Teacher Forcing:为什么这个"作弊"技术统治了序列模型训练三十年
训练一个能够生成文本的模型,听起来是一个简单的任务:给它看很多文本,让它学会预测下一个词。但真正动手实现时,一个根本性的问题会摆在面前——训练时模型应该看到什么? ...
训练一个能够生成文本的模型,听起来是一个简单的任务:给它看很多文本,让它学会预测下一个词。但真正动手实现时,一个根本性的问题会摆在面前——训练时模型应该看到什么? ...
在深度学习的众多超参数中,batch size(批次大小)可能是最容易被忽视的一个。相比于学习率的精细调节、模型架构的反复打磨,batch size的选择往往只遵循一个简单的规则:在显存允许的范围内,尽量设大。 ...
从一个问题说起 如果你问一位NLP研究者:“为什么GPT选择了Decoder-only架构,而BERT选择了Encoder-only?“答案可能涉及双向注意力、因果掩码、预训练目标……但如果你追问:“那为什么现在的千亿参数大模型几乎清一色是Decoder-only?“很多人可能就说不清楚了。 ...

一个困惑的起点 你问 GPT-4:“告诉我关于量子纠缠的事情”,它给你一段教科书式的定义。你换个说法:“量子纠缠到底有多诡异?能用通俗的方式解释吗?“回答变得生动有趣,甚至还用了比喻。 ...
你正在训练一个Transformer模型,Loss曲线稳定下降,一切看起来都很顺利。然后你决定启用混合精度训练来加速——只需一行代码.half()。100步之后:Loss: NaN。训练彻底崩溃。 ...
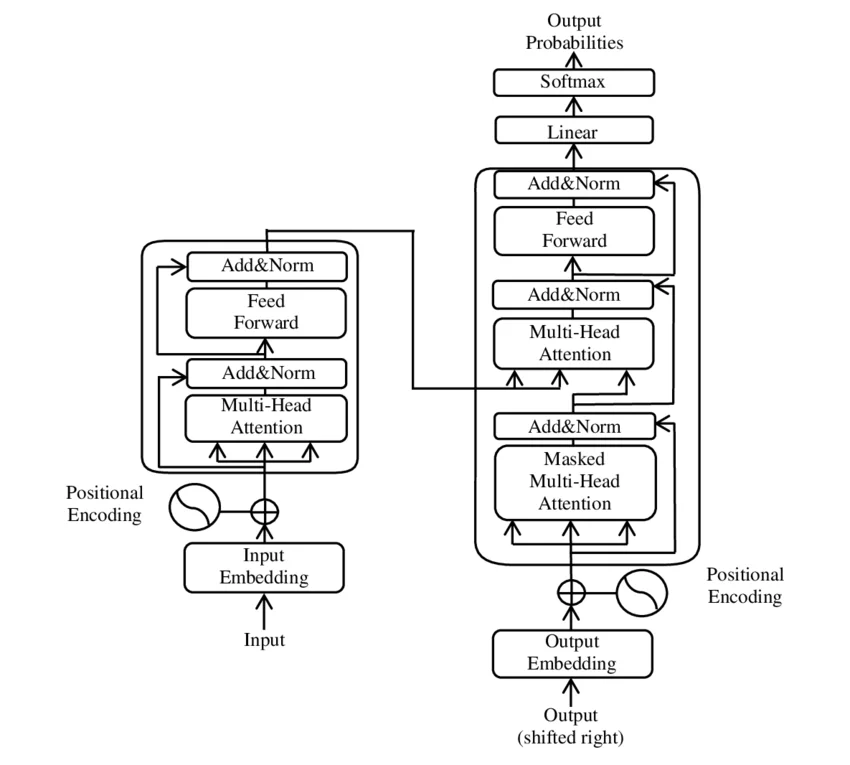
2017年,Google Research 团队发表论文《Attention Is All You Need》,提出了一种名为 Transformer 的神经网络架构。论文标题是一个明确的判断——在此之前的神经机器翻译模型依赖于循环神经网络(RNN)和卷积神经网络(CNN)的组合,而 Transformer 仅使用注意力机制就达到了当时的最优性能。 ...

每个使用过大语言模型 API 的人都会遇到一个名为 Temperature 的参数。大多数时候,我们要么忽略它,要么随意调一下。但这个看似简单的数字,实际上决定了模型是"一本正经"还是"天马行空"。 ...