一个电商平台在双十一期间需要处理数百万个订单超时取消任务。每个订单创建后30分钟未支付就需要自动取消,释放库存。最直观的实现方式是在数据库中存储订单的创建时间,然后启动一个定时任务每隔几秒扫描一次,找出所有超时的订单。
这个方案在订单量小时运行良好,但当订单量增长到百万级别时,问题开始显现。每次扫描都需要执行一条类似SELECT * FROM orders WHERE status = 'pending' AND created_at < NOW() - INTERVAL 30 MINUTE的查询。随着pending状态订单的累积,这条查询的执行时间会越来越长。更糟糕的是,扫描间隔和扫描耗时之间存在一个两难选择:间隔太短会频繁冲击数据库,间隔太长又会延迟超时订单的处理。
这不是一个新问题。1987年,George Varghese和Tony Lauck在ACM Symposium on Operating Systems Principles(SOSP)上发表了一篇题为《Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facility》的论文,系统地解决了这个问题。这篇论文提出的"时间轮"算法,能够以O(1)的时间复杂度插入、删除定时器,彻底改变了大规模定时任务处理的格局。
为什么传统方案不够用
理解时间轮的优势,需要先理解传统方案的性能瓶颈。
数据库轮询的代价
数据库轮询方案的核心问题是"无效工作"比例过高。假设订单超时时间为30分钟,系统每秒创建100个订单,扫描间隔为1秒。每次扫描时,大部分订单的剩余时间都在29分钟以上,只有极少数订单真正到期。但扫描必须检查所有pending状态的订单,即使它们99%都不会被处理。
更深层的问题是时间复杂度。假设有N个待处理的定时任务,数据库轮询方案的扫描复杂度是O(N)。当N从1000增长到1000000时,扫描耗时会相应增长1000倍。这种线性增长在大规模系统中是不可接受的。
最小堆的局限
数据库轮询的问题在于无法快速找到最早到期的任务。一个自然的改进是使用最小堆(Min Heap)来维护所有定时任务,堆顶元素就是最早到期的任务。
插入一个新任务的时间复杂度是O(log N),删除一个任务的时间复杂度也是O(log N)。查找最早到期任务的时间复杂度是O(1)。这比数据库轮询好得多,但当N达到百万级别时,O(log N)仍然意味着每次操作需要执行约20次比较。
Java的DelayQueue就是基于PriorityQueue(最小堆)实现的。在并发场景下,DelayQueue还使用了Leader-Follower模式来优化多线程竞争,但O(log N)的时间复杂度无法改变。
更重要的是,网络协议实现中大量定时器的特点是:绝大多数定时器会在到期前被取消。TCP连接的重传定时器、HTTP请求的超时定时器,在正常情况下都会在数据到达后被取消。对于这种"大量创建、大量取消"的场景,最小堆的O(log N)删除成本累积起来会变得非常显著。
时间轮:用空间换时间
Varghese和Lauck的核心洞察是:对于定时器操作,时间复杂度比空间复杂度更重要。他们设计了一种数据结构,用更多的空间来换取O(1)的操作时间复杂度。
简单时间轮的工作原理
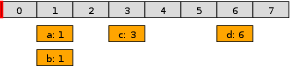
想象一个时钟表盘,被分成8个刻度。每个刻度对应一个时间槽位,存储着在该时刻需要执行的任务列表。一个指针每过一个时间单位就向前移动一个刻度。

图片来源: www.snellman.net
{kind=link}
假设当前指针指向刻度0,时间分辨率为1毫秒,轮子大小为8个刻度。这意味着这个时间轮可以处理未来8毫秒内的定时任务。
当需要添加一个3毫秒后执行的任务时,只需要计算它应该在哪个槽位:(当前指针位置 + 延迟时间) % 轮子大小 = (0 + 3) % 8 = 3,然后将任务添加到刻度3对应的任务列表中。这个操作的时间复杂度是O(1)。
当指针移动到某个刻度时,执行该刻度对应的所有任务,然后清空该槽位。这个槽位现在可以复用于下一轮——原本代表"3毫秒后"的刻度,现在代表"11毫秒后"。

图片来源: www.snellman.net
{kind=link}
删除一个任务同样简单:每个任务对象维护一个指向自己在链表中位置的引用,删除时只需要O(1)的链表操作。
简单时间轮的局限
简单时间轮有一个明显的问题:它只能处理有限时间范围内的定时任务。一个大小为8的时间轮,时间分辨率为1毫秒,最多只能处理未来8毫秒内的任务。
对于超过8毫秒的任务怎么办?一个直观的想法是增大轮子大小。如果要支持未来24小时的定时任务,以1毫秒为分辨率,需要86400000个槽位。这显然不现实。
层级时间轮:解决时间范围问题
Varghese和Lauck提出的层级时间轮(Hierarchical Timing Wheel)巧妙地解决了这个问题。核心思想是:不同时间尺度的任务使用不同精度的时间轮。
多层时间轮的协作
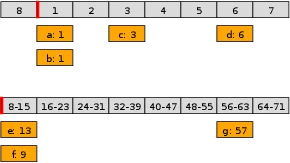
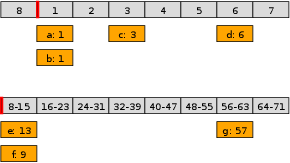
想象一个多层次的时钟系统。最内层是一个大小为8、分辨率为1毫秒的时间轮,可以处理未来8毫秒的任务。第二层是一个大小为8、分辨率为8毫秒的时间轮,可以处理未来64毫秒的任务。第三层分辨率为64毫秒,可以处理未来512毫秒的任务。依此类推。
图片来源: www.snellman.net
{kind=link}
当一个100毫秒后执行的任务到达时,它会被放入第三层时间轮的某个槽位。当第二层时间轮的指针移动时,会将对应槽位中的任务"降级"到第一层时间轮中,这个过程称为"级联"(Cascade)。
更优雅的设计——也是Kafka采用的设计——是直接在高层级执行任务,而不是级联到低层级。Linux内核在2015年重新设计时间轮时也采用了类似的思想。这种设计牺牲了一些时间精度,但避免了级联操作的开销。
时间复杂度的保证
层级时间轮的插入操作时间复杂度取决于需要经过多少层级。假设有m个层级,插入一个任务的复杂度是O(m)。由于m通常是固定的(比如Kafka使用3层),这可以视为O(1)常数时间。
删除操作的时间复杂度是O(1),因为每个任务都维护着指向自己在链表中位置的引用。
这与最小堆的O(log N)形成了鲜明对比。当N从1000增长到1000000时,最小堆的操作次数从约10次增长到约20次,而时间轮的操作次数保持不变。
Kafka的工程实践
Apache Kafka可能是时间轮算法最著名的工业应用。Kafka需要处理大量异步请求的超时:生产者请求需要等待副本同步完成,消费者请求需要等待新数据到达。这些请求通常会在超时前完成,但系统必须能够高效地管理数万个并发的超时定时器。
旧设计的问题
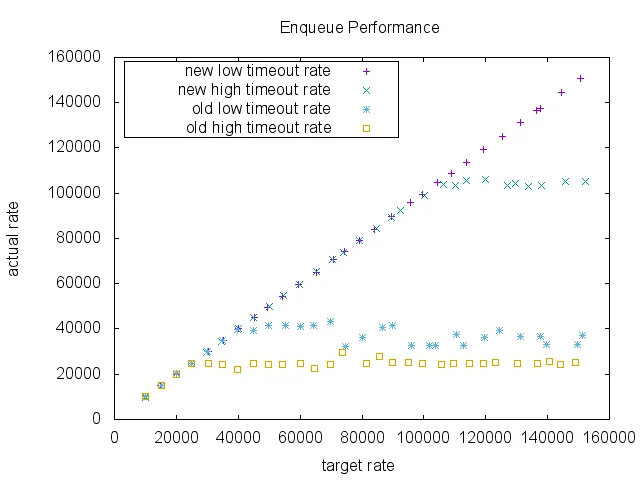
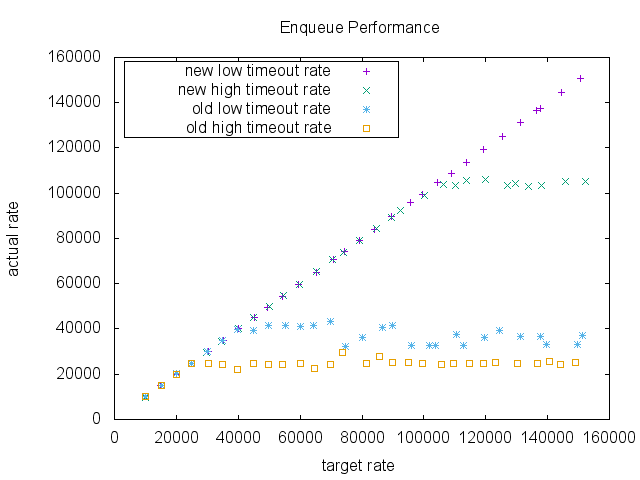
Kafka早期版本使用Java的DelayQueue来实现超时管理。当请求量增长时,性能问题开始显现。在高超时率场景下(大部分请求都超时而不是提前完成),旧实现只能处理约25000 RPS(每秒请求数),之后就出现性能瓶颈。
问题的根源是DelayQueue的O(log N)复杂度,以及完成请求后从队列中删除的成本。当大量请求提前完成(未超时)时,删除操作累积的成本会变得很高。
层级时间轮的实现
Kafka的新实现采用了层级时间轮,具体配置为:
- 第一层:分辨率1毫秒,大小20个槽位,覆盖范围20毫秒
- 第二层:分辨率20毫秒,大小20个槽位,覆盖范围400毫秒
- 第三层:分辨率400毫秒,大小20个槽位,覆盖范围8秒
对于超过8秒的超时,Kafka使用一个单独的溢出列表。
一个关键的创新是使用DelayQueue来驱动时间轮的转动。每个时间轮槽位作为一个元素放入DelayQueue,当槽位的到期时间到达时,DelayQueue会通知时间轮执行该槽位中的所有任务。这样,时间轮不需要一个独立的线程来不断轮询,而是按需被唤醒。
性能提升
基准测试结果令人印象深刻。在高超时率场景下,新实现达到了105000 RPS,是旧实现的4倍以上。更重要的是,CPU使用率显著降低,GC压力也减轻了。
图片来源: cdn.confluent.io
{kind=link}
Netty的HashedWheelTimer
Netty是一个高性能的网络框架,需要处理大量连接的超时管理。Netty实现了自己的HashedWheelTimer,这是时间轮算法的一个简化版本。
设计权衡
Netty的时间轮是单层的,不支持层级扩展。默认配置是100毫秒的tick持续时间,512个槽位。这意味着它可以处理未来51.2秒内的定时任务,但时间精度只有100毫秒。
这个设计反映了Netty的使用场景:网络超时通常在秒级,不需要毫秒级的精度。更重要的是,Netty的设计哲学是"用精度换性能"——在网络编程中,一个超时检测晚100毫秒执行通常是可以接受的,但每秒处理数万个超时检测的能力是必须的。
使用注意
Netty的文档中特别强调了时间轮的精度问题。一个设置了500毫秒超时的任务,实际执行时间可能在500-600毫秒之间,取决于指针何时经过对应的槽位。这种精度损失在高性能网络框架中是一个合理的权衡。
Linux内核的时间轮演进
Linux内核的时间管理是时间轮算法的另一个重要应用。有趣的是,Linux内核在2015年经历了一次时间轮的重新设计。
旧时间轮的问题
Linux内核从2005年开始使用一种层级时间轮来管理系统定时器。旧设计使用了不同大小的层级(256个槽位的第一层,64个槽位的第二层等),并依赖"级联"操作将高层级的任务移动到低层级。
级联操作的问题是它的执行时间是不可预测的。当内核需要执行级联时,可能需要处理大量任务,导致延迟峰值。这对于实时性要求高的系统是不可接受的。
新设计:用精度换确定性
Thomas Gleixner在2015年提出了新的时间轮设计。新设计的核心变化是:
- 所有层级使用相同大小(32个槽位)
- 高层级的任务直接在高层级执行,不再级联到低层级
- 高层级的任务执行精度降低,但执行时间是可预测的
例如,一个设置在1分钟后的定时器,在新设计中可能会在指定时间的±4分钟内执行,但它的执行成本是确定的、低延迟的。
这个设计反映了内核开发者的一个重要洞察:定时器的核心使用场景是"超时检测",而超时检测不需要毫秒级的精度。一个网络超时设置为30秒,实际在30.1秒或29.9秒检测到,对用户来说几乎没有区别。
分布式延迟队列的实现
时间轮是单机内存中的数据结构。在分布式系统中,延迟队列需要考虑更多因素:持久化、故障恢复、水平扩展。
Redis Sorted Set方案
使用Redis的Sorted Set(ZSet)实现延迟队列是一种常见的方案。将任务的执行时间戳作为score,任务数据作为member,利用ZSet的有序性来排序任务。
# 添加延迟任务
redis.zadd("delay_queue", {task_data: execute_timestamp})
# 消费到期任务
now = time.time()
tasks = redis.zrangebyscore("delay_queue", 0, now)
for task in tasks:
# 处理任务
process(task)
# 删除已处理的任务
redis.zrem("delay_queue", task)
这个方案的优点是实现简单,利用Redis的持久化能力可以保证任务不丢失。但缺点也很明显:
- 需要持续轮询来检查到期任务,浪费CPU和网络资源
- 多个消费者竞争时需要处理并发问题
- 无法精确控制任务的执行时间
消息队列延迟消息
许多消息队列支持延迟消息功能。RabbitMQ通过rabbitmq_delayed_message_exchange插件支持延迟消息,最大延迟约24天。消息会被存储在内存中直到投递时间到达。
这个方案的优点是将延迟逻辑交给消息队列处理,应用代码更简洁。但延迟消息存储在内存中,集群重启可能导致消息丢失。
Airbnb Dynein的设计
Airbnb构建了名为Dynein的分布式延迟任务系统,采用了一种独特的设计。核心思路是使用DynamoDB作为存储后端,利用其分区键和排序键的特性来高效管理延迟任务。
每个任务有一个随机生成的分区键和一个由"执行时间戳+UUID"组成的排序键。由于分区键是随机的,负载会均匀分布在所有分区上。调度器只需要查询每个分区内排序键小于当前时间的任务即可。
Airbnb报告称,相比之前使用的基于Quartz+MySQL的方案,DynamoDB方案的成本降低了三分之二,同时获得了更好的可扩展性。
不同方案的权衡与选择
没有完美的延迟队列实现,只有适合特定场景的选择。
时间轮的适用场景
时间轮最适合以下场景:
- 大量定时任务(万级以上)
- 大部分任务会在到期前被取消
- 对时间精度要求不严格(可以接受毫秒级误差)
- 任务存储在内存中可接受
典型应用:网络连接超时管理、操作系统定时器、游戏服务器定时任务。
最小堆的适用场景
最小堆适合以下场景:
- 定时任务数量适中(千级以下)
- 需要精确的执行时间
- 任务生命周期较长
典型应用:Java的ScheduledThreadPoolExecutor、Python的asyncio调度器。
分布式方案的适用场景
分布式延迟队列适合以下场景:
- 需要持久化,不能丢失任务
- 任务执行时间跨度大(分钟到天级别)
- 需要水平扩展
典型应用:订单超时取消、定时通知、延迟重试。
设计决策的启示
时间轮算法的发展历程揭示了一个重要的设计原则:理解问题的本质特征是找到最优解的前提。
定时器操作的本质特征是"大量创建、大量取消"。对于这种场景,删除操作的性能比插入操作更重要。时间轮通过牺牲空间和时间精度,将删除操作的复杂度从O(log N)降到O(1),这正是针对问题本质的优化。
Kafka和Linux内核的实现则展示了另一个原则:理解使用场景。Kafka需要处理数万个并发请求的超时,Linux内核需要保证定时器操作的延迟可预测。两者都选择了"用精度换性能/确定性"的权衡,因为他们深知超时检测对精度的要求远低于对性能和确定性的要求。
参考文献
-
Varghese, G., & Lauck, T. (1987). Hashed and Hierarchical Timing Wheels: Data Structures for the Efficient Implementation of a Timer Facility. SOSP ‘87: Proceedings of the eleventh ACM Symposium on Operating systems principles.
-
Wang, J. (2015). Apache Kafka, Purgatory, and Hierarchical Timing Wheels. Confluent Blog.
-
Corbet, J. (2015). Reinventing the timer wheel. LWN.net.
-
Snellman, J. (2016). Ratas - A hierarchical timer wheel.
-
Patel, K. (2019). Dynein: Building a Distributed Delayed Job Queueing System. Airbnb Engineering Blog.