2016年,一个初创团队决定采用事件溯源架构来构建他们的电商系统。两年后,当被问及这个决策时,技术负责人的回答让人深思:“如果你问我是否后悔选择事件溯源,我的回答是:不后悔。但如果让我重新选择,我会先用CRUD。”
这不是一个孤立的案例。从Martin Fowler在2005年首次形式化事件溯源的概念,到Greg Young在2007年进一步推广并创立EventStoreDB,再到今天,事件溯源始终是一个充满争议的架构选择。支持者认为它是构建复杂业务系统的万能解法,反对者则认为它是过度设计的典型代表。
真相往往介于两者之间。
两种持久化范式的本质区别
理解事件溯源的第一步,是理解它与CRUD的根本差异。这不仅仅是技术实现的不同,更是思维方式的转变。
在传统的CRUD模式中,我们关注的是"状态"。当用户修改银行账户余额时,系统会执行一条UPDATE语句,将余额从1000元覆盖为800元。旧的值(1000元)从此消失,取而代之的是新的值(800元)。数据库只保留当前状态,历史被丢弃。
事件溯源则完全不同。它不存储"状态",而是存储"导致状态变化的事件"。同样的场景,事件溯源会记录一个"转账支出200元"的事件。账户的当前余额不是直接存储的,而是通过回放所有历史事件计算得出:开户时存入1000元,然后转账支出200元,最终余额为800元。
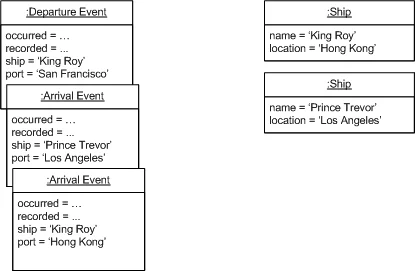
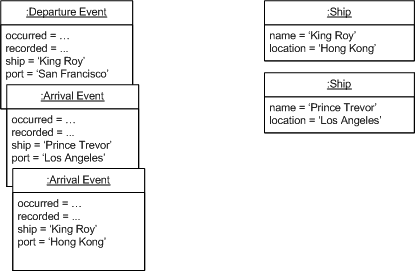
Martin Fowler在他2005年的文章中用一个简洁的图示说明了这个区别:
图片来源: martinfowler.com
{kind=link}
左图展示了CRUD模式下只保留最终状态,右图则展示了事件溯源模式下保留完整的事件日志。这个看似简单的差异,却带来了深远的影响。
事件溯源的真正价值
完整的审计跟踪
金融行业对事件溯源的青睐并非偶然。当一个交易系统需要回答"为什么这个账户在2023年3月15日的余额是X元"时,传统CRUD系统往往束手无策。而事件溯源系统可以轻松地回放历史事件,展示每一步状态变化的因果关系。
EventStoreDB的创始人Greg Young曾指出,事件溯源提供的是"100%可靠的审计日志"。这不是附加功能,而是架构的核心特性。在传统系统中,审计日志通常是事后补充的,可能遗漏关键信息。而在事件溯源系统中,事件本身就是系统状态的真实来源(Source of Truth),不可能遗漏任何状态变化。
时间旅行调试
“你能复现那个生产环境的bug吗?“这是每个开发者都听过的问题。在传统系统中,复现生产环境bug往往需要猜测:当时的数据是什么?用户做了什么操作?系统处于什么状态?
事件溯源改变了这个困境。通过回放事件日志,开发者可以精确地重建任意时间点的系统状态。更有趣的是,这种能力不局限于调试——它为并行模型(Parallel Models)和回溯事件(Retroactive Events)等高级模式提供了基础。Martin Fowler在文章中提到,版本控制系统(如Git)就是事件溯源的典型应用,我们可以通过回放提交历史来重建任意时间点的代码状态。
从历史数据中获取新洞察
这是事件溯源最被低估的优势。当业务需求变化时,传统系统往往无法回答新问题,因为历史数据已经被覆盖。而事件溯源系统保存了所有原始事件,可以在不修改原有数据模型的情况下,通过创建新的投影(Projection)来回答新问题。
一个经典的例子是用户行为分析。在传统系统中,如果要分析"过去一年用户行为模式的变化”,往往需要重新设计数据模型。而事件溯源系统只需要创建一个新的投影,重放历史事件即可。
原子性保证
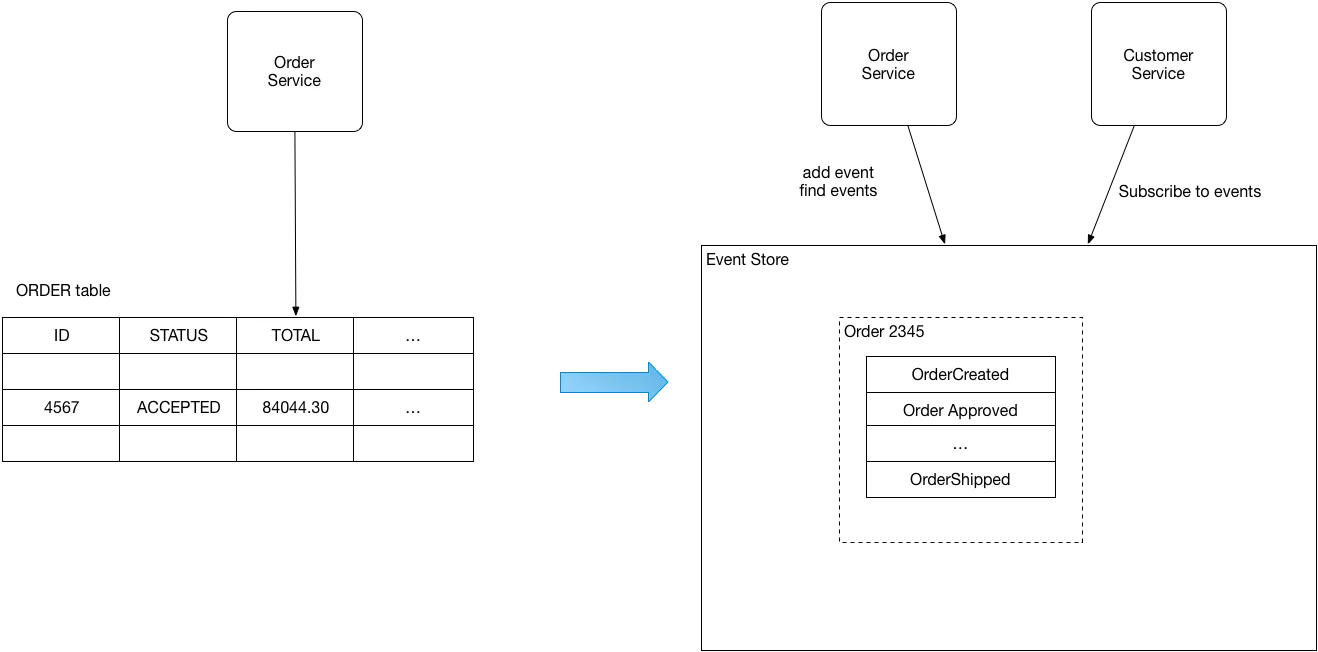
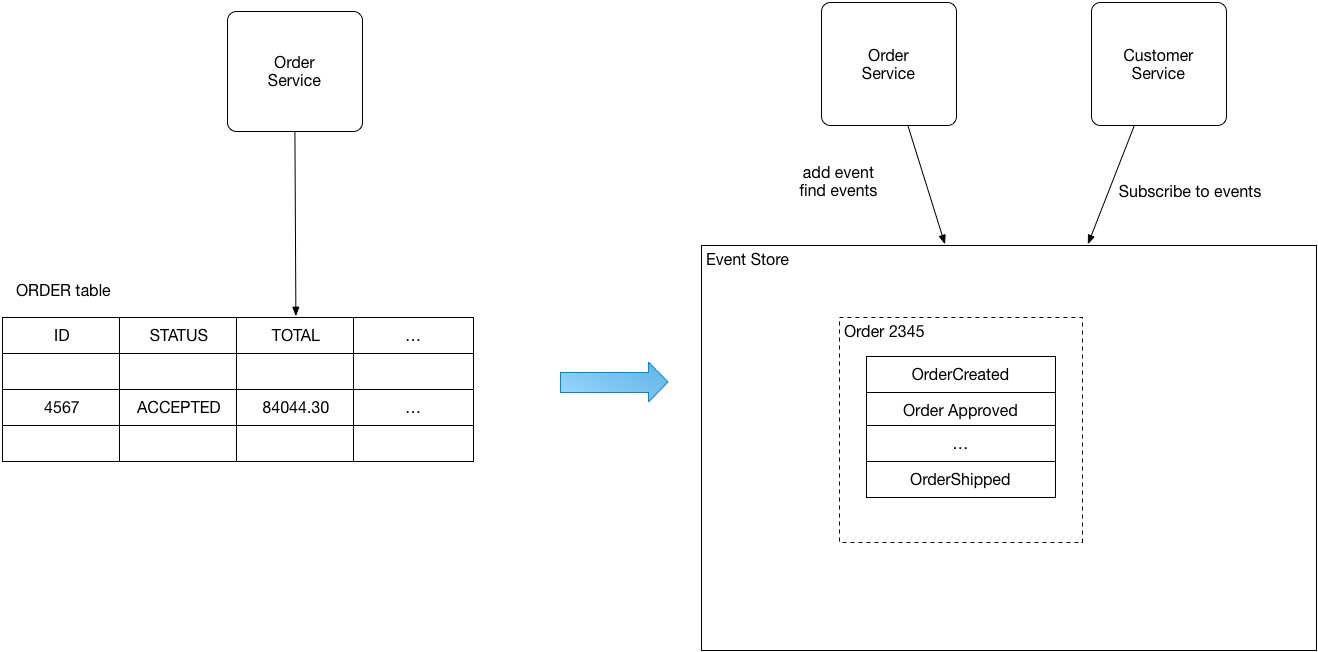
在分布式系统中,同时更新数据库和发送消息是一个经典难题。传统方案需要依赖两阶段提交(2PC),但数据库和消息队列往往不支持,而且2PC会严重影响性能。
事件溯源巧妙地解决了这个问题。Microservices.io的创始人Chris Richardson指出,事件溯源将事件存储作为唯一的真实来源,事件存储同时承担数据库和消息队列的角色。保存一个事件既是数据库操作,也是消息发布,天然具有原子性。
图片来源: microservices.io
{kind=link}
隐性成本:为什么90%的系统不需要
如果事件溯源这么好,为什么Greg Young本人会说"事件溯源被过度使用了”?答案在于它的隐性成本。
事件版本控制的噩梦
这是事件溯源最棘手的问题。当业务需求变化时,事件的结构也需要变化。但在事件溯源系统中,你不能简单地删除旧事件或修改事件结构——因为历史事件是不可变的。
假设你的系统记录了"用户注册"事件,最初包含用户名和密码。后来需求变化,需要增加邮箱字段。传统系统只需要执行一条ALTER TABLE语句,然后更新现有记录。但在事件溯源系统中,你需要处理三种版本的事件:旧版本(只有用户名和密码)、新版本(包含邮箱)、以及迁移过程中的过渡版本。
常见的解决方案包括:
- 向上转型(Upcasting):在读取旧事件时,动态转换为新格式
- 弱模式(Weak Schema):事件使用灵活的数据格式(如JSON),允许缺失字段
- 多版本共存:系统同时支持多个版本的事件处理逻辑
每种方案都有其复杂性,而且随着系统演进,这种复杂性会不断累积。
存储开销
存储所有历史事件意味着存储需求会随时间线性增长。一个简单的订单系统,如果记录每个状态变化事件,五年后的事件数量可能是传统系统记录数量的十倍甚至更多。
这不仅仅是存储成本的问题。更多的存储意味着更长的启动时间(需要重放更多事件)、更慢的查询速度、更复杂的备份和恢复策略。虽然快照(Snapshot)技术可以缓解这个问题,但它本身又引入了新的复杂性:何时创建快照?快照如何与事件保持一致?
查询复杂性
“查询所有余额大于1000元的账户”,这在传统系统中是一条简单的SQL语句。但在事件溯源系统中,你需要:
- 为每个账户重放所有事件,计算当前余额
- 过滤出余额大于1000元的账户
这显然效率极低。因此,事件溯源系统几乎总是需要结合CQRS(命令查询职责分离)模式,维护专门的读模型(Read Model)来支持查询。这意味着系统复杂性的倍增:你需要同时维护事件存储和读模型,并处理两者之间的数据同步问题。
最终一致性的代价
当事件溯源与CQRS结合时,读模型和写模型之间的数据一致性成为必须面对的问题。写操作成功后,读模型可能还需要几毫秒甚至几秒才能更新。这对于需要强一致性的业务场景是致命的。
更复杂的是,当读模型与事件存储不同步时,调试变得异常困难。一个开发者在生产环境中调试的真实案例:客户投诉账户余额显示不正确,但重放所有事件后余额是对的。最终发现是读模型的投影逻辑有一个微妙的bug,导致某些事件被错误处理。
学习曲线
这不是一个可以快速掌握的技能。从CRUD思维转向事件溯源思维,需要重新思考数据建模、事务处理、并发控制、错误恢复等几乎所有核心问题。
一个真实的数据:一个有5年Java开发经验的团队,采用事件溯源后,前三个月的生产力下降了约40%。直到六个月后,团队才逐渐适应新的思维模式。
生产环境的真实教训
不要把事件溯源当作默认选择
在Event-Driven.io上,Oskar Dudycz总结了多年的经验:“事件溯源不是你应该默认选择的架构,而是当你真的需要它时才应该选择的架构。”
具体来说,以下场景适合事件溯源:
- 金融和交易系统:需要完整的审计跟踪,每一笔交易都需要可追溯
- 医疗系统:患者的病史记录不可篡改,需要支持时间点查询
- 协作编辑系统:如Google Docs,需要支持冲突解决和历史回溯
- 复杂的业务流程:业务规则经常变化,需要从历史数据中提取新洞察
以下场景不适合事件溯源:
- 简单的CRUD应用:博客、内容管理系统、简单的电商后台
- 高并发的读操作:如果读操作远多于写操作,事件溯源的复杂性得不偿失
- 团队缺乏经验:如果团队对DDD和事件驱动架构不熟悉,学习成本会拖垮项目
- 项目时间紧张:事件溯源需要更长的开发周期
不要全盘事件溯源
一个常见的错误是试图将整个系统都构建在事件溯源之上。这被称为"全盘事件溯源反模式"。
正确的做法是混合架构:将需要审计跟踪和复杂业务逻辑的部分使用事件溯源,其他部分使用传统的CRUD。例如,订单和支付模块使用事件溯源,而用户配置和内容管理使用CRUD。
选择正确的技术栈
事件溯源需要专门的工具支持。选择错误的技术栈会放大事件溯源的复杂性。
常见的选择包括:
- EventStoreDB:Greg Young创建的专用事件存储数据库,专为事件溯源设计
- Axon Server:提供了完整的事件溯源和CQRS支持
- 传统数据库+自定义实现:灵活性最高,但开发成本也最高
Apache Kafka虽然在某些场景下可以作为事件存储使用,但它不是事件溯源的理想选择。Reddit上的一位开发者总结了原因:“Kafka不保证分区之间的顺序,你可能先收到’订单完成’事件,后收到’订单创建’事件。”
一个决策框架
如何判断你的系统是否需要事件溯源?以下是一个简单的决策框架:
第一步:检查业务需求
你的系统是否需要以下能力之一?
- 完整的审计跟踪(金融、医疗、法律)
- 时间点状态查询(重建历史状态)
- 从历史数据中提取新洞察(业务规则经常变化)
- 事件重放和回溯修正(处理错误事件)
如果答案都是"否",继续使用CRUD。
第二步:评估团队能力
你的团队是否具备以下条件?
- 有DDD(领域驱动设计)经验
- 理解事件驱动架构
- 有充足的时间学习新技术
- 能够接受初期生产力下降
如果任何一项是"否",慎重考虑事件溯源。
第三步:评估项目约束
你的项目是否满足以下条件?
- 有足够的开发时间
- 不需要在短时间内交付
- 预算允许额外的技术投资
如果任何一项是"否",暂时不要引入事件溯源。
第四步:考虑混合架构
即使你的系统需要事件溯源,也不必全盘采用。识别出需要事件溯源的核心领域(如订单、支付),其他部分使用CRUD。
写在最后
回到开头那个技术负责人的回答。他为什么不后悔?因为他们的系统确实需要事件溯源——这是一个金融科技平台,每一笔交易都需要完整的审计跟踪,业务规则每天都在变化。
但他为什么会重新选择先用CRUD?因为他们花费了太多时间在事件溯源的基础设施上,而不是业务逻辑。如果先用CRUD快速验证业务假设,等业务稳定后再逐步引入事件溯源,可能会更高效。
这也许是事件溯源最核心的教训:它并非万灵药,而是特定场景下的工具。正确的问题是"我的系统是否需要事件溯源?“而不是"我是否应该使用事件溯源?”
正如Martin Fowler在文章结尾所说:“把每次变更打包成事件是一种并非每个人都适应的接口风格,许多人觉得它很别扭。因此,它不是一个自然的选择,使用它意味着你期望获得某种回报。”
那个回报,应该是业务价值的提升,而不是技术本身。
参考文献
- Fowler, M. (2005). Event Sourcing. martinfowler.com. https://martinfowler.com/eaaDev/EventSourcing.html
- Richardson, C. Pattern: Event sourcing. microservices.io. https://microservices.io/patterns/data/event-sourcing.html
- Dudycz, O. (2021). When not to use Event Sourcing? event-driven.io. https://event-driven.io/en/when_not_to_use_event_sourcing/
- Microsoft Azure Architecture Center. Event Sourcing pattern. https://learn.microsoft.com/en-us/azure/architecture/patterns/event-sourcing
- AWS Prescriptive Guidance. Event sourcing pattern. https://docs.aws.amazon.com/prescriptive-guidance/latest/cloud-design-patterns/event-sourcing.html
- Kurrent (EventStoreDB). Event Sourcing and CQRS. https://www.kurrent.io/blog/event-sourcing-and-cqrs
- RisingStack. Event sourcing vs CRUD. https://blog.risingstack.com/event-sourcing-vs-crud/
- Verraes, M. (2023). EventSourcing Testing Patterns. verraes.net. https://verraes.net/2023/05/eventsourcing-testing-patterns/
- Event-Driven.io. Simple patterns for events schema versioning. https://event-driven.io/en/simple_events_versioning_patterns/
- Baeldung. Better Retries with Exponential Backoff and Jitter. https://www.baeldung.com/resilience4j-backoff-jitter