
一个包含20,000行数据的简单列表,能让浏览器内存占用飙升超过700MB,DOM检查器甚至无法正常工作。这不是危言耸听,而是前端开发者在处理大数据量列表时真实遇到的困境。
当你在React中渲染一个包含10万条数据的列表,页面可能直接卡死。原因很简单:浏览器需要为每一个DOM节点分配内存、计算样式、执行布局、绘制像素。当节点数量突破某个临界点,渲染管道的每一个环节都会成为性能瓶颈。
虚拟滚动(Virtual Scrolling)正是为解决这个问题而生。它的核心思想看似简单:只渲染用户能看到的元素。但真正理解其技术本质,需要深入浏览器渲染机制、DOM操作成本、以及精确的数学计算。
DOM瓶颈的真实代价
要理解为什么虚拟滚动有效,首先需要理解DOM操作为什么昂贵。
Chrome的Lighthouse工具对DOM大小有明确的警告阈值:当页面DOM节点超过800个时发出警告,超过1400个时直接报错。这些数字背后,是浏览器渲染管道的实际工作负载。
当浏览器渲染一个页面时,需要经历五个关键阶段:JavaScript执行、样式计算、布局(Layout)、绘制(Paint)、合成(Composite)。每一个阶段都与DOM规模直接相关。
样式计算阶段,浏览器需要将CSS选择器与DOM节点进行匹配。一个包含10万个<li>元素的列表,即使每个元素只应用一条CSS规则,浏览器也需要进行10万次选择器匹配。复杂的选择器(如.container > .list .item:nth-child(odd))会显著增加匹配成本。
布局阶段,浏览器计算每个元素的几何属性:位置、尺寸、边距、边框。Web的布局模型决定了元素的几何属性具有传染性——一个元素宽度的改变可能触发整个子树的重新计算。10万个元素的布局计算,即使在现代CPU上,也需要数十毫秒。
绘制阶段,浏览器将元素转换为像素。每个元素都需要绘制其背景、边框、文本、阴影等视觉属性。绘制成本与元素覆盖的像素面积成正比,一个全屏的半透明叠加层,其绘制成本远高于一个20×20像素的图标。
内存消耗是最容易被忽视的成本。每个DOM节点都是JavaScript对象,存储着标签名、属性、样式、事件监听器等信息。当使用document.querySelectorAll('li')获取所有列表项时,返回的NodeList会持有对所有匹配节点的引用,即使这些节点之后被从文档中移除,只要NodeList还存在,它们就无法被垃圾回收。
一个真实案例:某团队使用document.querySelectorAll('*')来获取页面上所有元素,结果返回了超过3万个节点。这个单一操作创建了3万个JavaScript对象的引用,在低配置移动设备上直接导致页面崩溃。
虚拟滚动的核心架构
虚拟滚动的核心目标是:无论数据集有多大,DOM中始终只保留用户能看到的元素。
实现这一目标需要三个关键机制的协同工作:视口计算、占位容器、缓冲区策略。
视口计算:从滚动位置到元素索引
视口计算是虚拟滚动的数学核心。给定一个固定高度的滚动容器和固定高度的列表项,我们可以精确计算出任意滚动位置应该显示哪些元素。
假设容器高度为containerHeight,每项高度为itemHeight,当前滚动位置为scrollTop,那么:
- 可见项数量:$visibleCount = \lceil\frac{containerHeight}{itemHeight}\rceil$
- 起始索引:$startIndex = \lfloor\frac{scrollTop}{itemHeight}\rfloor$
- 结束索引:$endIndex = startIndex + visibleCount - 1$
这组公式看似简单,但其精确性决定了滚动的流畅度。当用户快速滚动时,每一帧的scrollTop值都在变化,我们需要在下一帧渲染之前完成索引计算和DOM更新。
占位容器:维持滚动条的物理真实性
如果只渲染可见元素,滚动条的行为会完全错误——一个包含10万条数据的列表,如果只渲染50个元素,滚动条会显示内容只有50行的高度。
解决方案是使用占位容器(Padding Elements)来模拟完整的内容高度:
const totalHeight = itemCount * itemHeight;
const topPaddingHeight = startIndex * itemHeight;
const bottomPaddingHeight = totalHeight - topPaddingHeight - visibleItemsHeight;
通过在可见元素上方和下方放置高度精确的空<div>,滚动条会认为整个数据集都已渲染。用户拖动滚动条时,体验与完整渲染完全一致。
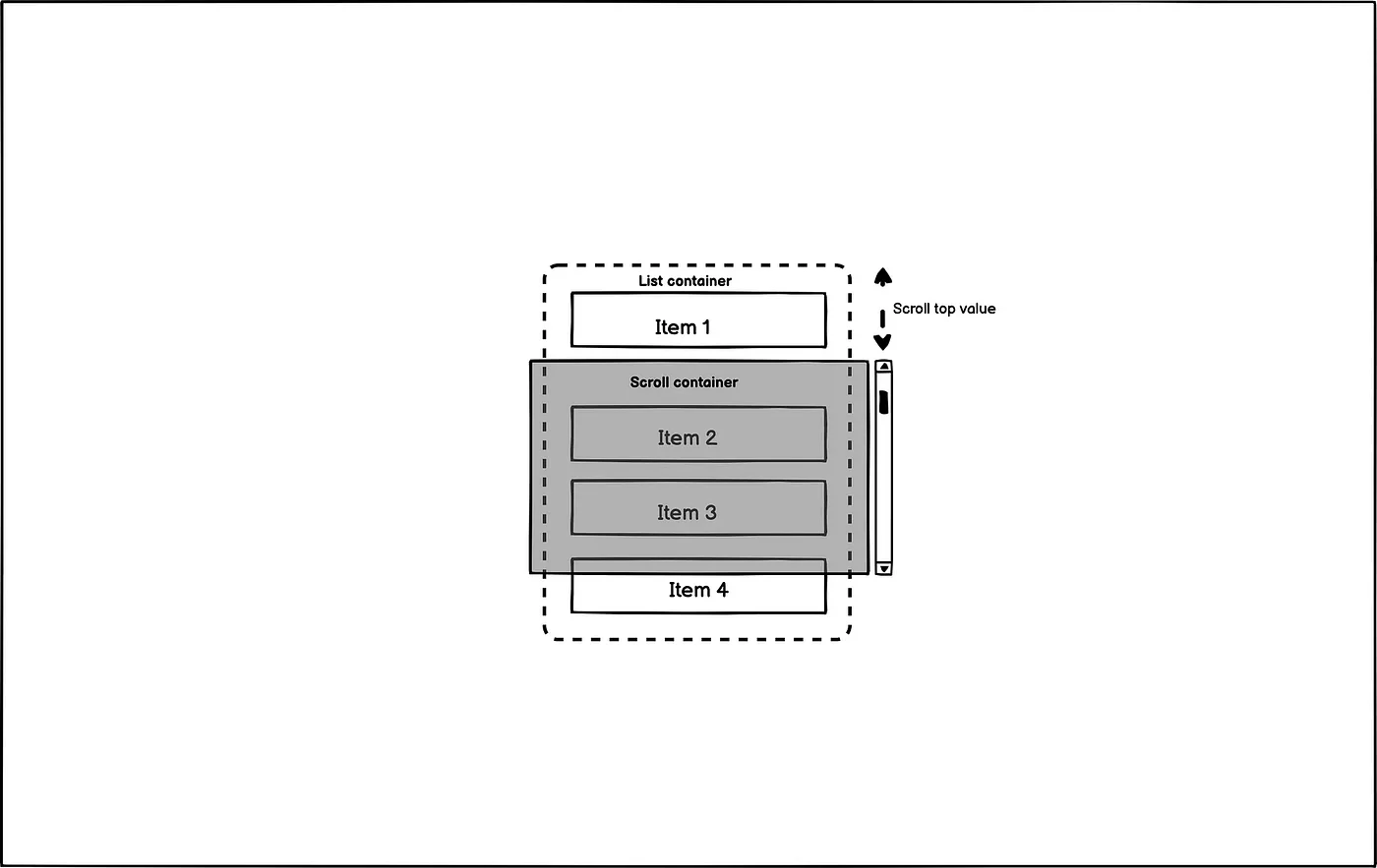
图片来源: Medium - Virtual Scrolling Architecture
上图清晰地展示了虚拟滚动的结构:总高度由上下两个padding元素和中间的可见元素共同构成。滚动时,三个部分的高度动态调整,始终保持总高度不变。
缓冲区:消除快速滚动时的白屏闪烁
精确渲染可见元素会导致一个用户体验问题:快速滚动时,新元素进入视口之前来不及渲染,用户会看到短暂的空白区域。
缓冲区(Overscan)策略通过预渲染视口之外的元素来解决这个问题:
const bufferSize = Math.ceil(visibleCount / 2);
const bufferedStartIndex = Math.max(0, startIndex - bufferSize);
const bufferedEndIndex = Math.min(itemCount - 1, endIndex + bufferSize);
典型配置是上下各缓冲半个视口高度的元素。这意味着当用户向下滚动时,新元素在进入视口之前就已经存在于DOM中。当滚动速度极快时,缓冲区能吸收大部分延迟。
缓冲区大小是一个权衡决策:更大的缓冲区减少白屏风险,但增加DOM节点数量和渲染成本。对于简单列表项,缓冲10-20个元素通常足够;对于包含图片或复杂组件的列表项,可能需要更大的缓冲区。
动态高度:从理想模型到工程现实
固定高度的虚拟滚动在数学上是优雅的——一切都是简单的算术运算。但真实世界的列表项高度往往不固定:文本内容长度不一、图片尺寸各异、可折叠的子项……
动态高度虚拟滚动的复杂性来自于一个根本矛盾:在元素渲染之前,我们无法知道它的实际高度。
预估-测量-修正策略
最常用的方案是"预估-测量-修正":
- 预估:为每个元素提供一个估计高度,用于计算初始布局
- 测量:元素渲染后,获取其实际高度
- 修正:根据实测高度更新布局缓存,必要时调整滚动位置
// 高度缓存
const heightCache = new Map();
function getItemHeight(index) {
if (heightCache.has(index)) {
return heightCache.get(index);
}
return estimatedItemHeight; // 默认预估值
}
function measureItem(index, element) {
const actualHeight = element.getBoundingClientRect().height;
heightCache.set(index, actualHeight);
}
这个方案的问题在于:当实测高度与预估高度差异较大时,滚动位置会发生跳变。用户正在查看第1000个元素,突然因为前面某个元素的实测高度更新,整个列表"跳"了一下——这是极其糟糕的用户体验。
二分查找与位置映射
对于动态高度列表,我们不能简单地用scrollTop / itemHeight计算索引。需要维护一个位置映射表,记录每个元素的起始位置:
const positions = []; // 每个元素的起始位置
function findStartIndex(scrollTop) {
// 二分查找:找到最后一个起始位置 <= scrollTop 的元素
let left = 0, right = positions.length - 1;
while (left < right) {
const mid = Math.ceil((left + right + 1) / 2);
if (positions[mid] <= scrollTop) {
left = mid;
} else {
right = mid - 1;
}
}
return left;
}
这个算法的时间复杂度是$O(\log n)$,对于10万条数据,最多只需要17次比较。
滚动条跳动问题
动态高度虚拟滚动最棘手的问题是滚动条跳动(Scrollbar Jumping)。当元素的实测高度与预估值不同,总高度计算会发生变化,导致滚动条位置突变。
缓解方案包括:
- 保守预估:预估高度略大于实际高度,避免向下跳动
- 增量修正:只在差异超过阈值时才更新布局
- 滚动锚定:记住当前视口第一个元素的偏移量,修正后恢复其位置
某些生产级实现(如Angular CDK的Virtual Scroll)会在后台持续测量元素高度,并在检测到显著偏差时平滑过渡,而不是立即跳变。
浏览器渲染管道的视角
理解虚拟滚动的性能优势,需要从浏览器渲染管道的视角来看待问题。
浏览器将代码转换为像素经历六个阶段:解析(Parsing)→ 样式计算(Style)→ 布局(Layout)→ 绘制(Paint)→ 光栅化(Rasterization)→ 合成(Composite)。每个阶段的成本都与DOM规模相关。
样式计算的成本
CSS选择器从右向左匹配。对于选择器.list .item,浏览器会先找到所有.item元素,再检查它们的祖先是否匹配.list。如果页面上有10万个.item元素,这个选择器就需要进行10万次匹配检查。
虚拟滚动将活跃DOM节点控制在50-100个范围内,样式计算的成本被压缩到原来的千分之一。
布局的传染性
布局计算是渲染管道中最昂贵的阶段之一。一个元素的几何变化可能触发整个子树的重新布局。
CSS的Flexbox和Grid布局尤其敏感。在Flex容器中,子元素的尺寸相互影响;在Grid布局中,轨道尺寸可能需要多次迭代才能收敛。虚拟滚动通过限制DOM规模,将布局计算限定在一个小范围内。
绘制的像素成本
绘制成本与元素覆盖的像素面积成正比。一个全屏的列表,即使只显示50个元素,绘制成本仍然可观。虚拟滚动虽然减少了元素数量,但无法减少每个元素占用的像素面积。
真正的优化来自于避免重绘。虚拟滚动只在滚动事件触发时更新DOM,而不是像普通列表那样,任何数据变化都可能导致整个列表重绘。
内存布局的影响
DOM节点是JavaScript对象,存储在堆内存中。大量DOM节点会占用堆内存,增加垃圾回收的压力。虚拟滚动减少了活跃DOM节点的数量,从而降低了内存占用和GC频率。
更重要的是,虚拟滚动消除了一个常见的内存泄漏模式:当使用document.querySelectorAll()获取元素列表时,即使这些元素从DOM中移除,只要列表引用还在,它们就无法被回收。虚拟滚动确保了只有少量元素存在于DOM中,降低了这类问题的风险。
滚动事件处理的性能陷阱
虚拟滚动的实现细节中,滚动事件处理是最容易被忽视的性能陷阱。
事件频率问题
浏览器在滚动时会高频触发scroll事件——普通鼠标滚轮每秒可能触发60次以上,触控板滑动更是高达100+次。如果在每次事件触发时都执行DOM更新,主线程会被完全阻塞。
// 危险:每次滚动都触发状态更新
element.addEventListener('scroll', (e) => {
setScrollTop(e.target.scrollTop); // React重渲染
});
这个实现会导致滚动卡顿,因为每次状态更新都触发React的协调过程。
requestAnimationFrame的正确使用
正确的做法是将DOM更新与浏览器的渲染周期对齐:
let scheduled = false;
let lastScrollTop = 0;
element.addEventListener('scroll', (e) => {
lastScrollTop = e.target.scrollTop;
if (!scheduled) {
scheduled = true;
requestAnimationFrame(() => {
updateVisibleItems(lastScrollTop);
scheduled = false;
});
}
});
这个实现确保了每帧最多只执行一次更新,无论滚动事件触发多少次。requestAnimationFrame将更新调度到浏览器的下一帧渲染之前,避免了与渲染管道冲突。
Intersection Observer的替代方案
对于不需要精确控制渲染时机的场景,IntersectionObserver API提供了一个更现代的方案:
const observer = new IntersectionObserver((entries) => {
entries.forEach(entry => {
if (entry.isIntersecting) {
// 元素进入视口,开始渲染
renderItem(entry.target.dataset.index);
}
});
}, {
rootMargin: '200px' // 提前200px开始渲染
});
IntersectionObserver在浏览器内部运行,不占用主线程时间。它的性能开销远低于监听scroll事件,尤其适合无限滚动场景。
但IntersectionObserver有一个限制:它只能检测元素是否与视口相交,无法提供精确的滚动位置信息。对于需要复杂计算的场景(如动态高度列表),传统的scroll事件方案仍然更合适。
虚拟滚动与无限滚动的本质区别
虚拟滚动和无限滚动经常被混淆,但它们是两个完全不同的技术概念。
无限滚动的核心是延迟加载:初始只加载少量数据,滚动到底部时加载更多。DOM中的元素数量随滚动不断增加。
虚拟滚动的核心是元素替换:DOM中始终只保留可见元素,新元素进入视口时替换旧元素。DOM节点数量保持恒定。
从性能角度看,两者的差异显著:
| 特性 | 无限滚动 | 虚拟滚动 |
|---|---|---|
| DOM节点数量 | 随滚动增长 | 始终恒定 |
| 内存占用 | 持续增加 | 恒定 |
| 向上滚动性能 | 优秀(元素已存在) | 需要重新渲染 |
| 滚动位置记忆 | 自然支持 | 需要额外实现 |
无限滚动的问题在于:用户滚动得越久,页面越卡。一个展示微博的用户,如果连续滚动加载了1000条内容,页面上就存在1000个DOM节点。当用户继续滚动,性能会持续下降。
虚拟滚动没有这个问题:无论用户滚动多久,DOM中始终只有几十个节点。10万条数据和1万条数据的性能表现几乎相同。
实际项目中,两者可以组合使用:虚拟滚动处理当前可见区域,无限滚动处理数据加载。这需要仔细处理两者交界处的状态同步。
表格场景的特殊挑战
虚拟滚动在表格场景中面临独特的挑战:固定表头、固定列、以及二维方向的虚拟化。
固定表头的实现
表格虚拟滚动需要保持表头固定,只虚拟化表体部分。这通常通过分离表头和表体容器来实现:
<div class="table-container">
<table class="header-table">
<thead>...</thead>
</table>
<div class="body-scroller">
<table class="body-table">
<tbody><!-- 虚拟化的行 --></tbody>
</div>
</div>
</div>
关键点在于:表头表格和表体表格需要保持列宽同步。当表体滚动时,表头固定不动;当窗口调整大小时,两者需要同步调整列宽。
列虚拟化
对于超宽表格(如Excel风格的数据网格),还需要对列进行虚拟化。这比行虚拟化更复杂,因为:
- 列宽可能不固定:需要处理动态列宽
- 横向滚动与纵向滚动独立:需要两个独立的虚拟化系统
- 单元格跨列:合并单元格会破坏虚拟化的简单假设
成熟的表格库(如AG Grid、Handsontable)在这些方面投入了大量工程努力。它们的实现通常涉及:
- 双重虚拟化:行和列各自维护可见区域
- 列宽缓存:存储每列的测量宽度
- 单元格回收池:复用DOM元素,避免频繁创建销毁
固定列的实现
财务报表等场景需要左侧固定列(如科目名称),表体可以横向滚动。实现方案:
- 分离容器:固定列和滚动列使用独立的容器
- 同步滚动:两个容器的纵向滚动需要同步
- 高度对齐:固定列和滚动列的行高必须完全一致
这个实现非常脆弱:任何像素级别的偏差都会导致行对齐错位。CSS的position: sticky提供了一种简化方案,但在复杂表格场景中可能失效。
框架生态与选型
虚拟滚动已经是一项成熟技术,主流框架都有成熟的库支持。
React生态
react-window是目前最流行的React虚拟滚动库,由React核心团队成员Brian Vaughn开发。它的特点:
- 极小的包体积(约6KB gzip)
- 支持固定高度和动态高度
- 提供List和Grid两种组件
- API设计简洁,易于集成
TanStack Virtual是后起之秀,提供更灵活的API:
- 框架无关的设计(支持React、Vue、Svelte)
- 支持网格布局和瀑布流
- 更好的TypeScript支持
- 活跃的社区维护
Vue生态
vue-virtual-scroller是Vue的标杆实现:
- 提供RecycleScroller和DynamicScroller两种组件
- 支持动态高度
- 与Vue的响应式系统深度集成
Angular生态
Angular CDK内置了虚拟滚动支持:
- 无需额外依赖
- 与Angular模板系统深度集成
- 支持固定高度和动态高度策略
选型建议
选择虚拟滚动库时,考虑以下因素:
- 数据规模:万级数据,任何库都能胜任;百万级数据,需要关注库的算法效率
- 高度确定性:固定高度用简化版本,动态高度选择专门优化的库
- 框架集成:优先选择与所用框架深度集成的库
- 特殊需求:网格、表格、瀑布流等场景需要选择专门支持的库
如果项目需求简单,从零实现一个基础版本也是可行的——核心代码不超过100行。这能让你完全控制行为,避免第三方库的潜在问题。
不可忽视的边界情况
虚拟滚动不是银弹,它会带来一些需要特别处理的问题。
浏览器搜索失效
用户使用Ctrl+F在页面中搜索文本时,浏览器只能搜索当前DOM中的内容。虚拟滚动意味着大部分内容不在DOM中,搜索会失败。
解决方案是实现自定义搜索功能:在数据源中搜索,然后滚动到匹配项的位置。这需要额外的开发成本,但能提供更好的用户体验。
无障碍访问
屏幕阅读器依赖DOM结构来理解页面内容。虚拟滚动会动态移除DOM节点,可能导致屏幕阅读器丢失上下文。
缓解措施:
<div role="list" aria-setsize="10000">
<!-- 虚拟化的列表项 -->
<div role="listitem" aria-posinset="1">...</div>
<div role="listitem" aria-posinset="2">...</div>
</div>
aria-setsize告知辅助技术列表的总大小,aria-posinset告知当前项的位置。
滚动位置记忆
用户导航到详情页后返回列表,期望看到之前的位置。传统列表通过浏览器历史状态自然支持,虚拟滚动需要显式实现:
// 离开页面时保存
sessionStorage.setItem('scrollPosition', scrollTop);
// 返回页面时恢复
const savedPosition = sessionStorage.getItem('scrollPosition');
if (savedPosition) {
scrollToPosition(parseFloat(savedPosition));
}
技术演进与未来
虚拟滚动技术在过去十年中持续演进。从早期简单的固定高度实现,到今天支持动态高度、网格布局、瀑布流的成熟方案。
值得关注的发展方向:
CSS原生的内容可见性:content-visibility: auto属性让浏览器可以跳过离屏内容的渲染工作。这是一个轻量级的优化方案,适合中等规模的数据列表,但不适用于真正的超大数据集。
Web Worker辅助计算:将索引计算、高度测量等CPU密集型任务移至Web Worker,进一步释放主线程。
GPU加速的滚动:利用WebGPU实现更流畅的滚动动画,尤其是带有复杂视觉效果的场景。
虚拟滚动的核心思想——只渲染用户能看到的内容——已经成为前端性能优化的基本原则之一。理解其技术本质,不仅能帮助你正确使用现有库,还能在面对新场景时做出正确的架构决策。
当你的列表超过几百项,当滚动开始变得迟钝,当用户抱怨页面卡顿——那时,虚拟滚动就不再是可选项,而是必选项。
参考资料
- Chrome Developers. (2024). Avoid an excessive DOM size | Lighthouse
- web.dev. (2023). How large DOM sizes affect interactivity
- web.dev. (2023). Rendering performance
- LogRocket Blog. (2020). Virtual scrolling: Core principles and basic implementation in React
- OpenReplay Blog. (2026). Virtual Scrolling for High-Performance Interfaces
- GitHub. bvaughn/react-window
- TanStack. TanStack Virtual Documentation
- MDN Web Docs. Intersection Observer API
- Chrome Developers. Inside look at modern web browser (part 3)