1970年代,当第一个关系数据库系统还在襁褓中时,工程师们就面临一个根本性的矛盾:内存速度快但易失,磁盘可靠但缓慢。一个事务提交后,如何保证数据在断电瞬间不会丢失?如何让数据库在崩溃后能快速恢复到一致状态?这些问题的答案,催生了数据库领域最基础也最精妙的设计——预写日志(Write-Ahead Log,WAL)与检查点(Checkpoint)机制。
一个朴素的两难困境
数据库的核心承诺是 ACID 中的 D——持久性(Durability)。一旦事务提交,数据就必须安全地存储起来,即使服务器机房的供电系统瞬间瘫痪。最直接的实现方式是每次提交都直接写入磁盘,但这会带来灾难性的性能问题:磁盘的随机写入极其缓慢,尤其是传统的机械硬盘,每次寻道都需要数毫秒,而内存操作只需纳秒级。
如果完全在内存中操作,性能确实会大幅提升,但一旦断电,所有未落盘的数据都会永久丢失。这就像把全部积蓄放在家里——取用方便,但一场火灾就能让你一无所有。
WAL 的设计思路提供了一个优雅的折中方案:先写日志,再改数据。每次数据修改前,先把修改操作记录到顺序写入的日志文件中。顺序写入的效率远高于随机写入——磁盘可以像流水线一样连续写入数据,无需频繁寻道。日志落盘后,数据本身的修改可以在内存中异步进行。即使系统崩溃,只要日志完整,就能通过重放日志恢复所有已提交的事务。
但 WAL 本身也带来了新的问题:如果数据库运行了一年,从未将内存中的脏页写入磁盘,崩溃后需要重放一整年的日志。以一个每秒产生 100MB WAL 的高负载数据库为例,一年的日志量约为 3PB,恢复时间可能长达数天甚至数周。这在生产环境中是不可接受的。
检查点机制正是为了解决这个问题而生。
检查点:游戏存档的工程实现
用电子游戏类比,检查点就像游戏中的存档点。没有存档功能的游戏,每次失败都要从头开始;有了存档,失败后只需从最近的存档点继续。数据库的检查点做的正是同样的事情:将内存中的脏页批量写入磁盘,创建一个"已知一致"的状态。崩溃恢复时,只需从这个检查点开始重放 WAL,而非从头开始。
PostgreSQL 官方文档将检查点定义为"事务日志序列中的一个点,在该点上所有数据文件都已经被更新为反映日志中的信息"。检查点完成后,该点之前的 WAL 日志就不再需要用于恢复,可以删除或归档。
检查点的触发条件在不同数据库中有所差异,但通常包括以下几种:
- 时间触发:距离上一个检查点超过指定时间(PostgreSQL 默认 5 分钟,生产环境通常设为 30-60 分钟)
- 日志量触发:WAL 日志量达到阈值(PostgreSQL 的
max_wal_size参数) - 手动触发:执行
CHECKPOINT命令 - 特定操作触发:数据库关闭、备份开始等
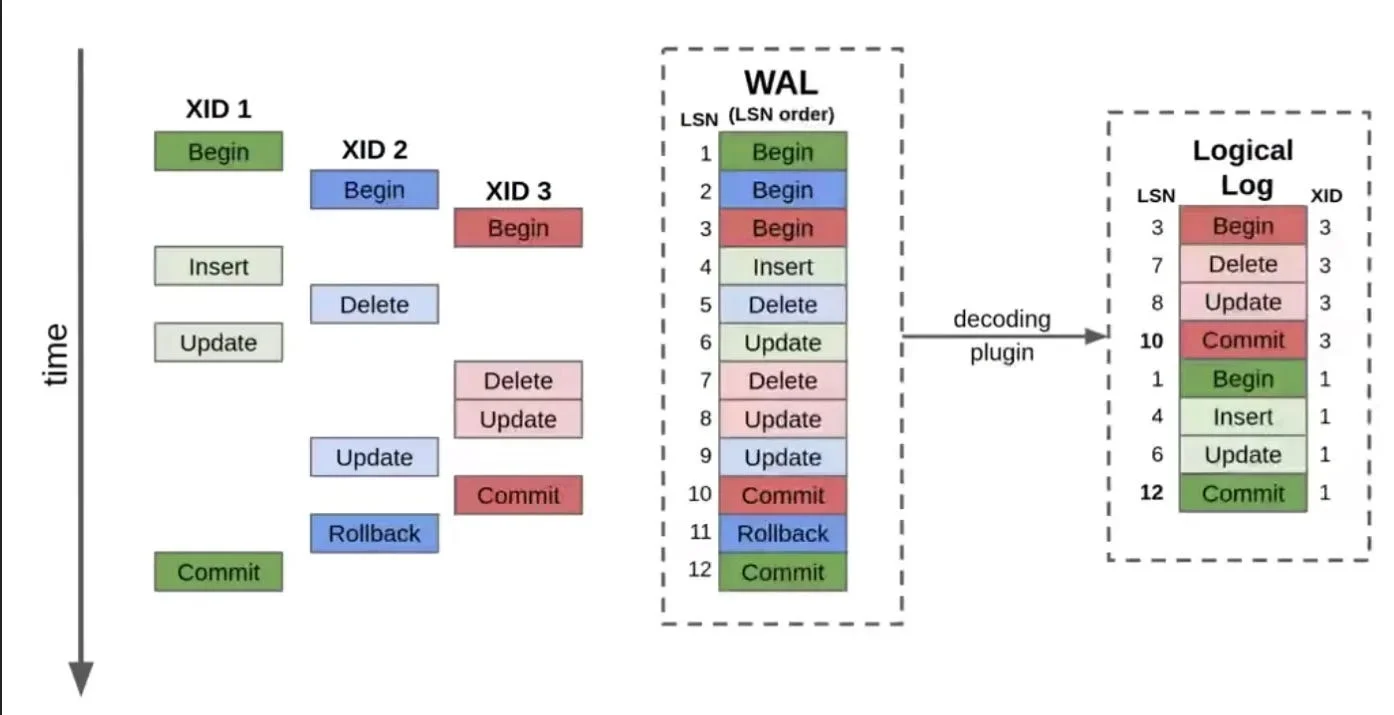
图片来源: Architecture Weekly
上图展示了 PostgreSQL 中 WAL 与检查点的协作关系:事务提交时先写入 WAL,检查点则将脏页刷入磁盘,两者配合确保了数据的持久性与可恢复性。
Sharp 还是 Fuzzy:检查点的两种策略
检查点的设计面临一个核心权衡:检查点期间是否需要暂停事务处理?这引出了两种截然不同的实现策略。
Sharp Checkpoint(精确检查点) 是最简单的实现:暂停所有事务,将所有脏页写入磁盘,完成后再恢复事务处理。这种方式的优点是实现简单,恢复时只需从检查点开始重放日志;缺点是检查点期间系统完全停顿,对于高并发系统,这种停顿可能持续数秒甚至更长,用户体验极差。
早期的 PostgreSQL(8.2 版本之前)就采用这种方式。当检查点发生时,系统需要将所有脏页写入操作系统缓存,然后调用 fsync() 确保数据落盘。假设有 8GB 脏页,即使在 SSD 上,这也需要数秒的 I/O 时间,期间所有用户请求都会被阻塞。
Fuzzy Checkpoint(模糊检查点) 则采用了完全不同的思路:检查点过程中不暂停事务,而是将脏页写入分散在一段时间内完成。PostgreSQL 8.3 引入的"Spread Checkpoint"正是这种思想的体现。
模糊检查点的关键在于流水线化:数据库知道距离下一个检查点触发还有多少时间或日志量,因此可以计算当前应该写出多少脏页。假设检查点间隔为 30 分钟,checkpoint_completion_target 参数设为 0.9,数据库会将脏页写入分散在 27 分钟内完成($30 \times 0.9 = 27$),剩余 3 分钟让操作系统有机会将数据从缓存刷入磁盘。这样,最终的 fsync() 调用开销大大降低,用户几乎感知不到检查点的存在。
MySQL 的 InnoDB 也采用了模糊检查点策略。它通过后台线程持续将脏页刷入磁盘,检查点位置(Checkpoint LSN)则记录在日志文件头部。崩溃恢复时,从这个 LSN 开始重放日志即可。
但模糊检查点也带来了复杂性。Percona 的工程师曾发现一个微妙的性能问题:InnoDB 假设脏页的 LSN 分布是均匀的,但在某些特殊工作负载下(比如大量页面同时被修改),同一个 LSN 范围内可能堆积了大量脏页,导致单次检查点刷写过多样本页面,反而引发性能抖动。
ARIES:工业级恢复算法的巅峰
如果说 WAL 和检查点是数据库恢复的基石,那么 ARIES(Algorithms for Recovery and Isolation Exploiting Semantics)算法就是构筑其上的摩天大楼。1992 年,IBM 的 C. Mohan 等人发表的 ARIES 论文,至今仍被绝大多数关系数据库奉为恢复算法的圣经。
ARIES 的核心哲学是**“重演历史”**(Repeat History)。它的恢复过程分为三个阶段:
分析阶段(Analysis Phase)
从最后一个检查点开始,向前扫描 WAL 日志,构建两个关键数据结构:
- 脏页表(Dirty Page Table, DPT):记录崩溃时内存中哪些页面是脏的,以及每个脏页最早修改的 LSN(称为
recLSN) - 活跃事务表(Active Transaction Table, ATT):记录崩溃时哪些事务还在进行中
分析阶段的目标是确定恢复的起点:不需要从检查点开始重放所有日志,只需要从 DPT 中最小的 recLSN 开始。
重做阶段(Redo Phase)
从分析阶段确定的最小 recLSN 开始,向前重放所有日志记录。关键的是,ARIES 会重放所有操作,包括那些最终会回滚的事务。这看似浪费,实际上是为了保证数据库状态与崩溃瞬间完全一致。
重做的条件检查很精细:只有当页面的 pageLSN(页面最后修改的 LSN)小于日志记录的 LSN,且该页面在 DPT 中时,才执行重做。这避免了不必要的 I/O。
撤销阶段(Undo Phase)
最后,反向扫描日志,回滚所有未提交事务的操作。每回滚一个操作,就写入一个补偿日志记录(Compensation Log Record, CLR),记录这次撤销动作。如果恢复过程中再次崩溃,CLR 可以防止重复撤销。
ARIES 设计的精妙之处在于:它支持 STEAL/NO-FORCE 缓冲策略——允许将未提交事务的修改写入磁盘(STEAL),也不要求提交时必须将所有修改写入磁盘(NO-FORCE)。这是性能最优的策略,但恢复逻辑也最复杂。ARIES 通过精巧的 LSN 追踪机制,完美解决了这个复杂性。
$$\text{WAL 协议约束: } \text{pageLSN}(P) \leq \text{flushedLSN} \Rightarrow \text{可以安全地写出页面 } P$$上述公式表达了 WAL 的核心约束:只有当一个页面最后一次修改的 LSN 小于等于已刷入磁盘的日志 LSN 时,该页面才能安全地写入磁盘。这确保了恢复时总能找到必要的日志来重建页面状态。
不同数据库的检查点实现
虽然 ARIES 提供了理论框架,但不同数据库在实现上各有取舍。
PostgreSQL:以配置灵活性见长
PostgreSQL 的检查点配置参数丰富,允许 DBA 在恢复时间和运行时性能之间精细权衡:
checkpoint_timeout:检查点间隔时间,默认 5 分钟,生产环境通常设为 30-60 分钟max_wal_size:WAL 日志总量软限制,默认 1GB,高负载系统可能需要 10GB 以上checkpoint_completion_target:检查点完成时间占间隔的比例,默认 0.9(PostgreSQL 14 之前为 0.5)checkpoint_flush_after:每写入多少数据后调用 fsync,默认 256KB
一个容易被忽视的性能因素是全页写入(Full Page Writes)。PostgreSQL 默认开启此功能,每个页面在检查点后首次被修改时,会将整个 8KB 页面写入 WAL,而非仅写入修改的差量。这是为了防止"部分写入"(Torn Page)问题:如果 8KB 页面写入过程中断电,可能只有前 4KB 成功写入,导致页面损坏。全页写入虽然会增加 WAL 量,但确保了恢复时总能找到一个完整的好页面。
全页写入带来的 WAL 写放大在高负载系统中可能非常显著。使用 UUID 作为主键的表,每次插入都可能触及不同的索引页面,导致大量全页写入;而使用自增主键(BIGSERIAL)则能利用局部性,减少全页写入次数。测试表明,同样的写入负载,UUID 主键可能产生 40GB WAL,而 BIGSERIAL 只需 2GB——差异主要来自全页写入。
MySQL InnoDB:以自适应刷新为特色
InnoDB 的检查点机制与 PostgreSQL 有几个关键区别:
首先,InnoDB 使用**重做日志(Redo Log)**而非 WAL 文件,日志以循环方式写入固定大小的文件组。这意味着当日志空间紧张时,必须推进检查点以释放空间。
其次,InnoDB 的检查点推进是自适应的。后台线程会根据脏页比例和重做日志使用情况,动态调整刷页速度。当脏页超过缓冲池的 75% 时,会触发更激进的刷页策略。
InnoDB 的 LSN(Log Sequence Number)机制也值得关注。每个数据页面都记录了最后修改的 LSN,检查点 LSN 则是当前所有脏页中最小的 pageLSN。崩溃恢复时,只需从检查点 LSN 开始重放日志。
SQLite:轻量级的 WAL 实现
SQLite 的 WAL 机制更简单,但同样有效。它将 WAL 文件作为独立的 -wal 文件存储,检查点操作将 WAL 中的页面复制回主数据库文件。
SQLite 提供了四种检查点模式:
- PASSIVE:不阻塞其他连接,但如果有活跃读取者,检查点可能无法完成
- FULL:等待所有读取者完成后执行完整检查点
- RESTART:与 FULL 类似,但完成后会阻止新的写入者
- TRUNCATE:与 RESTART 类似,但会截断 WAL 文件到零长度
默认情况下,SQLite 在 WAL 文件达到 1000 页(约 4MB)时自动执行 PASSIVE 检查点。对于嵌入式场景,这种设计在简单性和性能之间取得了良好平衡。
性能权衡:没有免费的午餐
检查点配置本质上是在运行时性能与恢复时间之间权衡。检查点越频繁,恢复越快,但运行时的 I/O 开销越大;检查点越稀疏,运行性能越好,但崩溃后恢复时间越长。
考虑一个具体的例子:假设数据库每秒产生 100MB WAL,如果检查点间隔设为 5 分钟,则崩溃后最多需要重放 30GB 日志;如果间隔设为 30 分钟,则需要重放 180GB。假设日志重放速度为 500MB/s,前者恢复需要约 1 分钟,后者需要 6 分钟。
但更稀疏的检查点带来的好处是减少全页写入。由于全页写入只在检查点后首次修改页面时发生,较长的检查点间隔意味着每个页面在间隔内被修改多次也只会产生一次全页写入。测试表明,将 checkpoint_timeout 从 5 分钟增加到 30 分钟,可能将 WAL 量减少 30-50%。
PostgreSQL 15 引入的 recovery_prefetch 参数提供了一个折中方案:在恢复时预取即将需要的页面,利用现代存储设备的并发 I/O 能力,可能将恢复速度提升 2-3 倍。
实践建议
对于生产环境的数据库,以下是一些通用的检查点调优建议:
评估 WAL 产生速度:使用 pg_current_wal_lsn() 函数测量系统在典型负载下的 WAL 产生速度,据此设置 max_wal_size。例如,如果 30 分钟产生 10GB WAL,则 max_wal_size 应设为至少 20GB(覆盖 2 个检查点周期)。
监控检查点频率:通过 pg_stat_bgwriter 视图监控检查点统计信息。如果 checkpoints_timed 远小于 checkpoints_req,说明检查点主要由 WAL 量触发而非时间触发,需要增加 max_wal_size。
关注 I/O 抖动:如果用户报告周期性的延迟峰值,检查是否与检查点时间吻合。增加 checkpoint_completion_target(最高到 0.9)可以让检查点更平滑。
考虑副本策略:对于高可用要求,比起依赖快速恢复,更实际的方案是建立流复制副本。主库崩溃时,几秒钟内就能切换到副本,远快于任何恢复过程。
结语
WAL 和检查点机制是数据库可靠性保障的基石,其设计体现了工程智慧的精髓——在性能与可靠性、复杂性与正确性之间找到最优平衡。从 1970年代的 System R 到今天的 PostgreSQL 17,这些机制经历了五十年的演进,但核心思想从未改变:先记录,后执行;定期存档,快速恢复。
理解这些机制不仅能帮助 DBA 更好地调优数据库,也能让开发者在设计应用时做出更明智的决策。下次当你看到数据库配置文件中的 checkpoint_timeout 或 max_wal_size 参数时,希望你能想起这背后五十年的技术演进和无数工程师的智慧结晶。
参考资料
- Mohan, C., et al. “ARIES: A Transaction Recovery Method Supporting Fine-Granularity Locking and Partial Rollbacks Using Write-Ahead Logging.” ACM TODS, 1992.
- PostgreSQL Documentation. “Write-Ahead Logging (WAL).” https://www.postgresql.org/docs/current/wal-intro.html
- SQLite Documentation. “Write-Ahead Logging.” https://sqlite.org/wal.html
- EDB Blog. “Basics of Tuning Checkpoints.” https://www.enterprisedb.com/blog/basics-tuning-checkpoints
- EDB Blog. “On the Impact of Full-Page Writes.” https://www.enterprisedb.com/blog/impact-full-page-writes
- Percona Blog. “Innodb Fuzzy Checkpointing Woes.” https://www.percona.com/blog/innodb-fuzzy-checkpointing-woes/
- MySQL Reference Manual. “InnoDB Redo Log.” https://dev.mysql.com/doc/refman/8.2/en/innodb-redo-log.html
- Architecture Weekly. “The Write-Ahead Log: A Foundation for Reliability in Databases.” https://www.architecture-weekly.com/p/the-write-ahead-log-a-foundation
- Sookocheff. “Write-ahead Logging and the ARIES Crash Recovery Algorithm.” https://sookocheff.com/post/databases/write-ahead-logging/
- CMU 15-445/645 Database Course Notes. “Database Logging and Recovery.” https://15445.courses.cs.cmu.edu/
- Pigsty. “WAL与检查点概述.” https://pigsty.cc/blog/kernel/wal-and-checkpoint/