归一化层的双重身份:为什么BatchNorm在训练和推理时判若两人
2017年,一个深度学习团队在部署图像分类模型时遇到了诡异的现象:模型在验证集上的准确率比训练时低了近5个百分点。他们检查了数据预处理、超参数设置、模型架构,一切看起来都正常。最后,一位细心的工程师发现了一个被忽视的细节——在验证循环中,他们忘记了调用model.eval()。 ...
2017年,一个深度学习团队在部署图像分类模型时遇到了诡异的现象:模型在验证集上的准确率比训练时低了近5个百分点。他们检查了数据预处理、超参数设置、模型架构,一切看起来都正常。最后,一位细心的工程师发现了一个被忽视的细节——在验证循环中,他们忘记了调用model.eval()。 ...
2019年某天凌晨三点,一位研究生的模型训练在运行72小时后突然输出全NaN。损失函数从平稳下降变成无穷大,权重变成NaN,一切归零。这是深度学习开发者的噩梦——数值不稳定。这不是偶然,而是浮点数表示固有的物理限制在特定条件下的必然爆发。 ...
一个看似简单的参数 当你第一次在API文档中看到seed参数时,可能会觉得它只是一个普通的整数。但这个看似简单的参数,却隐藏着大语言模型推理过程中最深层的随机性控制机制。 ...
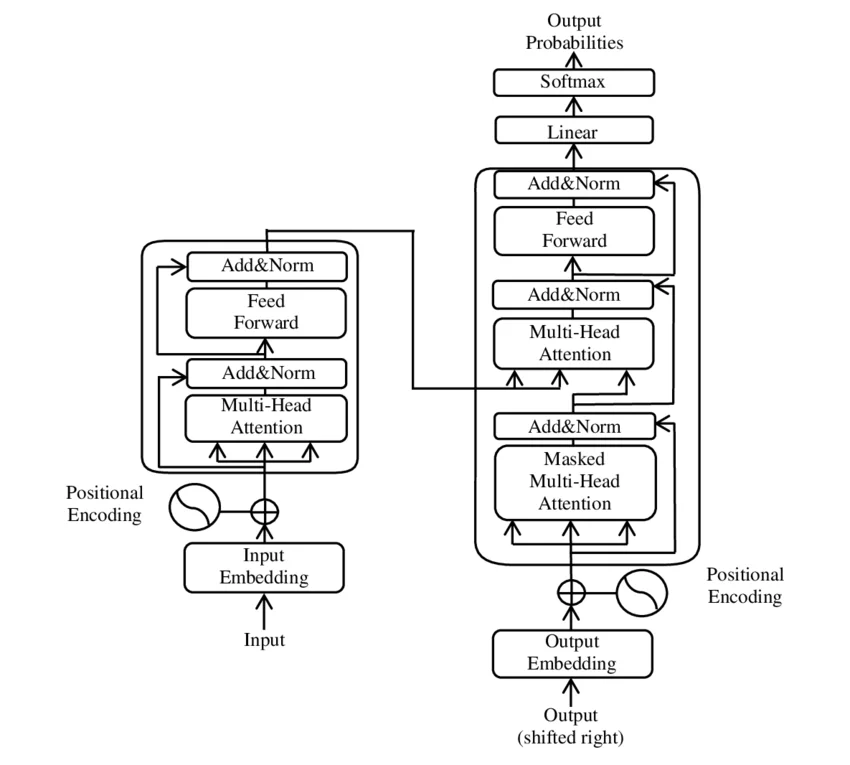
当你向一个大语言模型输入"今天天气怎么样",它在毫秒级别内就能返回一段流畅的回答。这个过程看似简单,背后却隐藏着一套精密的计算流程。输入的文本经历了分词、嵌入、多层Transformer处理、概率计算、采样选择等多个阶段,最终才能生成你所看到的每一个字符。 ...

一个困惑的起点 你问 GPT-4:“告诉我关于量子纠缠的事情”,它给你一段教科书式的定义。你换个说法:“量子纠缠到底有多诡异?能用通俗的方式解释吗?“回答变得生动有趣,甚至还用了比喻。 ...
你正在训练一个Transformer模型,Loss曲线稳定下降,一切看起来都很顺利。然后你决定启用混合精度训练来加速——只需一行代码.half()。100步之后:Loss: NaN。训练彻底崩溃。 ...
当你向一个大语言模型发送请求时,可能会注意到一个有趣的现象:第一个字蹦出来总是慢半拍,但随后的字却如流水般涌出。这种"先慢后快"的节奏并非偶然,而是大模型推理机制的根本特性。 ...