1975年,贝尔实验室的Stephen Johnson做出了一个决定:将C编译器从手写递归下降解析器切换到DeRemer的LALR算法。这是Unix历史上第一次大规模采用自动生成的解析器。然而不到二十年,GCC项目反其道而行之,重新改用手写解析器。Clang紧随其后。直到今天,几乎所有主流编译器——GCC、Clang、V8、Lua——都使用手写递归下降解析器。为什么解析器生成器在工业界遭遇滑铁卢?这场跨越半个世纪的"代际战争"背后,隐藏着怎样的技术权衡?
词法分析的第一道坎:正则引擎的性能鸿沟
在谈论语法分析之前,必须先理解词法分析器(Lexer)的核心——正则表达式引擎。这是编译器理解源代码的第一步,也是性能差异最惊人的地方。
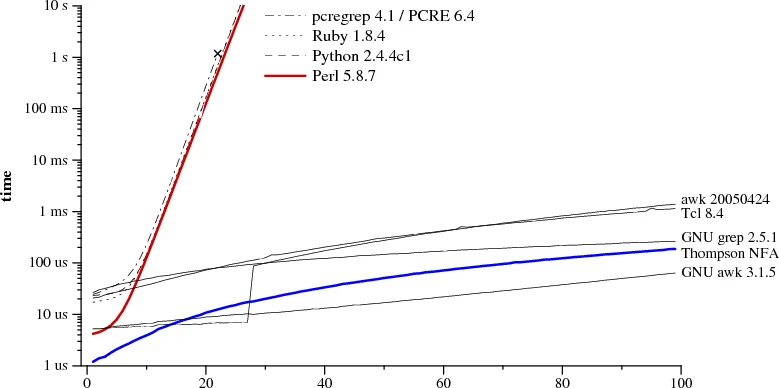
2007年,Russ Cox发表了一篇震撼性的文章。他比较了两种正则引擎实现:一种是Perl、Python、Ruby等主流语言使用的回溯引擎,另一种是Ken Thompson在1968年提出的NFA模拟算法。测试用例很简单:正则表达式a?^n a^n匹配字符串a^n(其中^n表示重复n次)。
结果令人咋舌。当n=29时,Perl需要超过60秒才能完成匹配,而Thompson NFA只需要20微秒——相差三百万倍。这不是笔误:Perl的时间单位是秒,Thompson NFA的时间单位是微秒。当n=100时,Thompson NFA在200微秒内完成,而Perl需要超过$10^{15}$年。
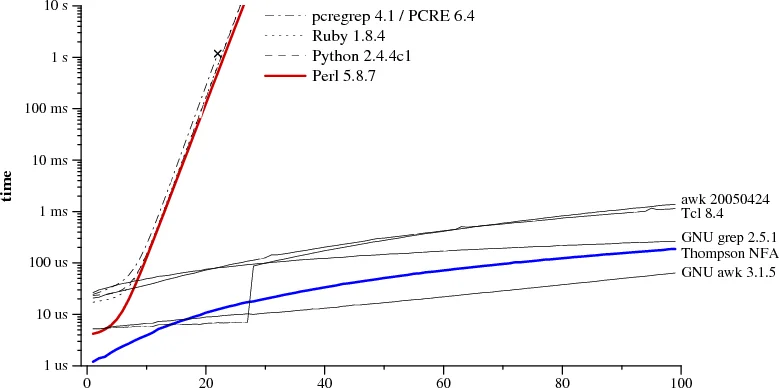
图片来源: Russ Cox, “Regular Expression Matching Can Be Simple And Fast”
为什么差距如此巨大?
NFA与DFA:两种根本不同的实现路径
要理解这个差距,需要回到理论计算机科学的基础。正则表达式可以转换为两种有限状态自动机:确定性有限自动机(DFA)和非确定性有限自动机(NFA)。
DFA在任何状态下,对于每个输入字符都有且仅有一个转移。NFA则允许在某个状态下对同一输入字符有多个可能的转移,甚至可以在不读取任何输入的情况下跳转到其他状态(ε转移)。
Ken Thompson的天才之处在于,他发明了一种将正则表达式直接转换为NFA的算法——每个正则表达式的字符或元字符对应NFA中的一个状态。然后,他用一种巧妙的方法模拟NFA:不是猜测应该走哪条路,而是同时跟踪所有可能的状态。
// Thompson NFA的核心数据结构
struct State {
int c; // 字符或Split/Match
State *out; // 转移目标
State *out1; // Split状态的第二个转移
int lastlist; // 用于避免重复添加
};
关键洞察是:NFA的状态数与正则表达式长度成正比。在模拟过程中,我们维护一个当前状态集合,每个字符处理时,集合大小最多为NFA的状态数。因此,对于长度为m的正则表达式和长度为n的文本,Thompson算法的时间复杂度是$O(mn)$。
回溯引擎则完全不同。它实现的是深度优先搜索:在遇到选择时,先尝试第一条路径,失败则回溯尝试第二条。对于a?^n a^n这样的表达式,选择数量是$2^n$,导致指数级时间复杂度。
回溯引擎为何统治世界?
既然Thompson算法如此高效,为什么主流语言都选择了回溯引擎?
答案在于功能。Thompson算法只支持纯正则表达式——不包含反向引用(backreference)等扩展特性。反向引用允许匹配之前捕获的组,如(cat|dog)\1只能匹配catcat或dogdog。这超出了正则语言的表达能力,Thompson算法无能为力。
回溯引擎虽然慢,但功能丰富。1990年代的Perl将正则表达式推向了实用化,程序员习惯了这些便利特性。性能问题?大多数情况下"够用"就行。
直到今天,情况开始改变。Google的RE2库重新实现了Thompson算法(加上一些优化),在某些场景下比PCRE快1000倍。Rust的regex库也采用类似方法。这些现代实现证明:你不需要牺牲太多功能来换取性能。
语法分析的范式分裂:LL vs LR
词法分析器将源代码切割成token流,语法分析器则根据语法规则构建结构。这里,计算机科学经历了更深刻的分裂:LL与LR两大阵营。
从波兰表达式说起
理解LL和LR的区别,有一个非常直观的视角:波兰表达式与逆波兰表达式。
中缀表达式1 + 2 * 3可以用三种方式表示:
- 中缀(infix):
1 + 2 * 3——中序遍历 - 前缀(Polish):
+ 1 * 2 3——前序遍历 - 后缀(Reverse Polish):
1 2 3 * +——后序遍历
对应到解析器,Josh Haberman提出了一个关键洞察:LL解析器输出前序遍历,LR解析器输出后序遍历。
这解释了为什么LL解析器也被称为"预测解析器"——它在解析开始前就必须预测应该使用哪条规则。LR解析器则被称为"移进-归约解析器"——它等到看到完整结构后才决定如何归约。
前瞻能力的根本差异
这个差异导致了前瞻(lookahead)能力的根本不同。
LL解析器在规则开始处做出决策,只能看到规则的前几个token。LR解析器在规则结束时做出决策,可以看到规则的最后一个token以及之后的若干token。
这就是为什么存在LR(0)解析器——不需要前瞻就能做出决策——而LL(0)解析器根本不可能存在。LR(1)解析器能处理的文法严格包含LL(1)能处理的文法。
更具体地说,LR解析器可以自然地处理左递归:
E → E + T | T
LL解析器会陷入无限递归。必须改写为:
E → T E'
E' → + T E' | ε
这种改写不仅繁琐,还导致语法树结构不够直观。
LL解析器的反击:灵活性与可读性
既然LR在理论上更强大,为什么还有人选择LL?
因为LL解析器有一个LR无法比拟的优势:解析过程与语法规则直接对应。手写递归下降解析器本质上就是LL解析器——每个非终结符对应一个函数:
def parse_expression():
left = parse_term()
while current_token == '+':
consume('+')
right = parse_term()
left = BinaryOp('+', left, right)
return left
这种一一对应关系带来了几个好处:
-
错误诊断友好:当解析失败时,LL解析器知道自己正在尝试匹配哪个规则,可以给出精确的错误位置和期望的token。
-
支持丰富的语法扩展:LL解析器可以在规则中嵌入正则表达式式的操作符,如重复
*、可选?等。ANTLR支持这种扩展语法,因为解析器知道当前上下文,可以动态决策。 -
继承属性:LL解析器可以将信息向下传递给子规则,这在语义分析中非常有用。LR解析器只能向上传递信息。
性能对比:理论与现实
理论上,LL和LR解析器都是线性时间复杂度$O(n)$。但实际实现差异很大。
LR解析器使用状态表驱动,查表时间是常数。但状态表可能非常大——对于复杂的编程语言语法,LALR(1)表可能有数千个状态。
LL解析器(特别是手写递归下降)需要函数调用开销。但现代编译器的优化可以将其大部分消除。更重要的是,手写解析器可以根据语言特性进行针对性优化。
2013年,Terence Parr等人在论文中提出了ALL(*)算法,用于ANTLR 4。这是一种自适应LL解析器,在解析时动态构建前瞻DFA。理论上最坏情况是$O(n^4)$,但实际测试中几乎所有真实语法都是线性时间。
解析器生成器的兴衰
Yacc时代:LALR的黄金岁月
1970年代,Stephen Johnson在贝尔实验室开发了Yacc(Yet Another Compiler Compiler)。它使用LALR(1)算法——一种简化的LR(1),通过合并相似状态来减小表的大小。
Yacc的成功有几个原因:
- 理论基础扎实:LALR能处理大多数编程语言语法,包括C。
- 工具链完整:Yacc与Lex(词法分析器生成器)配合,形成了完整的编译器前端工具链。
- Unix普及:Yacc随Unix传播,成为一代程序员的标配工具。
GNU的Bison是Yacc的开源版本,至今仍在维护。但Yacc/Bison有一个致命弱点:错误处理。
错误处理的噩梦
Yacc的错误处理机制相当原始。它使用特殊的errortoken标记错误恢复点:
statement: expr ';'
| error ';' { yyerrok; }
当遇到错误时,Yacc会丢弃输入直到遇到分号,然后尝试恢复。这种方式的问题在于:
- 恢复点难以预测:程序员需要精心设计每个规则的恢复策略。
- 错误信息质量差:Yacc通常只能报告"syntax error",无法指出期望的token。
- 级联错误:恢复失败可能导致一连串虚假错误。
手写解析器可以做得更好。Clang的错误信息是业界标杆,因为它可以追踪更多上下文:
test.c:5:7: error: expected ';' after expression
int x = 5
^
;
这种精确的错误定位和恢复建议,是自动生成器难以达到的。
ANTLR的LL(*)革命
Terence Parr在1980年代末开始开发ANTLR。最初使用LL(k)算法,但发现k固定限制了表达能力。2000年代,他提出了LL(*)——动态计算需要多少前瞻。
LL(*)的核心思想是:对于每个决策点,构建一个前瞻DFA。如果当前前缀能确定选择,就继续;否则可能需要回溯。
ANTLR 4的ALL(*)更进一步。它不再预先计算前瞻DFA,而是在解析时动态构建。这使得ANTLR能处理几乎所有非左递归的上下文无关文法。
更重要的是,ANTLR提供了极佳的错误信息:
line 3:10 mismatched input '}' expecting ')'
它还能自动生成语法图和解析树可视化工具,极大提升了开发体验。
主流编译器的选择:为什么手写胜出
GCC:从Yacc到手写的回归
GCC最初使用Yacc生成解析器。1990年代末,项目决定重写。原因有几个:
-
C++的复杂性:C++语法极其复杂,包含大量上下文依赖。
a < b > c是模板还是比较表达式?需要语义信息才能判断。Yacc无法处理这种歧义。 -
错误信息质量:GCC希望提供更好的错误诊断,这需要解析器维护更多上下文信息。
-
性能:手写解析器可以针对C/C++特性优化,避免通用解析器的开销。
重写过程耗时数年,但结果是值得的。现代GCC的错误信息质量远超早期版本。
Clang:从头设计
Clang从2005年开始设计,一开始就选择了手写递归下降解析器。设计者Chris Lattner和团队有几个明确目标:
-
编译速度:Clang的设计目标之一是比GCC快。手写解析器可以精细控制内存分配和函数调用。
-
错误信息:Clang希望提供最好的错误诊断。手写解析器可以在任何位置保存上下文,生成精确的错误信息。
-
IDE集成:Clang需要支持增量解析和语义高亮。手写解析器更容易扩展这些功能。
结果证明选择正确。Clang的编译速度比GCC快2-3倍,错误信息质量更是业界标杆。
V8和SpiderMonkey:JavaScript的挑战
JavaScript引擎面临一个特殊挑战:代码可能在解析完成前就开始执行。ES6引入了块级作用域,但var声明会被提升。这意味着解析器需要处理部分语义信息。
V8使用手写递归下降解析器,预解析(pre-parsing)顶层代码,只解析被调用的函数。这种惰性解析策略显著减少了启动时间。
SpiderMonkey(Firefox的JS引擎)同样使用手写解析器。它甚至可以在解析时生成字节码,进一步优化执行速度。
PEG与Parser Combinator:函数式编程的答案
解析表达式文法(PEG)
2004年,Bryan Ford提出了解析表达式文法(Parsing Expression Grammar)。PEG与上下文无关文法(CFG)有根本不同:CFG使用无序选择,PEG使用有序选择。
// CFG: 无序选择,可能歧义
E → E + E | E * E | number
// PEG: 有序选择,无歧义
E <- E + E / E * E / number
有序选择意味着PEG永远不会有歧义——第一个匹配的选择胜出。这简化了解析器实现,但也带来问题:选择顺序会影响语言。
PEG通常用Packrat算法实现——一种带记忆化的递归下降。记忆化保证线性时间$O(n)$,但需要$O(n)$空间存储记忆表。
Python从3.9版本开始使用PEG解析器,替代了之前的LL(1)解析器。这允许Python语法更加灵活,比如walrus operator :=的引入。
Parser Combinator:组合的力量
Parser Combinator是函数式编程的产物,最早由Philip Wadler在1989年提出。核心思想是将解析器表示为函数,通过组合构建复杂解析器。
-- 基础解析器
char :: Char -> Parser Char
string :: String -> Parser String
-- 组合器
(<|>) :: Parser a -> Parser a -> Parser a -- 选择
(<*>) :: Parser (a -> b) -> Parser a -> Parser b -- 序列
many :: Parser a -> Parser [a] -- 重复
-- 示例:解析表达式
expr = term `chainl1` addop
term = factor `chainl1` mulop
factor = parens expr <|> number
Haskell的Parsec库是Parser Combinator的经典实现。Scala的标准库也包含Parser Combinator。
Parser Combinator的优势在于表达力和可组合性。你可以像搭积木一样构建解析器。劣势是性能——记忆化导致空间开销,递归可能导致栈溢出。
现代的Parser Combinator实现做了很多优化。Rust的nom库使用宏在编译时生成代码,避免了运行时开销。TypeScript的Chevrotain使用LL(k)算法,支持无限前瞻。
广义解析:当确定性不够用
有些语言的语法天生就是歧义的。C++的类型解析就是经典例子:
a < b > c; // 是模板还是比较?
这需要语义信息才能判断。传统的LL/LR解析器无法处理。
GLR:LR的泛化
1984年,Masaru Tomita提出了广义LR(GLR)解析器。当遇到移进-归约或归约-归约冲突时,GLR解析器分裂成多个解析实例,每个实例尝试一种可能。
GLR可以处理任意上下文无关文法,包括歧义文法。时间复杂度最坏是$O(n^3)$,但对于大多数实用语法是线性的。
GLR的主要应用是自然语言处理和复杂编程语言。GCC的C++解析器使用了类似GLR的技术处理模板歧义。
GLL:LL的泛化
GLL是GLR的LL对应物,由Elizabeth Scott和Adrian Johnstone在2010年提出。它保持了递归下降的直观性,同时能处理歧义。
GLL解析器维护一个描述符(descriptor)集合,每个描述符代表一个可能的解析状态。解析过程是广度优先的,避免了深度优先的回溯开销。
GLL的优势在于实现简洁。相比GLR复杂的状态表,GLL更接近手写递归下降解析器的结构。
现代解析器的工程实践
分离扫描与解析的边界
传统编译器教程将词法分析和语法分析严格分离。但现代实践更灵活。
Scannerless parsing将词法和语法统一到一个文法中。这种方法可以更精确地处理关键字、操作符的优先级,以及上下文敏感的词法规则。
GLR解析器常使用scannerless方法,因为它能处理词法歧义。比如,在C++中,>>可能是右移操作符,也可能是嵌套模板的结束符。
错误恢复策略
现代编译器通常使用混合策略:
-
Panic mode:跳过输入直到遇到同步token(如分号、右括号)。简单但粗暴。
-
Phrase level recovery:尝试插入或删除token来修复错误。比如,如果期望
;但遇到},插入;继续。 -
Error productions:在语法中明确包含错误形式。
statement: error ';'告诉解析器遇到错误后如何恢复。 -
Partial AST:即使遇到错误,也尝试构建尽可能多的语法树。这对于IDE的实时诊断非常重要。
Clang使用了复杂的错误恢复策略,能够在大多数情况下继续解析并提供有用的诊断信息。
增量解析
IDE需要实时响应代码变化。重新解析整个文件太慢。
增量解析器只重新解析变化的部分,然后尝试合并到已有的语法树中。这需要解析器能够标记语法树的边界,并在边界处正确处理上下文。
Tree-sitter是增量解析器的代表。它使用GLR算法,能够在毫秒级响应用户输入。Atom、Neovim、Emacs都使用Tree-sitter进行语法高亮和代码分析。
性能数据的真相
让我们看一些真实世界的性能数据。
正则引擎对比
Rust Leipzig在2017年进行了一次正则引擎基准测试,测试了12个引擎在54个测试用例上的表现:
| 引擎 | 总时间 | 排名 |
|---|---|---|
| Hyperscan | ~300ms | 1 |
| RE2 | ~1s | 2 |
| Rust regex | ~1.5s | 5 |
| PCRE | ~2s | 6 |
| Python re | ~5s | 9 |
注意PCRE在某些"病态"用例上会超时。RE2和Rust regex在所有用例上都保持线性时间。
解析器生成器对比
2018年,有研究比较了不同解析器在Java语法上的性能:
| 解析器 | 时间 | 内存 |
|---|---|---|
| 手写(Java编译器) | 基准 | 基准 |
| ANTLR 4 (ALL(*)) | 1.5x | 2x |
| Bison (LALR) | 1.2x | 0.5x |
| Parsec (Combinator) | 3x | 4x |
手写解析器仍然是最快的。ANTLR在易用性和性能之间取得了很好的平衡。Parser Combinator由于记忆化开销,性能较差。
没有银弹:如何选择解析技术
经过六十年的演进,解析器领域没有产生一个万能的解决方案。每种技术都有其适用场景:
选择词法分析器
-
追求极致性能:使用Thompson NFA实现(RE2、Rust regex)。适合日志处理、文本搜索等场景。
-
需要丰富特性:回溯引擎(PCRE、Python re)更灵活。但要注意避免病态正则表达式。
-
嵌入到解析器中:考虑Scannerless parsing,如SDF3/JSGLR。
选择语法分析器
-
简单DSL:Parser Combinator(nom、Parsec)表达力强,开发快。
-
标准编程语言:ANTLR提供良好的开发体验和合理的性能。
-
复杂语言(C++):手写解析器或GLR,能处理歧义和上下文依赖。
-
IDE支持:增量解析器(Tree-sitter)或设计时就考虑增量解析的架构。
性能与开发效率的权衡
手写解析器性能最好,但开发成本高。一个复杂语言的手写解析器可能需要数万行代码。
解析器生成器降低了门槛,但牺牲了一些控制力。错误信息质量是一个常见的痛点。
现代趋势是混合方案:生成基础框架,手动添加特殊处理。ANTLR允许嵌入动作代码,Tree-sitter允许自定义外部扫描器。
六十年演进的启示
从Ken Thompson 1968年的NFA算法,到今天的增量解析器,解析技术走过了漫长的道路。回顾这段历史,有几点启示:
理论先行,实践跟进。Thompson NFA、LR解析、PEG——这些技术都是先有理论突破,再经过多年才被工业界广泛采用。Rust regex证明了优秀的算法设计可以带来数量级的性能提升。
权衡是永恒的主题。没有免费午餐。DFA快但内存大,NFA省内存但慢。LL直观但能力弱,LR强大但复杂。选择技术时,必须明确优先级。
工具链决定生产率。ANTLR的成功不仅在于算法,还在于完善的工具链——语法检查、可视化、多语言后端。Tree-sitter的成功在于它解决了IDE的实时解析需求。
错误处理是被低估的能力。解析器不仅要能解析正确代码,还要能优雅地处理错误代码。这往往比解析正确代码更难。
主流编译器选择手写解析器,不是因为他们不知道解析器生成器的存在,而是经过深思熟虑的技术决策。在性能、错误处理、灵活性的三维空间中,手写解析器占据了独特的位置。
但这不意味着解析器生成器无用。对于大多数开发者,ANTLR、Tree-sitter等工具提供了很好的性价比。重要的是理解每种技术的边界,在合适的场景做出合适的选择。