2006年10月,Netflix做了一件在当时看起来疯狂的事:公开发布了1亿条匿名用户评分数据,悬赏100万美元征集能把推荐准确率提升10%的算法。这个看似简单的数字背后,是一场持续三年的算法马拉松,吸引了来自186个国家的超过4万支队伍参赛。最终获胜的方案融合了超过100个子模型,技术报告长达92页。
但这个故事最有趣的部分不在于谁赢了,而在于赢家方案实际上并没有被Netflix采用。原因很简单:工程复杂度太高,维护成本太贵。真正的工业级推荐系统,从来不是一场纯粹的精度竞赛。
从1992年Xerox PARC的Tapestry系统诞生至今,推荐系统已经走过了三十多年的演进之路。这条道路上的每一次技术迭代,背后都是精度、效率、可扩展性之间的艰难权衡。
协同过滤:从"喜欢这个的人也喜欢那个"到数学框架
推荐系统最朴素的思想可以概括为一句简单的话:如果两个人过去喜欢的东西很像,那他们未来喜欢的东西也可能很像。
1992年,Xerox PARC的研究人员David Goldberg等人提出了Tapestry系统,这是历史上第一个协同过滤(Collaborative Filtering)系统。Tapestry的核心机制依赖一个关键假设:用户之间存在可以识别的相似性。系统允许用户对邮件进行标注(如"有趣"、“重要”),然后其他用户可以基于这些标注来过滤邮件。
两年后,明尼苏达大学的GroupLens项目将这个思想推向了实用化。GroupLens为Usenet新闻组开发了自动过滤系统,它不仅要判断用户之间的相似性,还要处理一个更根本的问题:如何在海量用户中高效地找到"相似的人"。
GroupLens引入了用户-用户协同过滤(User-User CF)的框架。具体做法是:对于目标用户u,找到与其历史行为最相似的k个用户,然后用这k个用户的偏好来预测u对未知物品的兴趣。相似度的计算通常采用皮尔逊相关系数或余弦相似度。
但这个框架存在一个致命缺陷:扩展性。当用户数量增长到百万、千万级别时,为每个用户计算与其他所有用户的相似度,时间复杂度是$O(n^2)$,这在实际系统中完全不可接受。
2003年,Amazon的研究人员Greg Linden、Brent Smith和Jeremy York在IEEE Internet Computing上发表了一篇论文,提出了一个巧妙的变体:物品-物品协同过滤(Item-Item CF)。与其找相似的用户,不如找相似的物品。用户A买了商品X,那我们就推荐与X最相似的几个商品。
这个看似简单的转换带来了巨大的工程优势。用户数量可能快速增长,但物品类别相对稳定。物品之间的相似度可以离线预计算并存储,在线推荐时只需要简单的查表操作。Amazon的推荐系统因此能够支撑其庞大的用户基数。
然而,无论是User-User还是Item-Item CF,都面临一个共同的困境:数据稀疏性。在典型的电商场景中,用户只浏览或购买过极小比例的商品,用户-物品交互矩阵99%以上的位置都是空的。如何在如此稀疏的数据上准确预测用户偏好?
矩阵分解:Netflix Prize背后的技术革命
2006年启动的Netflix Prize,将推荐系统研究推向了一个新的高度。竞赛的核心任务是预测用户对电影的评分(1-5星),评估指标是RMSE(均方根误差)。
Netflix原有的算法Cinematch的RMSE是0.9525。竞赛要求参赛者将这个数字降低至少10%,即达到0.8572以下。这看起来是一个温和的改进目标,但三年间,没有一支队伍能够单独达标。最终的获胜方案是多个团队合并后形成的集成模型。
竞赛期间,矩阵分解(Matrix Factorization)技术展现了强大的生命力。Yehuda Koren、Robert Bell和Chris Volinsky在2009年发表于Computer杂志的论文中系统阐述了这一技术。
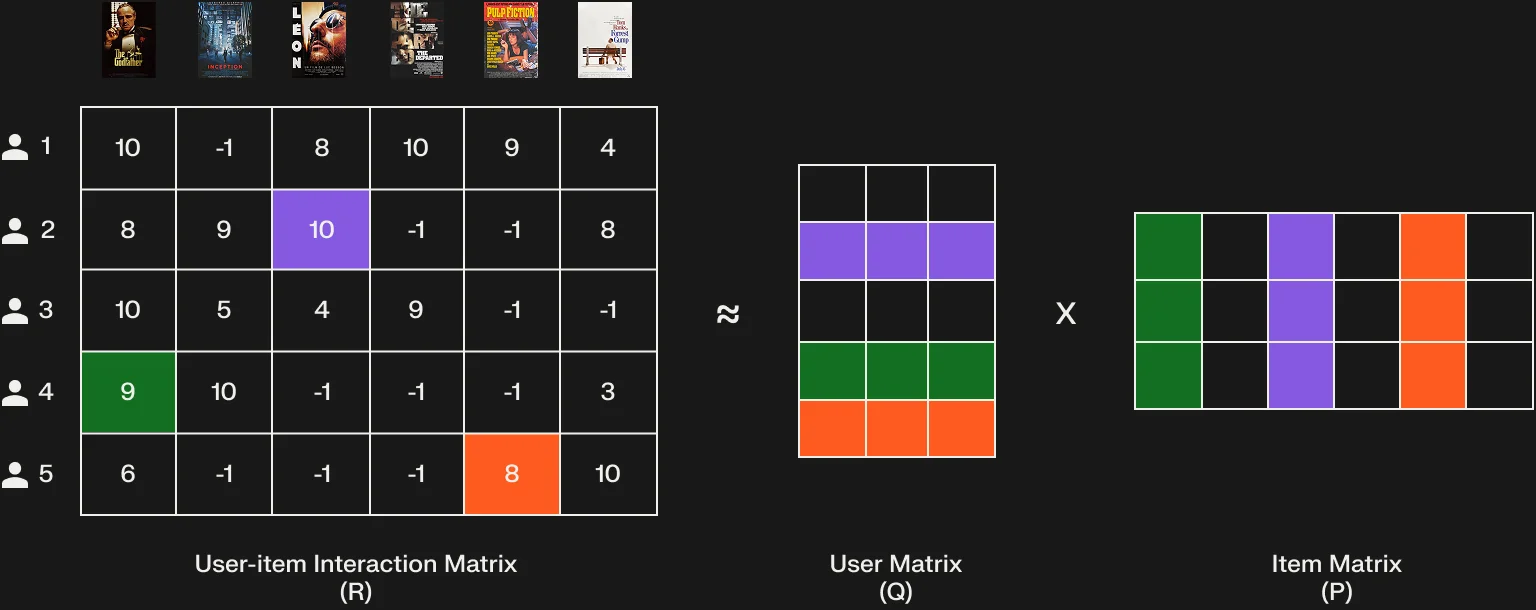
核心思想是将巨大的用户-物品交互矩阵$R$分解为两个低维矩阵的乘积:
$$R \approx P \times Q^T$$其中$P$是用户隐因子矩阵,每行$p_u$代表用户u的k维隐向量;$Q$是物品隐因子矩阵,每行$q_i$代表物品i的k维隐向量。预测用户u对物品i的评分就是两个向量的点积:
$$\hat{r}_{ui} = p_u \cdot q_i$$这里的"隐因子"(Latent Factors)是算法自动学习出来的维度,可能对应电影类型、风格、年代等,也可能是人类难以解释的组合。关键在于,即使两个用户从未对同一部电影评分,只要他们的隐向量相似,就认为他们的偏好相似。这巧妙地绕过了稀疏性问题。
矩阵分解的训练有两种主流方法:随机梯度下降(SGD)和交替最小二乘(ALS)。SGD通过遍历已知评分,不断调整$p_u$和$q_i$来减少预测误差。ALS则更巧妙:固定$Q$时,对$P$的优化变成了独立的最小二乘问题,可以高度并行化。
Netflix Prize的赢家还引入了一系列重要改进:
- 偏置项(Bias Terms):区分用户评分偏严或偏宽、电影整体受欢迎程度
- 时间动态(Temporal Dynamics):用户偏好会随时间变化
- 隐式反馈(Implicit Feedback):利用用户的浏览行为,不仅仅是显式评分
{kind=link}
竞赛结束后,Yehuda Koren加入了Netflix,但Netflix并没有直接部署获胜方案。原因是集成模型虽然精度高,但维护成本太大。实际生产环境中,一个易于迭代更新的单模型往往比复杂的集成模型更有价值。
深度学习时代:从YouTube到淘宝的技术跃迁
2016年是推荐系统深度学习元年。这一年,Google发表了《Deep Neural Networks for YouTube Recommendations》,展示了如何将深度神经网络应用于大规模视频推荐。
YouTube的推荐架构揭示了一个关键洞察:现代推荐系统必须是多阶段的。
召回与排序:漏斗架构的工程智慧
YouTube每天有超过十亿的用户,视频库包含数亿个视频。让深度模型对每个用户-视频对进行打分是不现实的。解决方案是将推荐分为两个阶段:
召回阶段(Retrieval/Candidate Generation):从海量候选中快速筛选出几百个可能相关的视频。这一阶段追求高召回率和低延迟。
排序阶段(Ranking):对召回的几百个视频进行精确打分排序,输出最终推荐列表。这一阶段追求高精度,可以使用更复杂的模型。
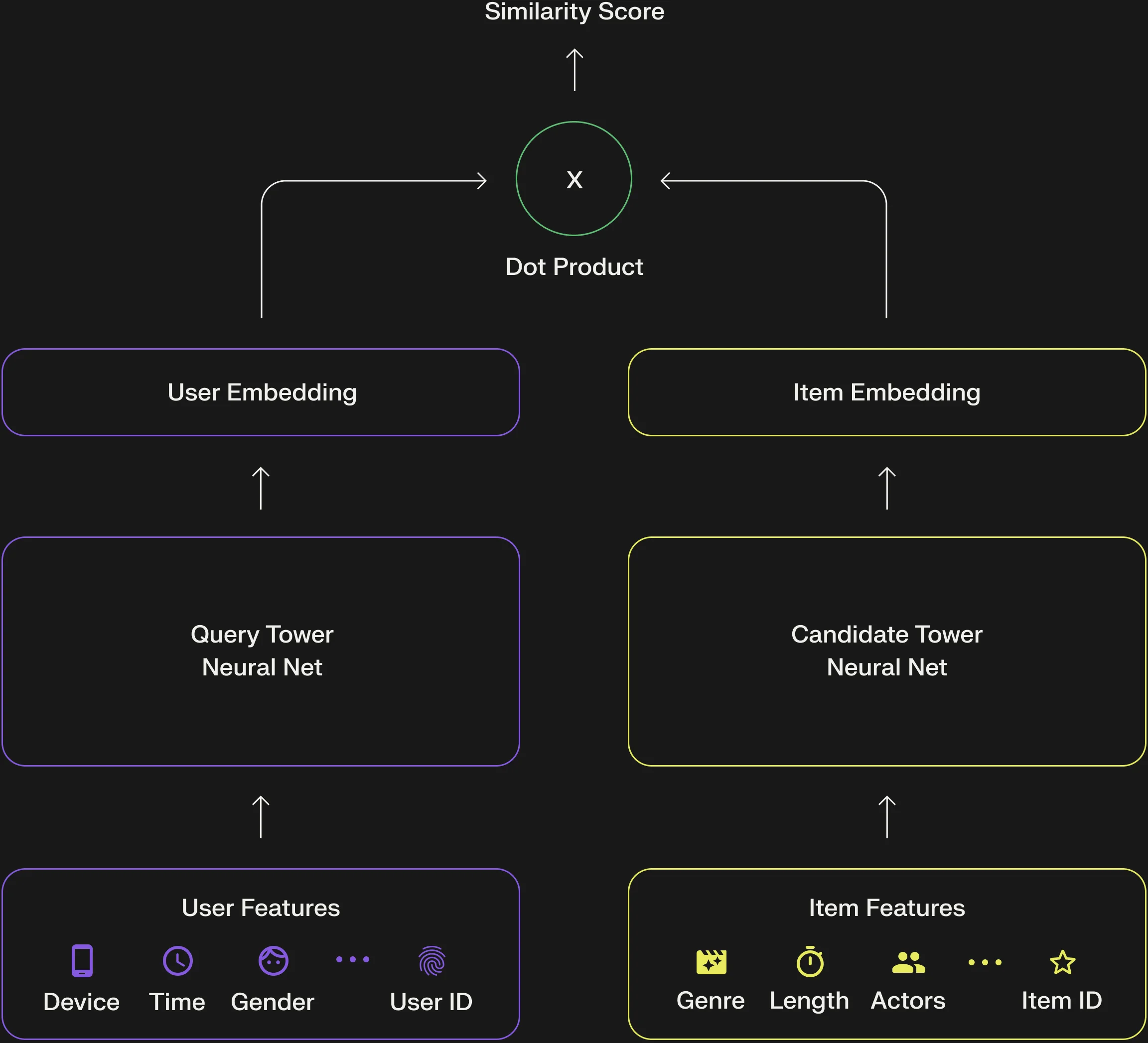
YouTube的召回模型采用了双塔架构(Two-Tower Architecture):用户塔和物品塔分别将用户特征和视频特征编码为embedding向量,最终通过向量相似度(通常是点积)来衡量相关性。
双塔架构的核心优势在于:物品塔可以离线预计算。所有视频的embedding向量都可以预先算好存入向量数据库。当用户发起请求时,只需要实时计算用户的embedding,然后在向量空间中做近似最近邻搜索(ANN)即可。这使得从数亿视频中检索候选的延迟可以控制在毫秒级。
{kind=link}
排序阶段则使用了更复杂的深度神经网络,输入包括用户历史行为序列、候选视频特征、上下文信息等。模型输出是用户观看该视频的概率。
同年,Google还提出了Wide & Deep模型,将记忆能力(Memorization)和泛化能力(Generalization)结合在一个框架中。Wide部分是线性模型,擅长捕获历史行为中的显式特征组合;Deep部分是多层感知机,擅长学习隐式的特征交叉。
序列建模:用户兴趣是会演变的
用户对某个品类感兴趣,不代表永远只对它感兴趣。2018年,阿里巴巴提出了DIN(Deep Interest Network),引入注意力机制来动态调整用户历史行为对当前预测的影响权重。
比如用户之前买过键盘和口红,现在要预测他对某款鼠标的兴趣。键盘相关的历史行为显然应该比口红更相关。DIN通过注意力机制让模型自动学习这种相关性权重。
2019年,阿里进一步提出了DIEN(Deep Interest Evolution Network),将用户兴趣建模为一个序列演化过程。用户今天的兴趣受到昨天兴趣的影响,是一个动态变化的系统。DIEN使用GRU(Gated Recurrent Unit)来捕获这种时序依赖。
同年,阿里还提出了BST(Behavior Sequence Transformer),直接使用Transformer架构来处理用户行为序列。Transformer的自注意力机制能够捕获行为之间的长程依赖关系,在淘宝的点击率预测任务中取得了显著提升。
图神经网络:用户-物品交互是一个图
用户和物品天然构成了一个二部图:用户节点和物品节点通过交互行为相连。图神经网络(GNN)可以在这个图上传播信息,聚合邻居节点的特征。
Pinterest的PinSage是GNN在推荐系统中的里程碑工作。Pinterest是一个图片分享平台,用户创建"Pin"(图钉),收集到"Board"(画板)中。PinSage在用户-Pin-Board构成的图上运行图卷积网络,为每个Pin学习高质量的embedding向量。
PinSage的关键创新在于基于随机游走的采样策略:不是聚合所有邻居,而是通过随机游走采样重要的邻居。这既降低了计算复杂度,又能捕获图中的关键结构信息。
2020年,LightGCN简化了图卷积操作用于推荐,去除了特征变换和非线性激活,只保留了邻居聚合,却取得了更好的效果。这暗示了推荐系统中过拟合的风险——有时候"更简单"反而是"更好"。
冷启动:新用户、新物品的困境
推荐系统最头疼的问题之一是冷启动(Cold Start):新用户没有历史行为,新物品没有被任何人交互过,如何推荐?
这是一个根本性的数据缺失问题。传统协同过滤完全依赖历史交互数据,对于冷启动场景束手无策。
混合策略:多条腿走路
工业界的解决方案通常是混合推荐(Hybrid Recommendation):将协同过滤与基于内容的推荐(Content-Based Filtering)相结合。
对于新物品,虽然缺乏用户交互数据,但可以提取内容特征:商品的类别、描述文本、图片特征等。基于内容的推荐通过计算物品内容特征的相似度来做推荐。
对于新用户,可以利用注册信息(年龄、性别、地理位置)、设备信息、首次访问行为等。很多平台在新用户注册时会询问兴趣偏好,这本质上是人工获取冷启动特征。
元学习与迁移学习
更前沿的解决方案是让模型学会"快速适应"。元学习(Meta-Learning)的思想是:训练一个能够快速学习新任务能力的模型。在推荐场景下,就是让模型学会如何从极少量的交互中快速捕捉用户偏好。
迁移学习则尝试从其他领域借力。比如一个用户在视频平台的观看历史,理论上可以帮助推测他在电商平台的购物偏好,前提是两个平台之间有某种用户画像共享机制。
冷启动问题的存在,也是为什么推荐系统评估不能只看整体指标,还要分群体(新用户vs老用户、热门物品vs长尾物品)进行分析。
偏差问题:推荐系统在放大什么
推荐系统不是中立的观察者,它会放大、扭曲它所学习的数据分布。
流行度偏差
协同过滤天然偏好热门物品:热门物品有更多用户交互,更容易被识别为"相似"。结果是推荐列表被热门内容占据,马太效应愈演愈烈。
这不是一个纯粹的算法问题。热门内容确实更可能被用户喜欢,但过度推荐热门内容会损害推荐多样性,让用户陷入"信息茧房"。更隐蔽的影响是:新内容更难获得曝光,创新者的内容难以被发现。
缓解流行度偏差的方法包括:在训练时对热门物品降权、在采样负样本时避免过度采样热门物品、在排序时引入多样性目标等。
位置偏差
用户更倾向于点击排在前面的结果。这个现象在搜索和推荐中都很常见。问题是,模型学习到的是"用户喜欢排在前面的内容"还是"用户喜欢这个内容"?
如果不加校正,模型会把位置当成一个预测因子,形成反馈循环:排在前面的内容获得更多点击,模型认为这些内容更受欢迎,继续把它们排在前面。
解决方案包括:在训练时将位置作为输入特征并预测时设置为固定值(Inference时设为0或首位)、使用逆倾向分数(IPS)对样本加权等。
选择偏差
我们只能观察到用户选择交互的物品,无法知道用户没有交互的物品是因为不喜欢,还是根本没看到。这种选择性偏差让训练数据无法代表真实偏好分布。
因果推断(Causal Inference)的思想被引入推荐系统来处理这类偏差。核心思想是区分"用户是否喜欢这个物品"和"用户是否会看到并点击这个物品"两个不同的因果机制。
评估指标:离线高分不等于在线成功
推荐系统评估是一个复杂的话题。离线评估使用历史数据计算指标,在线评估通过A/B测试测量真实业务影响。
离线指标
精确率与召回率(Precision & Recall):最直观的分类指标。但在推荐场景中,用户能看到的只有前几个结果,整体的精确率意义不大。通常计算$Precision@K$和$Recall@K$,只看前K个推荐结果。
NDCG(Normalized Discounted Cumulative Gain):考虑排序位置的重要性。排在前面的正确预测得分更高,排在后面的得分打折扣。公式为:
$$NDCG@K = \frac{DCG@K}{IDCG@K}$$其中$DCG@K = \sum_{i=1}^{K}\frac{2^{rel_i}-1}{\log_2(i+1)}$,$rel_i$是第$i$个位置的物品相关性分数,$IDCG$是理想排序下的DCG值。
MAP(Mean Average Precision):计算每个查询的平均精确率,再对所有查询取平均。适用于二值相关性判断的场景。
MRR(Mean Reciprocal Rank):只关心第一个相关结果出现的位置。$MRR = \frac{1}{|Q|}\sum_{i=1}^{|Q|}\frac{1}{rank_i}$,其中$rank_i$是第$i$个查询的第一个相关结果的排名。
离线与在线的鸿沟
一个令人沮丧的事实是:离线指标的提升往往不能转化为在线指标的提升。原因在于:
离线评估假设用户会浏览所有推荐结果,但实际上用户只看前几个。离线评估使用历史数据,但用户的偏好可能已经变化。离线评估优化的是点击率或评分准确度,但业务目标可能是用户留存、时长、收入等更复杂的指标。
这也是为什么成熟的推荐团队会同时维护离线评估和在线A/B测试两套体系。离线评估用于快速筛选算法候选,在线测试用于最终验证。
工程架构:从单模型到多阶段流水线
一个生产级推荐系统的架构,远比学术论文中描述的单模型复杂得多。
多阶段漏斗架构
现代推荐系统通常采用多阶段漏斗架构:
召回阶段(Recall):从百万/亿级候选中快速筛选千级候选。通常部署多个召回通道:协同过滤召回、内容相似召回、热门召回、实时行为召回等。各通道并行运行,结果合并后去重。
粗排阶段(Coarse Ranking):对召回结果做初步排序,使用轻量级模型。输入特征相对简单,目的是进一步缩小候选集。
精排阶段(Fine Ranking):对粗排结果做精细打分,使用复杂深度模型。输入特征丰富,可能包括用户画像、物品特征、上下文、交叉特征等。
重排阶段(Re-ranking):对精排结果做最终调整,引入业务规则。可能的目标包括:去重、打散同类内容、插入广告、下架违规内容等。

图片来源: towardsdatascience.com
{kind=link}
实时性与增量更新
用户的兴趣会随时间变化。早上想看新闻,晚上想看娱乐视频。一个只依赖离线训练的推荐系统无法捕捉这种实时变化。
在线学习(Online Learning)允许模型随着新数据的到来实时更新参数。但这带来了新的挑战:如何防止模型被恶意行为污染?如何处理概念漂移(Concept Drift)?
增量更新是一种折中方案:模型主体离线训练,但部分参数(如用户embedding)可以实时更新。这平衡了计算成本和时效性。
LinkedIn的技术博客详细描述了他们的增量学习平台架构:利用Kafka流式处理用户行为数据,每隔几分钟更新一次模型参数,同时保留回滚机制以应对异常情况。
可解释性:从黑盒到透明
深度学习模型的引入让推荐系统变得更加"聪明",但也更加"神秘"。用户想知道"为什么推荐这个",平台需要向监管机构解释算法决策过程。
可解释推荐(Explainable Recommendation)试图为每个推荐结果提供人类可理解的解释。常见的解释形式包括:
- 基于模板的自然语言解释:“因为你看过X,所以推荐Y”
- 关键因素可视化:高亮显示影响推荐决策的关键特征
- 反事实解释:“如果你没有购买过X,就不会看到这个推荐”
知识图谱为可解释推荐提供了新的视角。如果知道物品A和物品B在知识图谱中通过"同一导演"相连,就可以生成"因为都由导演X执导"这样的解释。
未来走向:推荐系统的下一个十年
回顾推荐系统三十年的演进,我们看到的是一条从简单规则到复杂模型、从离线处理到实时响应、从单一目标到多维权衡的发展轨迹。
当前的研究热点包括:
对话式推荐系统:用户可以通过自然语言与推荐系统交互,表达偏好、提出约束、要求解释。这要求推荐系统具备语言理解和多轮对话管理能力。
强化学习:将推荐视为一个序列决策问题,优化长期收益而非即时点击。探索-利用权衡变得至关重要。
联邦学习与隐私保护:数据不出本地,模型在边缘训练。如何在保护隐私的前提下维持推荐效果,是一个开放问题。
多模态推荐:融合文本、图像、视频、音频等多种模态的信息。Transformer架构在多模态融合中展现了强大潜力。
推荐系统的未来,不会是更复杂的模型,而是更智能的权衡——在精度与效率、个性化与多样性、商业目标与用户体验之间,找到那个微妙的平衡点。
参考文献
-
Goldberg, D., Nichols, D., Oki, B. M., & Terry, D. (1992). Using collaborative filtering to weave an information tapestry. Communications of the ACM, 35(12), 61-70.
-
Resnick, P., Iacovou, N., Suchak, M., Bergstrom, P., & Riedl, J. (1994). GroupLens: An open architecture for collaborative filtering of netnews. CSCW ‘94.
-
Linden, G., Smith, B., & York, J. (2003). Amazon.com recommendations: Item-to-item collaborative filtering. IEEE Internet Computing, 7(1), 76-80.
-
Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. Computer, 42(8), 30-37.
-
Covington, P., Adams, J., & Sargin, E. (2016). Deep neural networks for YouTube recommendations. RecSys ‘16.
-
Cheng, H. T., et al. (2016). Wide & deep learning for recommender systems. DLRS ‘16.
-
Zhou, G., et al. (2018). Deep interest network for click-through rate prediction. KDD ‘18.
-
Ying, R., et al. (2018). Graph convolutional neural networks for web-scale recommender systems. KDD ‘18.
-
He, X., Liao, L., Zhang, H., Nie, L., Hu, X., & Chua, T. S. (2017). Neural collaborative filtering. WWW ‘17.
-
Sun, F., et al. (2019. BERT4Rec: Sequential recommendation with bidirectional encoder representations from transformer. CIKM ‘19.
-
Dong, Z., et al. (2022). A brief history of recommender systems. DLP-KDD ‘22.
-
Chen, J., et al. (2023). A comprehensive survey on retrieval methods in recommender systems. arXiv preprint arXiv:2407.21022.