一个看似简单的计数器,在多线程环境下却能暴露出计算机系统最深层的复杂性。当你写下x++这样的代码时,编译器可能将其重排序,CPU可能延迟写入,缓存一致性协议可能在不同核心间传递失效消息——这些操作并非恶意捣乱,而是现代处理器为了榨取每一分性能而精心设计的优化策略。
C++11引入的六种内存序(memory_order)正是为了在这场性能与正确性的博弈中,给程序员提供精确控制的能力。理解它们,意味着理解当代计算机系统如何处理并发的本质。
从一个失败的双检锁说起
2000年前后,双检锁(Double-Checked Locking)模式在Java和C++社区风靡一时。它试图用一种"聪明"的方式实现线程安全的延迟初始化:
// 经典的错误实现
Singleton* getInstance() {
if (instance == nullptr) { // 第一次检查(无锁)
lock_guard<mutex> lock(mtx);
if (instance == nullptr) { // 第二次检查(有锁)
instance = new Singleton(); // 问题出在这里
}
}
return instance;
}
这个模式看起来完美:只在第一次创建时加锁,后续访问完全无锁。然而,William Pugh等人在《The “Double-Checked Locking is Broken” Declaration》中明确指出,这段代码在多核处理器上会失效。
问题出在instance = new Singleton()这行。它实际上包含三个步骤:
- 分配内存
- 在内存上构造对象
- 将内存地址赋值给
instance
编译器和处理器都可能将步骤2和步骤3重排序。当另一个线程在重排序发生后、对象构造完成前读取instance,它会拿到一个非空但指向未构造对象的指针——随后访问该对象将导致未定义行为。
这正是内存序需要解决的核心问题:当多个线程通过共享内存通信时,如何确保它们对操作顺序达成一致?
六种内存序:一个层次化的设计
C++标准定义了六种内存序,从弱到强依次为:
| 内存序 | 作用 |
|---|---|
memory_order_relaxed |
仅保证原子性,无顺序约束 |
memory_order_consume |
数据依赖顺序(C++26已弃用) |
memory_order_acquire |
获取语义:后续读写不能重排到此操作之前 |
memory_order_release |
释放语义:之前读写不能重排到此操作之后 |
memory_order_acq_rel |
同时具有获取和释放语义 |
memory_order_seq_cst |
顺序一致性:所有线程看到相同顺序 |
这个设计并非随意为之。Herb Sutter在《atomic<> Weapons》演讲中解释道,C++内存模型需要同时满足两个目标:为程序员提供可推理的并发语义,同时允许硬件发挥最大性能。六种内存序正是在这两个目标之间找到的平衡点。
Relaxed:最弱但也最有用
memory_order_relaxed只保证操作的原子性,不施加任何顺序约束。看起来毫无用处,实际上它有着广泛的应用场景——引用计数。
void add_ref() {
ref_count.fetch_add(1, std::memory_order_relaxed);
}
当增加引用计数时,我们只需要原子性——确保计数不会丢失。具体何时被其他线程看到并不重要,因为只要计数大于零,对象就不会被销毁。这正是shared_ptr的实现方式。
值得注意的是,减少引用计数时必须使用acquire-release语义,因为当计数降为零时,需要确保析构函数能看到所有之前的内存操作。
Acquire-Release:生产者-消费者的契约
Acquire和Release必须成对使用,它们共同建立"synchronizes-with"关系——这是C++内存模型的核心概念。
// 生产者线程
data = 42; // A
ready.store(true, memory_order_release); // B
// 消费者线程
while (!ready.load(memory_order_acquire)); // C
assert(data == 42); // D
Release保证:线程中所有在Release操作之前的写操作(A),对执行Acquire操作(C)的线程可见。当消费者读到ready == true时,它必然能看到data == 42。
这个语义来源于锁的实现模式:获取锁是acquire操作,释放锁是release操作。这正是为什么这个内存序以"acquire"和"release"命名。
Seq_cst:当你需要"全局顺序"
memory_order_seq_cst(Sequential Consistency)是最强的内存序,它保证所有线程看到所有原子操作以相同的顺序发生。
什么时候需要这么强的保证?考虑著名的IRIW测试(Independent Reads of Independent Writes):
线程1: x = 1
线程2: y = 1
线程3: r1 = x; r2 = y
线程4: r3 = y; r4 = x
是否可能出现r1 == 1, r2 == 0, r3 == 1, r4 == 0?即线程3看到x先于y变化,而线程4看到y先于x变化?
在ARM和POWER等弱内存模型上,这是完全可能的——不同核心可能以不同顺序观察到写入。但在seq_cst语义下,所有线程必须就写入的全局顺序达成一致。
Dekker互斥算法和Peterson算法正是依赖这个性质才能正确工作。如果你在实现一个需要"谁先谁后"达成共识的同步原语,seq_cst可能是必要的选择。
硬件层面的真相
理解内存序,必须理解它们如何映射到实际的硬件指令。不同架构的差异远比想象中大。
顺序一致性:理想模型

图片来源: research.swtch.com
{kind=link}
在理想的顺序一致性模型中,所有处理器直接连接到同一块共享内存,一次只能服务一个读写请求。没有缓存介入,每个内存访问都直接进入共享内存,强制所有操作形成全局顺序。这是程序员最容易推理的模型,但也是最限制性能的模型。
x86的TSO模型
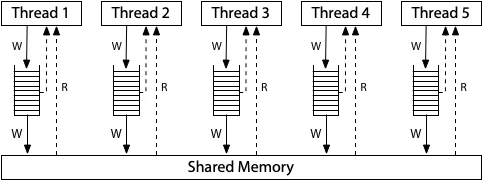
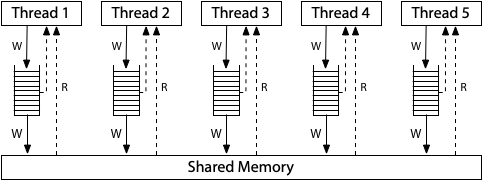
图片来源: research.swtch.com
{kind=link}
x86采用TSO(Total Store Order)模型,它是相当"强"的内存模型。每个核心都有一个FIFO的写缓冲区(Write Buffer),写入先进入缓冲区,稍后才提交到共享内存。
关键约束:
- Store-Store不重排:写入按程序顺序到达内存
- Load-Load不重排:读取按程序顺序执行
- Store-Load可重排:写入可能被延迟,导致后续读取先执行
这意味着在x86上:
- Release操作通常是免费的(已有Store-Store保证)
- Acquire操作通常是免费的(已有Load-Load保证)
- Seq_cst需要
mfence指令,代价约100-300周期
Russ Cox在《Hardware Memory Models》中详细分析了这个设计的历史渊源。有趣的是,Intel直到2007年才正式发布x86-TSO规范——在此之前,程序员只能靠"试错"来理解处理器行为。
ARM的弱内存模型
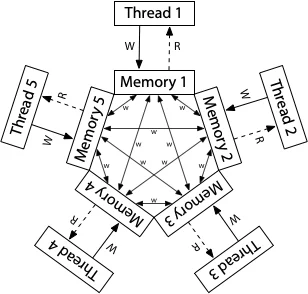
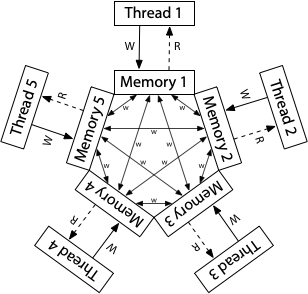
图片来源: research.swtch.com
{kind=link}
ARM采用更激进的优化策略,允许更多重排序:
- Store-Store可重排
- Load-Load可重排
- Store-Load可重排
在这个模型中,每个处理器都有自己的内存副本,写入可以以任意顺序传播到其他处理器。不同线程可能以不同顺序观察到同一组写入。
这意味着同样的C++代码,在x86上可能正确运行,在ARM上却可能崩溃。Apple Silicon Mac的出现让这个问题变得更加普遍——大量x86时代的"正确"代码在M系列芯片上暴露出问题。
在ARM上实现Acquire-Release语义需要dmb(Data Memory Barrier)指令,而Seq_cst需要更强的dmb ish。
编译器优化:另一个隐藏的对手
内存序不仅要对抗硬件重排,还要对抗编译器优化。
int x = 0;
// 线程1
x = 1;
flag.store(true, memory_order_release);
// 编译器可能将 x = 1 移到 store 之后吗?
如果memory_order_release存在,编译器被禁止将之前的写操作移到它之后。这就是为什么非relaxed的原子操作同时也是编译器屏障(Compiler Barrier)。
但如果使用memory_order_relaxed:
int x = 0;
x = 1;
flag.store(true, memory_order_relaxed);
// 编译器完全可以将 x = 1 移到这里!
因为relaxed不提供任何顺序保证。这就是为什么在使用原子操作时,必须明确自己需要什么样的语义——过于乐观可能引入bug,过于保守则损失性能。
实践指南:何时用什么
默认使用seq_cst
如果你不确定,就用memory_order_seq_cst。它是默认值,语义清晰,推理简单。性能损失在现代x86上通常可以接受(主要在Store-Load场景)。
明确场景后降级
只有在确认瓶颈后,才考虑更弱的内存序:
// 场景1:计数器
counter.fetch_add(1, memory_order_relaxed);
// 场景2:发布-订阅
data = produce();
flag.store(true, memory_order_release); // 生产者
if (flag.load(memory_order_acquire)) { // 消费者
consume(data);
}
// 场景3:自旋锁
while (locked.exchange(true, memory_order_acquire)) {
// spin
}
// 临界区
locked.store(false, memory_order_release);
永远不要混合使用不当的内存序
// 危险!
x.store(1, memory_order_release); // 线程1
r = y.load(memory_order_relaxed); // 线程2,可能看不到x的写入
Acquire必须与Release配对使用,混用relaxed会破坏synchronizes-with关系。
性能:量化差异
Travis Downs在《A Concurrency Cost Hierarchy》中给出了具体的性能数据。在Skylake处理器上:
- 无竞争原子操作:约7-10纳秒
- seq_cst额外开销(x86):约20-50纳秒(需要mfence)
- ARM上acq_rel与seq_cst差异:可达2-3倍
更重要的是,内存序影响的是可扩展性。在高竞争场景下,过度使用seq_cst会导致缓存行在核心间频繁传递,严重影响性能。
结语
六种内存序的设计,本质上是将硬件实现的复杂性暴露给程序员,让正确的程序获得最大性能。这是一种权衡——增加了编程难度,但避免了"一刀切"带来的性能损失。
理解内存序,意味着理解:
- 编译器如何优化代码
- CPU如何执行指令
- 缓存如何保持一致性
- 这些层次如何协作(或冲突)
当你下次写下atomic操作时,不妨停下来想一想:我真的需要什么样的保证?硬件需要付出什么代价?答案往往比你想象的更复杂,也更有趣。
参考文献
- Lamport, L. (1979). “How to Make a Multiprocessor Computer That Correctly Executes Multiprocess Programs”. IEEE Transactions on Computers.
- Pugh, W. et al. “The ‘Double-Checked Locking is Broken’ Declaration”. University of Maryland.
- Sutter, H. “atomic<> Weapons” talk, C++ and Beyond 2012.
- Cox, R. (2021). “Hardware Memory Models”. research.swtch.com.
- Sewell, P. et al. (2010). “x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors”.
- cppreference.com. “std::memory_order”.
- Preshing, J. (2012). “Acquire and Release Semantics”.
- Downs, T. (2020). “A Concurrency Cost Hierarchy”.
- Adve, S. & Hill, M. (1990). “Weak Ordering – A New Definition”.
- McKenney, P. “Memory Barriers: a Hardware View for Software Hackers”.