存传输到接收端应用程序内存,中间没有任何拷贝。传统网络传输的4次内存拷贝被缩减为0次。
内核旁路(Kernel Bypass):应用程序直接通过用户态驱动与网卡交互,完全跳过内核网络协议栈。这消除了系统调用开销、上下文切换开销以及内核锁竞争。
CPU卸载(CPU Offload):所有协议处理(可靠传输、流控、校验和)都由网卡硬件完成。CPU只需要在初始化时设置好参数,后续的数据传输完全不需要CPU干预。
性能提升是显著的。RDMA网络通常能实现约2微秒的往返延迟,而传统TCP/IP在最佳条件下也需要几十微秒。在CPU利用率方面,RDMA可以将网络传输的CPU开销降低90%以上。
RDMA架构:Queue Pair的精妙设计
RDMA的硬件架构围绕一个核心概念展开:Queue Pair(QP)。
Channel Adapter:RDMA网络的端点
在InfiniBand网络中,每个端点被称为Channel Adapter(CA)。主机端的称为Host Channel Adapter(HCA),类似于以太网中的网卡,但功能更加丰富。

Queue Pair与Completion Queue
Queue Pair由两个队列组成:Send Queue(SQ)和Receive Queue(RQ)。每个队列都是一个环形缓冲区,存储Work Request(WR)。应用程序通过将Work Queue Entry(WQE)写入队列来提交工作请求,网卡硬件则从队列中取出WQE执行。
┌─────────────────────────────────────────────────────────────┐
│ Queue Pair (QP) │
├────────────────────────┬────────────────────────────────────┤
│ Send Queue (SQ) │ Receive Queue (RQ) │
├────────────────────────┼────────────────────────────────────┤
│ WR1: RDMA Write │ WR1: Receive Buffer │
│ WR2: RDMA Read │ WR2: Receive Buffer │
│ WR3: Send │ WR3: Receive Buffer │
│ ... │ ... │
└────────────────────────┴────────────────────────────────────┘
│
▼
┌──────────────────────────────┐
│ Completion Queue (CQ) │
├──────────────────────────────┤
│ WC1: WR1 completed (success) │
│ WC2: WR2 completed (success) │
│ WC3: WR3 completed (error) │
└──────────────────────────────┘
Completion Queue(CQ)用于通知应用程序工作请求已完成。当网卡完成一个操作后,它会将Work Completion(WC)写入关联的CQ。应用程序可以轮询(polling)CQ来检查操作完成状态,这种忙等待方式虽然消耗CPU周期,但能实现最低延迟。
Memory Region与Protection Domain
RDMA网卡需要直接访问应用程序内存,这带来了安全和地址翻译问题。Memory Region(MR)就是解决方案。
应用程序必须先注册(pin/lock)一段内存区域,将其告知网卡。注册过程包括:
- 将虚拟地址翻译为物理地址
- 锁定物理页面,防止被换出
- 生成local key(lkey)和remote key(rkey)
lkey用于本地操作验证,rkey用于远程操作验证。只有持有正确rkey的远程节点才能访问这块内存。
Protection Domain(PD)是一个逻辑容器,将QP、MR等资源分组隔离。不同PD中的资源无法互相访问,提供了基本的安全边界。
Queue Pair的类型与状态机
RDMA支持多种QP类型,满足不同场景需求:
| QP类型 | 全称 | 特点 | 适用场景 |
|---|---|---|---|
| RC | Reliable Connection | 可靠连接,保证顺序和可靠传输 | 分布式存储、数据库 |
| UC | Unreliable Connection | 不可靠连接,不保证可靠性 | 可容忍丢包的场景 |
| UD | Unreliable Datagram | 不可靠数据报,支持多播 | 服务发现、组播 |
QP的状态机设计确保了连接的正确建立:
RESET → INIT → RTR (Ready to Receive) → RTS (Ready to Send)
从RESET到INIT需要设置端口、分区键等基本信息;从INIT到RTR需要设置对端QP号、LID等连接信息;从RTR到RTS则配置重传参数。每一步转换都通过ibv_modify_qp()系统调用完成。
三种协议的博弈:InfiniBand、RoCE与iWARP
RDMA是一个通用概念,具体实现有多种协议。三种主流协议各有优劣,代表了不同的设计哲学。
InfiniBand:为RDMA而生的原生协议
InfiniBand是RDMA的原生载体,从物理层到传输层都是全新设计。它使用交换式架构(Switched Fabric),每个节点通过Host Channel Adapter(HCA)连接到InfiniBand交换机。
InfiniBand的带宽演进:
- SDR (Single Data Rate): 2.5 Gbps per lane (2000年)
- DDR (Double Data Rate): 5 Gbps per lane (2005年)
- QDR (Quad Data Rate): 10 Gbps per lane (2008年)
- FDR (Fourteen Data Rate): 14 Gbps per lane (2011年)
- EDR (Enhanced Data Rate): 25 Gbps per lane (2014年)
- HDR (High Data Rate): 50 Gbps per lane (2017年)
- NDR (Next Data Rate): 100 Gbps per lane (2021年)
InfiniBand网络需要一个子网管理器(Subnet Manager,SM)来管理拓扑、分配地址、配置路由。OpenSM是开源的子网管理器实现,通常运行在交换机或服务器上。
InfiniBand的优势是性能极致:亚微秒延迟、高带宽、原生支持RDMA。缺点是构建成本高,需要专用交换机和线缆,与现有以太网基础设施不兼容。
RoCE:RDMA over Converged Ethernet
RoCE的核心思想是:让以太网也支持RDMA。它封装InfiniBand传输层协议,在以太网帧中传输RDMA数据包。
RoCE有两个版本:
RoCE v1:以太网链路层协议,使用Ethertype 0x8915。只能在同一二层广播域内通信,不可路由。
RoCE v2:在UDP/IP之上运行,使用目的端口4791。支持三层路由,可以跨子网通信。
┌─────────────────────────────────────────┐
│ RoCE v1 Frame │
├─────────────────────────────────────────┤
│ Ethernet Header (DMAC, SMAC, 0x8915) │
├─────────────────────────────────────────┤
│ InfiniBand Transport Header │
├─────────────────────────────────────────┤
│ Payload │
├─────────────────────────────────────────┤
│ ICRC (Invariant CRC) │
└─────────────────────────────────────────┘
┌─────────────────────────────────────────┐
│ RoCE v2 Packet │
├─────────────────────────────────────────┤
│ Ethernet Header │
├─────────────────────────────────────────┤
│ IP Header │
├─────────────────────────────────────────┤
│ UDP Header (Dst Port: 4791) │
├─────────────────────────────────────────┤
│ InfiniBand Transport Header │
├─────────────────────────────────────────┤
│ Payload │
├─────────────────────────────────────────┤
│ ICRC │
└─────────────────────────────────────────┘
RoCE的性能接近InfiniBand,但可以利用现有以太网基础设施。然而,以太网是丢包网络,而RDMA对丢包极其敏感。因此,RoCE网络需要配置为无损网络:
PFC(Priority Flow Control):在队列级别实现暂停机制,当接收端缓冲区快满时,发送PAUSE帧让发送端停止发送。
ECN(Explicit Congestion Notification):交换机在队列拥塞时标记ECN位,接收端收到后发送CNP(Congestion Notification Packet)通知发送端降速。
DCQCN(Data Center Quantized Congestion Notification):结合PFC和ECN的端到端拥塞控制算法,是RoCE v2的标准拥塞控制方案。
iWARP:RDMA over TCP/IP
iWARP选择了另一条路:将RDMA封装在标准TCP/IP协议中。它定义了三个子协议:
- MPA(Marker-based PDU Aligned Framing):在TCP流上划分消息边界
- DDP(Direct Data Placement):直接将数据放置到目标内存
- RDMAP(RDMA Protocol):提供RDMA语义
iWARP最大的优势是可以在任何IP网络上运行,不需要专用硬件或无损网络。但这也带来了代价:TCP的可靠传输机制引入了额外延迟,性能不如InfiniBand和RoCE。
三种协议的性能对比(典型值):
| 指标 | InfiniBand | RoCE v2 | iWARP |
|---|---|---|---|
| 延迟 | ~1μs | ~2μs | ~10μs |
| 带宽 | HDR 200Gbps | 100Gbps | 取决于TCP |
| 网络要求 | 专用IB网络 | 无损以太网 | 标准IP网络 |
| 部署成本 | 高 | 中 | 低 |
操作类型:单向操作与双向操作
RDMA支持两类操作模式,区别在于是否需要接收端参与。
双向操作:Send/Receive
Send/Receive是传统的消息传递模式:
- 发送端post一个Send请求到SQ
- 接收端必须预先post一个Receive请求到RQ
- 网卡将数据从发送端内存传输到接收端RQ指定的缓冲区
- 接收端收到完成通知
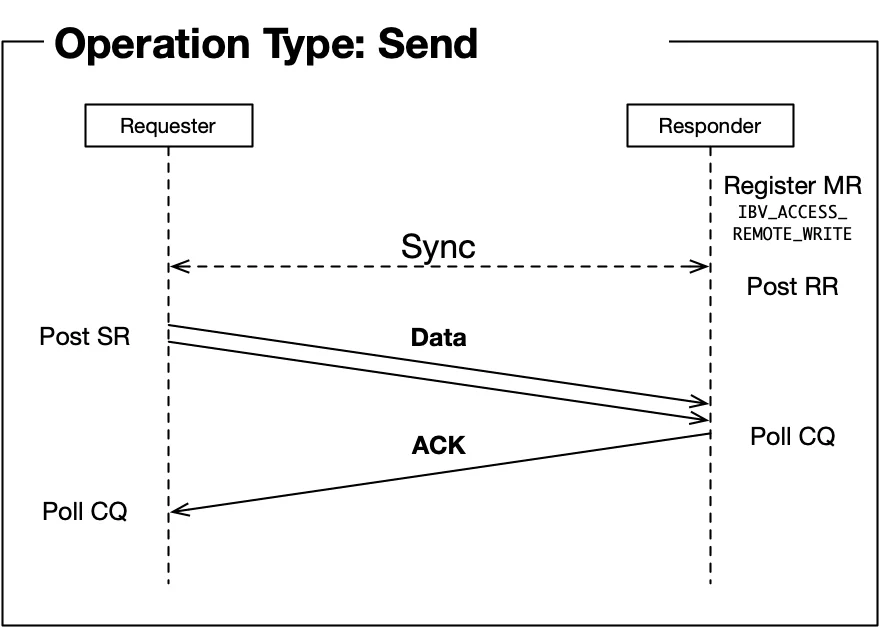
这种模式需要双方协调,适合请求-响应式通信。
单向操作:RDMA Read/Write
RDMA Read和Write是真正的"远程直接内存访问":
- 发送端直接读写远程内存
- 接收端完全不需要参与
- 发送端需要知道远程内存地址和rkey
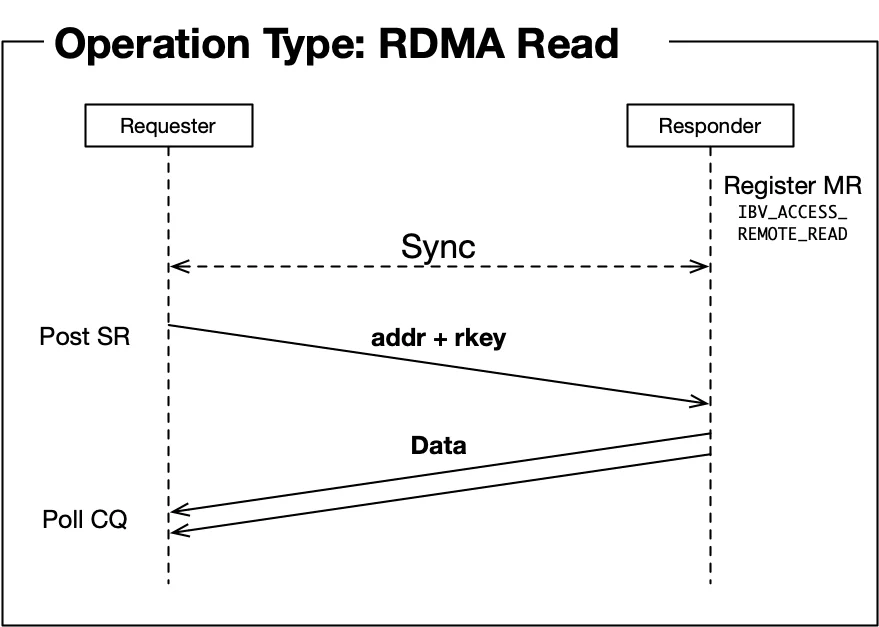
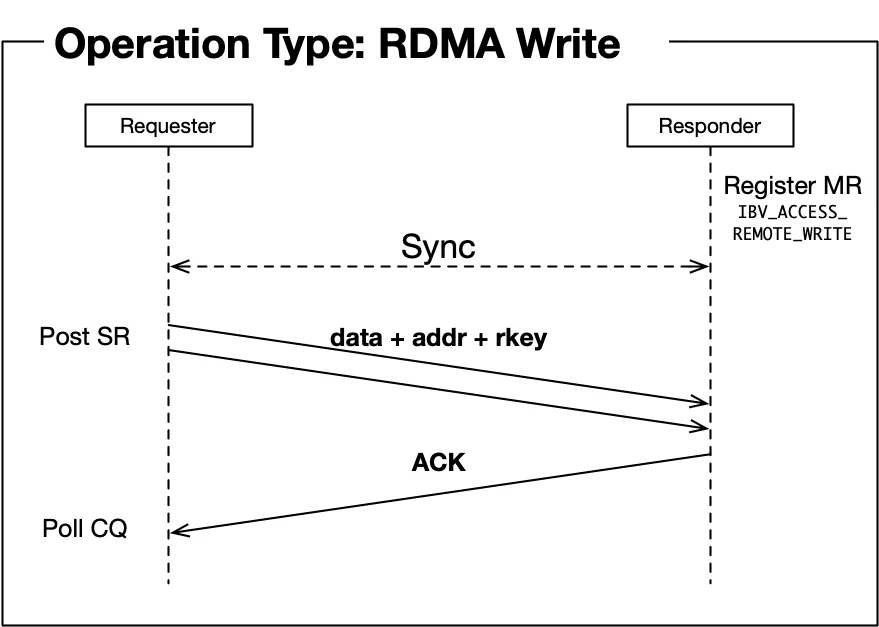
单向操作消除了接收端的协调开销,是高性能系统的首选。但发送端需要知道远程内存布局,这通常在初始化阶段通过控制通道交换。
// RDMA Write示例
struct ibv_send_wr wr;
memset(&wr, 0, sizeof(wr));
wr.opcode = IBV_WR_RDMA_WRITE;
wr.wr.rdma.remote_addr = peer_mr->addr; // 远程内存地址
wr.wr.rdma.rkey = peer_mr->rkey; // 远程内存key
wr.sg_list = &local_sge; // 本地数据源
wr.num_sge = 1;
ibv_post_send(qp, &wr, &bad_wr);
原子操作:CAS与FAA
RDMA还支持远程原子操作:
- Compare-and-Swap (CAS):原子地比较并交换内存值
- Fetch-and-Add (FAA):原子地增加内存值并返回旧值
这些操作对于实现分布式锁、无锁数据结构至关重要。
内存管理的挑战
RDMA的性能优势不是免费的,内存管理是最大的代价。
内存注册开销
注册内存是一个昂贵的操作。ibv_reg_mr()需要:
- 锁定所有物理页面(防止被换出)
- 建立虚拟地址到物理地址的映射表
- 将映射表加载到网卡
在Intel x86架构上,锁定内存需要修改页表项,这是一个串行操作。注册1GB内存可能需要数百毫秒。对于需要动态分配内存的应用,这个开销可能抵消RDMA的性能收益。
解决方案
内存池(Memory Pool):预注册大块内存,从中分配缓冲区。这是最常用的策略,HERD、FaRM等系统都采用这种方式。
按需注册(On-Demand Registration):仅在实际需要时注册内存,适用于工作负载不可预测的场景。
ODP(On-Demand Paging):现代网卡支持的特性,允许内存页面按需锁定,而不是一次性锁定整块内存。这减少了内存注册延迟,但可能引入运行时缺页处理开销。
实际应用:从AI训练到分布式存储
RDMA已经渗透到现代数据中心的核心基础设施。
AI训练:GPU间的快速通道
在大模型训练中,梯度同步是主要瓶颈。NCCL(NVIDIA Collective Communication Library)利用RDMA实现GPU间的高效通信:
- GPUDirect RDMA:网卡直接访问GPU内存,绕过系统内存
- NVLink:GPU间的高速互连,带宽可达900GB/s
- InfiniBand/RoCE:节点间通信,带宽可达400Gbps
Meta在SIGCOMM 2024发表的论文详细描述了其RoCE网络支持分布式训练的经验:在35,000个GPU的集群上,RDMA网络使训练吞吐量提升了约40%。
分布式存储:NVMe over Fabrics
NVMe-oF(NVMe over Fabrics)将本地NVMe的性能扩展到网络:
┌─────────────┐ RDMA Network ┌─────────────┐
│ Host │ ◄──────────────────► │ NVMe SSD │
│ Application │ │ Target │
└─────────────┘ └─────────────┘
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐
│ NVMe-oF │ │ NVMe-oF │
│ Initiator │ │ Target │
└─────────────┘ └─────────────┘
NVMe-oF over RDMA可以实现约10微秒的存储访问延迟,接近本地NVMe SSD的性能(约5-10微秒)。相比之下,NVMe-oF over TCP通常需要50-100微秒。
分布式数据库:FaRM的突破
微软研究院的FaRM系统展示了RDMA在分布式事务中的潜力。FaRM利用RDMA实现:
- 单向RDMA读取数据
- RDMA写入日志
- 原子操作实现锁
结果是惊人的:在90台机器的集群上,FaRM实现了每秒处理数千万个事务,比传统TCP/IP实现快一个数量级。
部署的权衡与挑战
RDMA不是银弹,部署时需要仔细权衡。
可扩展性问题
每个QP都会占用网卡的连接状态存储。当连接数达到数千时,网卡缓存可能成为瓶颈。对于需要大规模全连接的场景(如参数服务器),需要仔细规划QP数量或采用共享接收队列(SRQ)等技术。
无损网络的代价
RoCE要求无损网络,但这带来了连锁反应:
- PFC Head-of-Line阻塞:一个拥塞队列可能阻塞其他队列
- PFC风暴:PAUSE帧的级联传播可能导致整个网络停摆
- 配置复杂:需要在所有交换机和网卡上统一配置
编程复杂度
RDMA编程模型与传统socket编程完全不同:
- 异步操作模型
- 显式内存管理
- 连接状态机
- 错误处理更复杂
开发团队需要重新学习,调试也更具挑战性。
成本考量
InfiniBand交换机和线缆价格显著高于以太网设备。对于中小规模部署,ROI可能不划算。RoCE虽然可以使用标准以太网交换机,但支持PFC/ECN的高端交换机同样不便宜。
何时选择RDMA
RDMA适合以下场景:
- 网络延迟是核心瓶颈
- 高频次、小消息的通信模式
- CPU资源紧张,无法承担网络协议栈开销
- 可以接受内存预分配和注册的开销
- 有专业团队维护RDMA网络
不推荐RDMA的场景:
- 网络延迟已经足够(>100微秒可接受)
- 大块数据传输为主
- 连接数极度动态变化
- 团队缺乏RDMA运维经验
尾声
RDMA从1999年的InfiniBand Trade Association起步,经历了最初的市场冷遇、HPC领域的深耕、到如今AI时代的爆发。这项技术的本质没有变:让数据在网络中流动时绕过一切不必要的中间层。
当我们在100Gbps甚至400Gbps的网络环境中讨论微秒级延迟优化时,传统TCP/IP协议栈的开销已经无法忽视。RDMA不是万能的解决方案,但在正确的场景下,它能带来数量级的性能提升。理解RDMA的原理和权衡,是构建高性能分布式系统的基础。
参考资料
- InfiniBand Trade Association. InfiniBand Architecture Specification. 2000-2024.
- NVIDIA. RDMA Aware Networks Programming User Manual. 2011.
- Kalia et al. Design Guidelines for High Performance RDMA Systems. USENIX ATC 2016.
- Dragojević et al. FaRM: Fast Remote Memory. NSDI 2014.
- Kalia et al. Using RDMA Efficiently for Key-Value Services. SIGCOMM 2014.
- Bai et al. RDMA over Ethernet for Distributed Training at Meta Scale. SIGCOMM 2024.
- Zhu et al. Congestion Control for Large-Scale RDMA Deployments. SIGCOMM 2015.
- NVIDIA. GPUDirect RDMA Documentation. 2024.
- NVM Express. NVM Express RDMA Transport Specification. 2023.
- Jang, I. Introduction to Programming Infiniband RDMA. 2020.